regress
多重线性回归
语法
说明
示例
加载 carsmall 数据集。确定权重和马力作为预测变量,里程作为响应。
load carsmall x1 = Weight; x2 = Horsepower; % Contains NaN data y = MPG;
计算具有交互效应项的线性模型的回归系数。
X = [ones(size(x1)) x1 x2 x1.*x2];
b = regress(y,X) % Removes NaN datab = 4×1
60.7104
-0.0102
-0.1882
0.0000
对数据和模型绘图。
scatter3(x1,x2,y,'filled') hold on x1fit = min(x1):100:max(x1); x2fit = min(x2):10:max(x2); [X1FIT,X2FIT] = meshgrid(x1fit,x2fit); YFIT = b(1) + b(2)*X1FIT + b(3)*X2FIT + b(4)*X1FIT.*X2FIT; mesh(X1FIT,X2FIT,YFIT) xlabel('Weight') ylabel('Horsepower') zlabel('MPG') view(50,10) hold off

加载 examgrades 数据集。
load examgrades使用最后一次考试分数作为响应数据,前两次考试分数作为预测变量数据。
y = grades(:,5); X = [ones(size(grades(:,1))) grades(:,1:2)];
用 alpha = 0.01 执行多重线性回归。
[~,~,r,rint] = regress(y,X,0.01);
通过计算不包含 0 的残差区间 rint 来诊断离群值。
contain0 = (rint(:,1)<0 & rint(:,2)>0); idx = find(contain0==false)
idx = 2×1
53
54
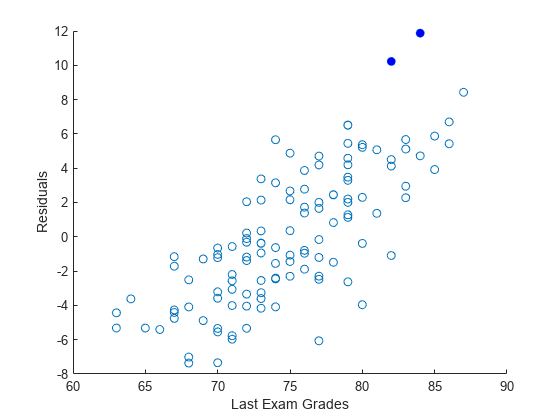
观测值 53 和 54 是可能的离群值。
创建残差的散点图。填充与离群值对应的点。
hold on scatter(y,r) scatter(y(idx),r(idx),'b','filled') xlabel("Last Exam Grades") ylabel("Residuals") hold off
加载 hald 数据集。使用 heat 作为响应变量,使用 ingredients 作为预测变量数据。
load hald y = heat; X1 = ingredients; x1 = ones(size(X1,1),1); X = [x1 X1]; % Includes column of ones
执行多重线性回归并生成模型统计量。
[~,~,~,~,stats] = regress(y,X)
stats = 1×4
0.9824 111.4792 0.0000 5.9830
由于 值 0.9824 接近于 1,p 值 0.0000 小于 0.05 的默认显著性水平,因此响应 y 和 X 中的预测变量之间存在显著的线性回归关系。
输入参数
输出参量
算法
替代功能
在您只需要函数的输出参量以及要在循环中多次重复拟合模型时,regress 非常有用。如果您需要进一步研究拟合后的回归模型,请使用 fitlm 或 stepwiselm 创建线性回归模型对象 LinearModel。LinearModel 对象提供的功能比 regress 更多。
使用
LinearModel的属性来研究拟合线性回归模型。对象属性包括关于系数估计值、摘要统计量、拟合方法和输入数据的信息。使用
LinearModel的对象函数来预测响应以及修改、计算和可视化线性回归模型。与
regress不同,fitlm函数不要求输入数据包含一个由 1 组成的列。由fitlm创建的模型始终包含截距项,除非您使用'Intercept'名称-值对组参量指定不包含它。使用
LinearModel的属性和对象函数,您可以在regress的输出中找到信息。regress的输出LinearModel中的等效值b请查看 Coefficients属性的Estimate列。bint请使用 coefCI函数。r请查看 Residuals属性的Raw列。rint不支持。在这种情况下,请使用 Student 化残差( Residuals属性)和观测值诊断(Diagnostics属性)来查找离群值。stats请查看命令行窗口中的模型显示。您可以使用 anova函数以及在模型属性(MSE和Rsquared)中找到这些统计量。
参考
[1] Chatterjee, S., and A. S. Hadi. “Influential Observations, High Leverage Points, and Outliers in Linear Regression.” Statistical Science. Vol. 1, 1986, pp. 379–416.
扩展功能
版本历史记录
在 R2006a 之前推出