readStatusRegister
Class: dlhdl.Workflow
Namespace: dlhdl
Description
status = readStatusRegister(workflowObject,registerName)
Input Arguments
Output Arguments
Examples
This example shows how to debug hardware stalls for a deployed ResNet-18 network by reading the debug register status information. You can emulate a hardware stall by sending incorrect data to the double data rate (DDR) memory. You can identify the layer that causes the stall by using the debug status register information.
Prerequisites
Xilinx ZCU102 SoC development kit
Load the Pretrained Network
To load the pretrained network Resnet-18 network, enter:
net = resnet18;
View the layers of the network by using the Deep Network Designer app.
deepNetworkDesigner(net)
Create Target Object
Define the target FPGA board programming interface by using the dlhdl.Target object. Specify that the interface is for a Xilinx® board with an JTAG interface.
hTarget = dlhdl.Target("Xilinx",Interface="JTAG");
This example uses the Xilinx ZCU102 board to deploy the deep learning processor. Use the hdlsetuptoolpath function to add the Xilinx Vivado synthesis tool path to the system path.
hdlsetuptoolpath('ToolName','Xilinx Vivado','ToolPath','C:\Xilinx\Vivado\2023.1\bin\vivado.bat');
Prepare Network for Deployment
Prepare the network for deployment by creating a dlhdl.Workflow object. Specify the network and bitstream name. Ensure that the bitstream name matches the data type and the FPGA board. In this example, the target FPGA board is the Xilinx® Zynq® UltraScale+™ MPSoC ZCU102 board. The bitstream uses single data type.
hW = dlhdl.Workflow(Network = net, Bitstream = "zcu102_single", Target = hTarget)hW =
Workflow with properties:
Network: [1×1 DAGNetwork]
Bitstream: 'zcu102_single'
Target: [1×1 dnnfpga.hardware.TargetJTAG]
Compile the Network
Run the compile method of the dlhdl.Workflow object to compile the network and generate the instructions, weights, and biases for deployment.
dn = compile(hW)
### Compiling network for Deep Learning FPGA prototyping ...
### Targeting FPGA bitstream zcu102_single.
### Optimizing network: Fused 'nnet.cnn.layer.BatchNormalizationLayer' into 'nnet.cnn.layer.Convolution2DLayer'
### Notice: The layer 'data' of type 'ImageInputLayer' is split into an image input layer 'data', an addition layer 'data_norm_add', and a multiplication layer 'data_norm' for hardware normalization.
### The network includes the following layers:
1 'data' Image Input 224×224×3 images with 'zscore' normalization (SW Layer)
2 'conv1' 2-D Convolution 64 7×7×3 convolutions with stride [2 2] and padding [3 3 3 3] (HW Layer)
3 'conv1_relu' ReLU ReLU (HW Layer)
4 'pool1' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [1 1 1 1] (HW Layer)
5 'res2a_branch2a' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
6 'res2a_branch2a_relu' ReLU ReLU (HW Layer)
7 'res2a_branch2b' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
8 'res2a' Addition Element-wise addition of 2 inputs (HW Layer)
9 'res2a_relu' ReLU ReLU (HW Layer)
10 'res2b_branch2a' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
11 'res2b_branch2a_relu' ReLU ReLU (HW Layer)
12 'res2b_branch2b' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
13 'res2b' Addition Element-wise addition of 2 inputs (HW Layer)
14 'res2b_relu' ReLU ReLU (HW Layer)
15 'res3a_branch2a' 2-D Convolution 128 3×3×64 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
16 'res3a_branch2a_relu' ReLU ReLU (HW Layer)
17 'res3a_branch2b' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
18 'res3a_branch1' 2-D Convolution 128 1×1×64 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
19 'res3a' Addition Element-wise addition of 2 inputs (HW Layer)
20 'res3a_relu' ReLU ReLU (HW Layer)
21 'res3b_branch2a' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
22 'res3b_branch2a_relu' ReLU ReLU (HW Layer)
23 'res3b_branch2b' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
24 'res3b' Addition Element-wise addition of 2 inputs (HW Layer)
25 'res3b_relu' ReLU ReLU (HW Layer)
26 'res4a_branch2a' 2-D Convolution 256 3×3×128 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
27 'res4a_branch2a_relu' ReLU ReLU (HW Layer)
28 'res4a_branch2b' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
29 'res4a_branch1' 2-D Convolution 256 1×1×128 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
30 'res4a' Addition Element-wise addition of 2 inputs (HW Layer)
31 'res4a_relu' ReLU ReLU (HW Layer)
32 'res4b_branch2a' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
33 'res4b_branch2a_relu' ReLU ReLU (HW Layer)
34 'res4b_branch2b' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
35 'res4b' Addition Element-wise addition of 2 inputs (HW Layer)
36 'res4b_relu' ReLU ReLU (HW Layer)
37 'res5a_branch2a' 2-D Convolution 512 3×3×256 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
38 'res5a_branch2a_relu' ReLU ReLU (HW Layer)
