augmentedImageDatastore
变换批量以增强图像数据
说明
一个增强图像数据存储可变换为多个批量的训练、验证、测试和预测数据,并可选择性地进行预处理,如调整大小、旋转和翻转。调整图像大小,使其与深度学习网络的输入大小兼容。使用随机化预处理操作增强训练图像数据,以帮助防止网络过拟合和记忆训练图像的具体细节。
要使用增强的图像训练网络,请为 trainnet 函数提供 augmentedImageDatastore。有关详细信息,请参阅预处理图像以进行深度学习。
当您使用增强的图像数据存储作为训练图像的数据源时,数据存储会随机扰动每轮的训练数据,因此每轮使用的数据集略有不同。每轮的训练图像的实际数量不变。经过变换的图像不会存储在内存中。
imageInputLayer使用增强的图像的均值而不是原始数据集的均值来归一化图像。对于增强的第一轮训练,将计算一次此均值。所有其他轮训练都使用相同的均值,因此平均图像在训练期间不会更改。使用增强的图像数据存储对要用于深度学习的图像进行高效预处理,包括调整图像大小。不要使用
ImageDatastore对象的ReadFcn选项。ImageDatastore允许使用预取功能批量读取 JPG 或 PNG 图像文件。如果您将ReadFcn选项设置为自定义函数,则ImageDatastore不会预取,并且通常会明显变慢。
默认情况下,augmentedImageDatastore 仅调整图像大小以适应输出大小。您可以使用 imageDataAugmenter 配置其他图像变换的选项。
创建对象
语法
描述
auimds = augmentedImageDatastore( 使用图像数据存储 outputSize,imds)imds 中的图像创建一个用于分类问题的增强图像数据存储。数据存储将图像大小调整为 outputSize 指定的高度和宽度。
auimds = augmentedImageDatastore( 创建一个用于分类问题和回归问题的增强图像数据存储。数组 outputSize,X,Y)X 包含预测变量,数组 Y 包含分类标签或数值响应。
auimds = augmentedImageDatastore( 创建一个增强图像数据存储,用于预测数组 outputSize,X)X 中图像数据的响应。
auimds = augmentedImageDatastore( 创建一个用于分类问题和回归问题的增强图像数据存储。表 outputSize,tbl)tbl 包含预测变量和响应。
auimds = augmentedImageDatastore( 创建一个用于分类问题和回归问题的增强图像数据存储。表 outputSize,tbl,responseNames)tbl 包含预测变量和响应。responseNames 参量指定 tbl 中的响应变量。
auimds = augmentedImageDatastore(___, 还使用名称-值参量设置可写属性。例如,Name=Value)augmentedImageDatastore([28,28],imds,OutputSizeMode="centercrop") 创建一个从中心裁剪图像的增强图像数据存储。
输入参量
名称-值参数
属性
对象函数
combine | 合并来自多个数据存储的数据 |
hasdata | 确定是否有数据可读取 |
numpartitions | 数据存储分区数 |
partition | 划分数据存储 |
partitionByIndex | Partition augmentedImageDatastore according to
indices |
preview | 预览数据存储中的数据子集 |
read | Read data from augmentedImageDatastore |
readall | 读取数据存储中的所有数据 |
readByIndex | Read data specified by index from
augmentedImageDatastore |
reset | 将数据存储重置为初始状态 |
shuffle | Shuffle data in augmentedImageDatastore |
subset | 创建数据存储或 FileSet 的子集 |
transform | 变换数据存储 |
isPartitionable | 确定数据存储是否可分区 |
isShuffleable | 确定数据存储是否可乱序 |
示例
使用增强的图像数据训练一个卷积神经网络。数据增强有助于防止网络过拟合和记忆训练图像的具体细节。
加载由手写数字的合成图像组成的样本数据。XTrain 是一个 28×28×1×5000 数组,其中:
28 是图像的高度和宽度。
1 是通道数。
5000 是由手写数字组成的合成图像的数目。
labelsTrain 是包含每个观测值的标签的分类向量。
load DigitsDataTrain留出 1000 个图像用于网络验证。
idx = randperm(size(XTrain,4),1000); XValidation = XTrain(:,:,:,idx); XTrain(:,:,:,idx) = []; TValidation = labelsTrain(idx); labelsTrain(idx) = [];
