机器学习助力 App 加速药品生产分析
作者 Ram Kumar、Akshay Hatewar 和 Vaidehi Soman,西普拉生产科学与技术部门
制药公司通常会执行严格的检验,以评估所制药品的关键质量属性。一旦发现特定批次存在问题,生产团队就必须尽快查明问题的根本原因,以避免关键药品交付延误和短缺。
由于药品生产中涉及多种原材料和机器以及多个工艺环节,因此准确及时地分析根本原因颇具挑战性。过去,这些团队需要将原材料标签和打印件上的数据手动输入电子表格以供分析,但这种方法速度慢而且容易出错。而且,当时也没有任何一种工具和方法能够一次性分析如此庞大的数据集。
现在,西普拉使用 Web App 进行高级流程分析。该 App 在 MATLAB® 中构建,可以自动收集数据,利用机器学习模型分析数据,并显示结果(图 1)。有了该 App,我们现在找到根本原因只需短短几天,而过去需要长达数周时间。此外,我们可以预测特定批次可能存在的问题,并立即采取纠正措施,而不必苦等长达 14 天才获得成品质量控制检验结果。
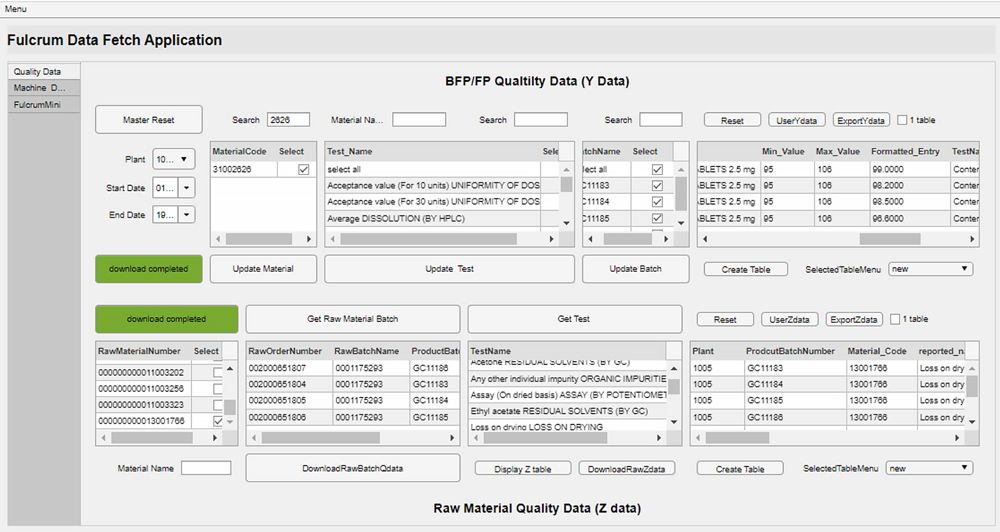
图 1. 西普拉利用在 MATLAB 中构建的 App 进行药品生产分析。
收集和预处理数据
药品生产团队需要分析的数据具有高度异构性,其来源也不尽相同,但是该数据可以分为两大类:关键材料属性 (CMA) 和关键工艺参数 (CPP)。CMA 包括生产过程中所用原材料的特性(例如材料的密度和粒度分布),以及原材料的供应商、使用寿命和保质期。一款典型的药品大约由 20 种原材料制成,每种原材料都有十几种 CMA。CPP 包括在生产过程中的多项设备操作期间捕获的时序测量结果。比如,一项设备操作(如流化床制粒)可能需要 2 到 3 小时甚至更长时间才能完成。在此期间,每分钟都会记录一次工艺参数,例如温度、湿度、空气流经机器的速度,以及过滤器的压差。另一项设备操作(如冻干或冷冻干燥)通常需要 48 小时甚至更长时间才能完成。
我们便向 MathWorks Consulting 寻求了帮助,请他们协助开发一款用于收集和整理这些数据的应用。我们使用 Database Toolbox™ 检索 CMA,并对来自 Microsoft® Azure® 数据仓库和其他数据库的数据进行分批处理。借助 Industrial Communication Toolbox™,我们能够直接从我们工厂的 OPC 服务器访问其他 CPP 数据。数据库资源管理器对于连接到西普拉的各种数据库以及直观地探查数据尤其有用。
我们访问的 CMA 数据相对比较干净,几乎不需要进行预处理。CPP 数据则杂乱得多,特别是压差测量结果。我们使用了 Signal Processing Toolbox™ 中的滤波器,以减少噪声并揭示数据趋势。
构建机器学习模型
一旦我们可以完善的结构表示 CMA 和 CPP 数据,我们接下来要做的就是构建机器学习模型。通过这些模型,我们能够从数百种材料特性和工艺参数中确定哪些材料特性和工艺参数对特定属性的影响最大。从数学角度来说,可以用一个函数表示,即 \(y = f(x_1, x_2, …, x_n)\),其中 \(y\) 是指关键质量属性,而每个 \(x\) 表示一个 CMA 或 CPP 变量。我们需要使用模型确定每个 \(x\) 会对 \(y\) 产生多大的影响。