39 'res5a_branch2b' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
40 'res5a_branch1' 2-D Convolution 512 1×1×256 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
41 'res5a' Addition Element-wise addition of 2 inputs (HW Layer)
42 'res5a_relu' ReLU ReLU (HW Layer)
43 'res5b_branch2a' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
44 'res5b_branch2a_relu' ReLU ReLU (HW Layer)
45 'res5b_branch2b' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
46 'res5b' Addition Element-wise addition of 2 inputs (HW Layer)
47 'res5b_relu' ReLU ReLU (HW Layer)
48 'pool5' 2-D Global Average Pooling 2-D global average pooling (HW Layer)
49 'fc1000' Fully Connected 1000 fully connected layer (HW Layer)
50 'prob' Softmax softmax (SW Layer)
51 'ClassificationLayer_predictions' Classification Output crossentropyex with 'tench' and 999 other classes (SW Layer)
### Notice: The layer 'prob' with type 'nnet.cnn.layer.SoftmaxLayer' is implemented in software.
### Notice: The layer 'ClassificationLayer_predictions' with type 'nnet.cnn.layer.ClassificationOutputLayer' is implemented in software.
### Compiling layer group: conv1>>pool1 ...
### Compiling layer group: conv1>>pool1 ... complete.
### Compiling layer group: res2a_branch2a>>res2a_branch2b ...
### Compiling layer group: res2a_branch2a>>res2a_branch2b ... complete.
### Compiling layer group: res2b_branch2a>>res2b_branch2b ...
### Compiling layer group: res2b_branch2a>>res2b_branch2b ... complete.
### Compiling layer group: res3a_branch1 ...
### Compiling layer group: res3a_branch1 ... complete.
### Compiling layer group: res3a_branch2a>>res3a_branch2b ...
### Compiling layer group: res3a_branch2a>>res3a_branch2b ... complete.
### Compiling layer group: res3b_branch2a>>res3b_branch2b ...
### Compiling layer group: res3b_branch2a>>res3b_branch2b ... complete.
### Compiling layer group: res4a_branch1 ...
### Compiling layer group: res4a_branch1 ... complete.
### Compiling layer group: res4a_branch2a>>res4a_branch2b ...
### Compiling layer group: res4a_branch2a>>res4a_branch2b ... complete.
### Compiling layer group: res4b_branch2a>>res4b_branch2b ...
### Compiling layer group: res4b_branch2a>>res4b_branch2b ... complete.
### Compiling layer group: res5a_branch1 ...
### Compiling layer group: res5a_branch1 ... complete.
### Compiling layer group: res5a_branch2a>>res5a_branch2b ...
### Compiling layer group: res5a_branch2a>>res5a_branch2b ... complete.
### Compiling layer group: res5b_branch2a>>res5b_branch2b ...
### Compiling layer group: res5b_branch2a>>res5b_branch2b ... complete.
### Compiling layer group: pool5 ...
### Compiling layer group: pool5 ... complete.
### Compiling layer group: fc1000 ...
### Compiling layer group: fc1000 ... complete.
### Allocating external memory buffers:
offset_name offset_address allocated_space
_______________________ ______________ ________________
"InputDataOffset" "0x00000000" "23.0 MB"
"OutputResultOffset" "0x016f8000" "120.0 kB"
"SchedulerDataOffset" "0x01716000" "4.1 MB"
"SystemBufferOffset" "0x01b24000" "6.1 MB"
"InstructionDataOffset" "0x02149000" "2.4 MB"
"ConvWeightDataOffset" "0x023ad000" "49.5 MB"
"FCWeightDataOffset" "0x05525000" "2.0 MB"
"EndOffset" "0x0571a000" "Total: 87.1 MB"
### Network compilation complete.
dn = struct with fields:
weights: [1×1 struct]
instructions: [1×1 struct]
registers: [1×1 struct]
syncInstructions: [1×1 struct]
constantData: {{1×2 cell} [1×200704 single]}
ddrInfo: [1×1 struct]
resourceTable: [6×2 table]
Program Bitstream on an FPGA
To deploy the network on the Xilinx® ZCU102 SoC hardware, run the deploy method of the dlhdl.Workflow object. This function uses the output of the compile function to program the FPGA board and download the network weights and biases. The deploy function programs the FPGA device and displays progress messages and the required time to deploy the network.
deploy(hW)
### Programming FPGA Bitstream using JTAG... ### Programming the FPGA bitstream has been completed successfully. ### Loading weights to Conv Processor. ### Conv Weights loaded. Current time is 02-Apr-2024 19:57:38 ### Loading weights to FC Processor. ### 50% finished, current time is 02-Apr-2024 19:57:41. ### FC Weights loaded. Current time is 02-Apr-2024 19:57:44
Emulate a Hardware Stall
To emulate a hardware stall, send incorrect instructions to the DDR memory by using the JTAG AXI Manager. For more information, see Debug and Control Generated HDL IP Core by Using JTAG AXI Manager (HDL Coder).
h = aximanager('AMD')Write incorrect data to the DDR memory location that stores the instructions.
h.writememory('821E1CD8',single(zeros(1,20)));Run Prediction
Get the activations of the network by using the predict method of the dlhdl.Workflow object. Retrieve the prediction results within five seconds, by setting the timeout name-value argument to 5.
inputImg = ones(224,224,3); predict(hW,inputImg,timeout = 5);