创建一个 imageDataAugmenter 对象,它指定图像增强的预处理选项,如调整大小、旋转、平移和翻转。水平和垂直随机平移图像的最多三个像素,旋转图像角度最多 20 度。
imageAugmenter = imageDataAugmenter( ... 'RandRotation',[-20,20], ... 'RandXTranslation',[-3 3], ... 'RandYTranslation',[-3 3])
imageAugmenter =
imageDataAugmenter with properties:
FillValue: 0
RandXReflection: 0
RandYReflection: 0
RandRotation: [-20 20]
RandScale: [1 1]
RandXScale: [1 1]
RandYScale: [1 1]
RandXShear: [0 0]
RandYShear: [0 0]
RandXTranslation: [-3 3]
RandYTranslation: [-3 3]
创建一个用于网络训练的 augmentedImageDatastore 对象,并指定图像输出大小。在训练期间,数据存储执行图像增强并调整图像大小。数据存储会增强图像,但不会将任何图像保存到内存中。trainnet 会更新网络参数,然后丢弃增强的图像。
imageSize = [28 28 1];
augimds = augmentedImageDatastore(imageSize,XTrain,labelsTrain,'DataAugmentation',imageAugmenter);指定卷积神经网络架构。
layers = [
imageInputLayer(imageSize)
convolution2dLayer(3,8,'Padding','same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,16,'Padding','same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,32,'Padding','same')
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer];指定训练选项。在选项中进行选择需要经验分析。要通过运行试验探索不同训练选项配置,您可以使用Experiment Manager。
opts = trainingOptions('sgdm', ... 'MaxEpochs',15, ... 'Shuffle','every-epoch', ... 'Plots','training-progress', ... 'Metrics','accuracy', ... 'Verbose',false, ... 'ValidationData',{XValidation,TValidation});
使用 trainnet 函数训练神经网络。对于分类,使用交叉熵损失。默认情况下,trainnet 函数使用 GPU(如果有)。在 GPU 上进行训练需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,trainnet 函数使用 CPU。要指定执行环境,请使用 ExecutionEnvironment 训练选项。
net = trainnet(augimds,layers,"crossentropy",opts);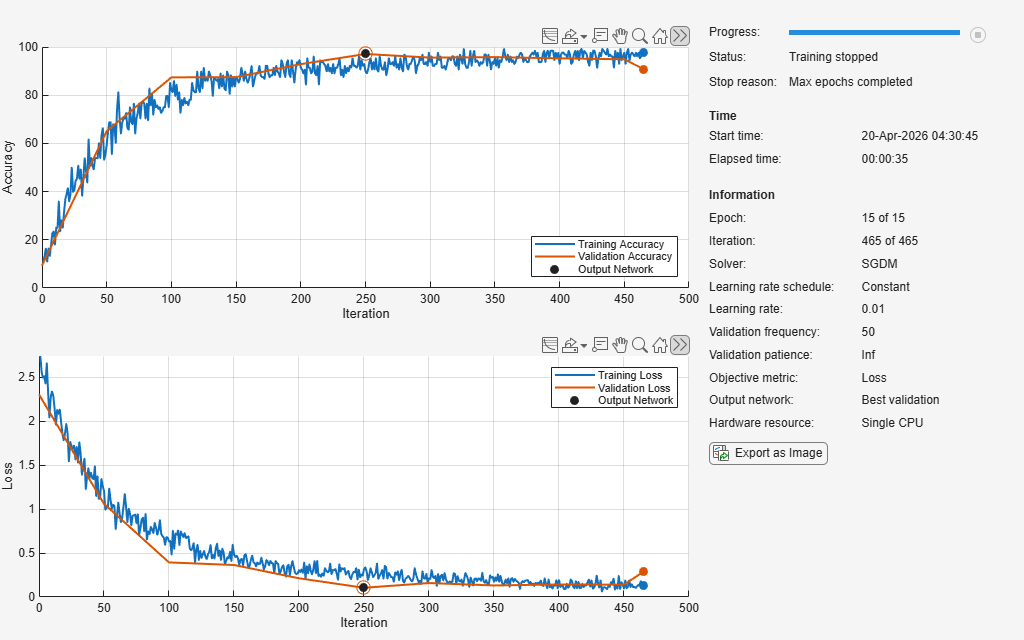
提示
通过使用
imtile函数,您可以在同一图窗中可视化许多变换后的图像。例如,以下代码显示来自名为auimds的增强图像数据存储的一个小批量的变换图像。minibatch = read(auimds); imshow(imtile(minibatch.input))
默认情况下,调整大小是对图像执行的唯一图像预处理操作。通过将
DataAugmentation名称-值参量与imageDataAugmenter对象结合使用,启用其他预处理操作。每次从增强图像数据存储中读取图像时,预处理操作的不同随机组合都会应用于每个图像。要使用不受
augmentedImageDatastore对象支持的增强(如添加噪声、滤波或随机擦除),可使用transform函数创建TransformedDatastore,以应用您定义的自定义变换函数。有关说明如何创建向图像添加椒盐噪声的TransformedDatastore的示例,请参阅为图像到图像的回归准备数据存储。要使用
trainnet函数通过增强的图像来训练多输入网络,可通过transform函数创建TransformedDatastore来增强图像,然后使用combine函数将TransformedDatastore与另一个数据存储合并。有关说明如何对数据存储先进行变换再合并的示例,请参阅使用无法放入内存的序列数据训练网络。
版本历史记录
在 R2018a 中推出