我们实现了一种依次应用下面三种机器学习方法的算法:主成分分析 (PCA)、偏最小二乘法 (PLS) 和随机森林。x 空间(PCA 图)显示,各批次的原材料特性和/或加工工艺确实不同(图 2)。此外,虽然达标批次和非达标批次的加工方法有多种,但产品总是不达标的。我们使用 x-y 空间(PLS 图)对此进行了确认。在此 x-y 空间图中,所有非达标簇聚集在一起,形成了一个较大的非达标区域。在 PLS 的基础上,我们还应用了随机森林,以了解模型如何准确地将批次归类为达标和非达标。通过对隐变量附加权重可以让某一批次被归类为达标或不达标的原因更好理解。

图 2. 应用 PCA(左)和 PLS(右)得出的结果。绿色圆圈表示达标批次;红色方块表示非达标批次。
我们选择了机器学习而非深度学习,以便能够满足我们的一个重要分析要求,即可解释性。我们需要充分了解所发现的任何生产问题,以彻底解决此类问题,避免未来重蹈覆辙。传统的机器学习能够帮助我们达到这种了解程度,而这是深度学习通常所无法企及的。
打包和部署 Web App
我们的主要目标之一是让分析人人可用。我们想开发一款共享解决方案,它既可供少数专家使用,又能供西普拉的众多用户使用。为此,我们通过 App 设计工具创建了一个简单的界面。我们将该界面与机器学习算法打包在一起,然后通过 MATLAB Web App Server™ 将该包作为 Web App 进行部署。
使用该 App 时,用户需要先选择要分析的产品。然后,该 App 会检索所选产品的相关 CMA 数据,并构建 PCA、PLS 和随机森林模型。之后,该 App 会显示来自这些模型的结果,包括每个变量对关键质量属性的相对贡献,并会突出显示重要因素(图 3)。查看结果后,用户可以决定是否使用这些有明显重要性的因素构建一个简约模型,从而提高模型的准确度。比如,如果初始迭代包含 500 个变量,但显示 300 个变量对结果几乎没有影响,则用户可以忽略这些变量以简化模型,然后重新执行分析。

图 3. 来自 CMA 数据模型的分析结果,包括每个变量的相对贡献。
实时版 App 拟投入试点使用
我们团队目前正在开发该 App 的实时版本,该版本将在今年投入试点使用。此版本将在设备操作过程中实时捕获 OPC 服务器数据,并将其馈送入机器学习模型,然后分析并确定工艺是否在既定控制参数范围内运行。
为什么选择 MATLAB?
在决定使用 MATLAB 执行生产分析前,我们考虑过多种备选方案。我们评估过的一种方案是商业软件包。该软件包成本高昂,我们之所以考虑它,部分原因是它是为制药行业量身定制的,但我们无法根据自身需求对它进行完全定制。
另一种方案是利用 Python® 或类似语言的开源库开发我们自己的解决方案。这个方案也不可行,因为我们需要确保我们构建 App 所用的算法已经过全面验证和测试。此外,我们还需要技术支持来访问各种数据存储中的数据。在 MathWorks Consulting Services 的支持下,凭借 MATLAB,我们能够打造一款完全定制的低成本应用,以在全公司范围内共享。
2022年发布