Retrieve Debug Register Status
To diagnose the hardware stall, retrieve the debug register status by using the readStatusRegister method of the dlhdl.Workflow object. For more information, see readStatusRegister.
status = readStatusRegister(hW,'ALL')
The function returns the debug register status as a structure with the fields TileInformation, DebugRegisters, and OrderGraph

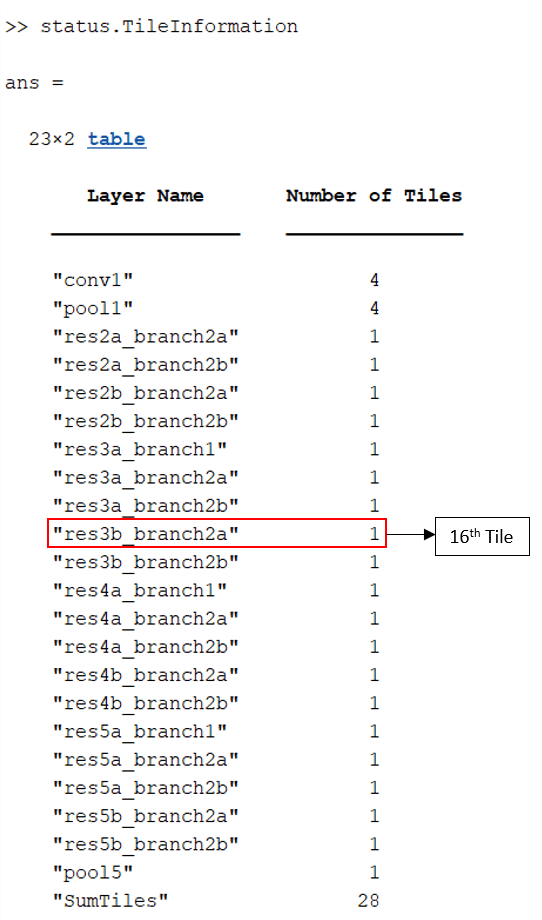
The TileInformation table details the convolutional layers in the network and their associated number of tiles. SumTiles contains the sum of all the tiles in the network. To display the TileInformation, enter:
status.TileInformation

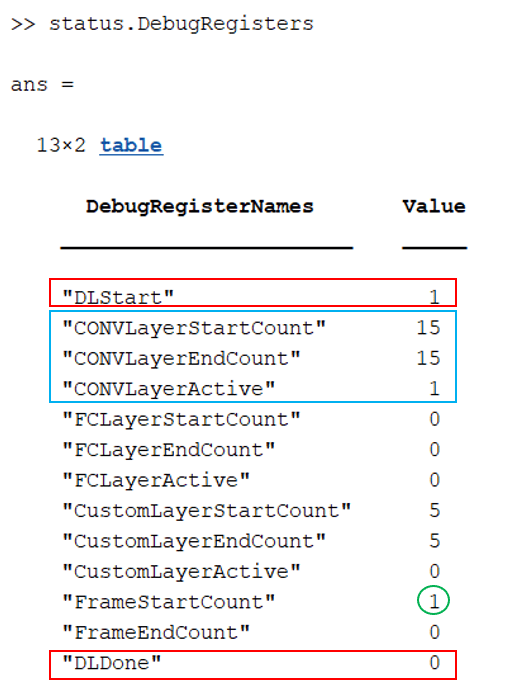
The DebugRegisters table returns the debug register name and value. DLStart and DLDone return information regarding when the deep learning processor started processing data and when the deep learning processor completed processing data. The deep learning processor has three processing modules: conv, fc, and custom. Each of these modules has its own set of status registers. The active registers return a status of 1 when the module processes information. The LayerStartCount and LayerEndCount registers increment whenever they process data. For the conv kernel, the CONVLayerStartCount and CONVLayerEndCount registers increment with every tile processed by a convolutional layer. To access the debug registers, enter:
status.DebugRegisters

To diagnose the hardware stall, you must know the order of the execution of layers inside the deep learning processor. You can view this information in the OrderGraph table. To display the sequence of execution of layers, enter:
status.OrderGraph.Layers

When you examine the debug status register information:
A high
DLStartsignal and a lowDLDonesignal indicate that the deep learning processor has not completed processing the information.A value of 1 in the
FrameStartCountregister indicates that the first frame is currently being processed.A high
CONVLayerActivesignal indicates that theconvkernel module is active and contains the layer responsible for the hardware stall.The
CONVLayersStartCountandCONVLayerEndCountregisters have a value of 15, which indicates that 15 tiles have completed their data processing and the stall occurred in the 16th tile.
To determine the layer that contains the 16th tile, look at the TileInformation table. The res3b_branch2a layer contains the 16th tile.
Alternatively, you can determine the layer that contains the stalled tile by reading information from all the status registers. To read all status registers, enter:
status = hw.readStatusRegister('ALL')
![]()
Version History
Introduced in R2024a
See Also
activations | compile | deploy | getBuildInfo | getStatusRegisterList | predict