patchEmbeddingLayer
Description
A patch embedding layer maps patches of pixels to vectors. Use this layer in vision transformer neural networks to encode information about patches in images.
Creation
Syntax
Description
layer = patchEmbeddingLayer(patchSize,outputSize)PatchSize and
OutputSize properties.
This feature requires a Deep Learning Toolbox™ license.
layer = patchEmbeddingLayer(patchSize,outputSize,Name=Value)
Properties
Examples
Create a patch embedding layer that embeds patches of size 16 with an output size of 768.
patchSize = 16; embeddingOutputSize = 768; layer = patchEmbeddingLayer(patchSize,embeddingOutputSize)
layer =
PatchEmbeddingLayer with properties:
Name: ''
PatchSize: 16
InputSize: 'auto'
OutputSize: 768
SpatialFlattenMode: 'column-major'
WeightsInitializer: 'glorot'
BiasInitializer: 'zeros'
WeightLearnRateFactor: 1
BiasLearnRateFactor: 1
WeightL2Factor: 1
BiasL2Factor: 1
Learnable Parameters
Weights: []
Bias: []
State Parameters
No properties.
Show all properties
Create a dlnetwork object.
net = dlnetwork;
Specify layers of the network, including a patch embedding layer.
inputSize = [384 384 3];
maxPosition = (inputSize(1)/patchSize)^2 + 1;
numHeads = 4;
numKeyChannels = 4*embeddingOutputSize;
numClasses = 1000;
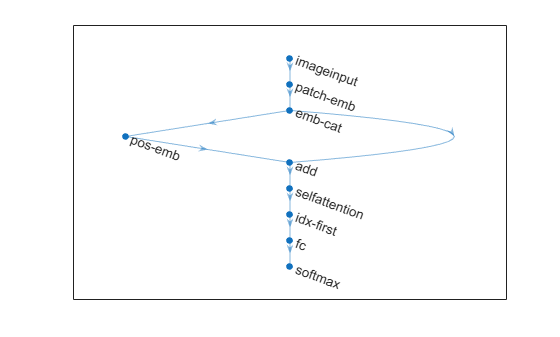
layers = [
imageInputLayer(inputSize)
patchEmbeddingLayer(patchSize,embeddingOutputSize,Name="patch-emb")
embeddingConcatenationLayer(Name="emb-cat")
positionEmbeddingLayer(embeddingOutputSize,maxPosition,Name="pos-emb");
additionLayer(2,Name="add")
selfAttentionLayer(numHeads,numKeyChannels,AttentionMask="causal")
indexing1dLayer(Name="idx-first")
fullyConnectedLayer(numClasses)
softmaxLayer];
net = addLayers(net,layers);Connect the embedding concatenation layer with the "in2" input of the addition layer.
net = connectLayers(net,"emb-cat","add/in2");
View the neural network architecture.
plot(net)
Algorithms
References
[1] Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An Image is Worth 16x16 words: Transformers for Image Recognition at Scale." Preprint, submitted June 3, 2021. https://doi.org/10.48550/arXiv.2010.11929.
[2] Glorot, Xavier, and Yoshua Bengio. "Understanding the Difficulty of Training Deep Feedforward Neural Networks." In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 249–356. Sardinia, Italy: AISTATS, 2010. https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[3] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." In 2015 IEEE International Conference on Computer Vision (ICCV), 1026–34. Santiago, Chile: IEEE, 2015. https://doi.org/10.1109/ICCV.2015.123
Extended Capabilities
Version History
Introduced in R2023bSee Also
visionTransformer | selfAttentionLayer (Deep Learning Toolbox) | embeddingConcatenationLayer (Deep Learning Toolbox) | indexing1dLayer (Deep Learning Toolbox) | trainnet (Deep Learning Toolbox) | trainingOptions (Deep Learning Toolbox) | dlnetwork (Deep Learning Toolbox)
Topics
- Train Vision Transformer Network for Image Classification
- Deep Learning in MATLAB (Deep Learning Toolbox)
- List of Deep Learning Layers (Deep Learning Toolbox)
- Deep Learning Tips and Tricks (Deep Learning Toolbox)
- Data Sets for Deep Learning (Deep Learning Toolbox)