networkDistributionDiscriminator
Syntax
Description
Add-On Required: This feature requires the AI Verification Library for Deep Learning Toolbox add-on.
discriminator = networkDistributionDiscriminator(net,XID,XOOD,method)method.
You can use the discriminator to classify observations as in-distribution (ID) and out-of-distribution (OOD). OOD data refers to data that is sufficiently different from the data you use to train the network, which can cause the network to behave unexpectedly. For more information, see In-Distribution and Out-of-Distribution Data.
The networkDistributionDiscriminator function first finds
distribution confidence scores using the method you specify in method. The
function then finds a threshold that best separates the ID and OOD distribution confidence
scores. You can classify any observation with a score below the threshold as OOD. For more
information about how the function computes the threshold, see Algorithms. You can find the
threshold using a set of ID data, a set of OOD data, or both.
To determine whether new data is ID or OOD, pass discriminator as
an input to the isInNetworkDistribution function.
To find the distribution confidence scores, pass discriminator as
an input to the distributionScores function. For more information about distribution
confidence scores, see Distribution Confidence Scores.
discriminator = networkDistributionDiscriminator(net,XID,[],method)Threshold property of discriminator contains the
threshold such that the discriminator attains a true positive rate greater than the value of
the TruePositiveGoal
name-value argument. For more information, see Algorithms.
discriminator = networkDistributionDiscriminator(net,[],XOOD,method)Threshold property of discriminator contains the
threshold such that the discriminator attains a false positive rate less than the value of
the FalsePositiveGoal
name-value argument. For more information, see Algorithms.
discriminator = networkDistributionDiscriminator(___,Name=Value)
Examples
Load a pretrained classification network.
load("digitsClassificationMLPNetwork.mat");Load ID data. Convert the data to a dlarray object.
XID = digitTrain4DArrayData;
XID = dlarray(XID,"SSCB");Modify the ID training data to create an OOD set.
XOOD = XID*0.3 + 0.1;
Create a discriminator. The function finds the threshold that best separates the two distributions of data by maximizing the true positive rate and minimizing the false positive rate.
method = "baseline";
discriminator = networkDistributionDiscriminator(net,XID,XOOD,method)discriminator =
BaselineDistributionDiscriminator with properties:
Method: "baseline"
Network: [1×1 dlnetwork]
Threshold: 0.9743
Load a pretrained classification network.
load("digitsClassificationMLPNetwork.mat");Load ID data. Convert the data to a dlarray object.
XID = digitTrain4DArrayData;
XID = dlarray(XID,"SSCB");Create a discriminator using only the ID data. Set the method to "energy" with a temperature of 10. Specify the true positive goal as 0.975. To specify the true positive goal, you must specify ID data and not specify the false positive goal.
method = "energy"; discriminator = networkDistributionDiscriminator(net,XID,[],method, ... Temperature=10, ... TruePositiveGoal=0.975)
discriminator =
EnergyDistributionDiscriminator with properties:
Method: "energy"
Network: [1×1 dlnetwork]
Temperature: 10
Threshold: 23.5541
Load a pretrained classification network.
load("digitsClassificationMLPNetwork.mat");Create OOD data. In this example, the OOD data is 1000 images of random noise. Each image is 28-by-28 pixels, the same size as the input to the network. Convert the data to a dlarray object.
XOOD = rand([28 28 1 1000]);
XOOD = dlarray(XOOD,"SSCB");Create a discriminator. Specify the false positive goal as 0.025. To specify the false positive goal, you must specify OOD data and not specify the true positive goal.
method = "baseline"; discriminator = networkDistributionDiscriminator(net,[],XOOD,method, ... FalsePositiveGoal=0.025)
discriminator =
BaselineDistributionDiscriminator with properties:
Method: "baseline"
Network: [1×1 dlnetwork]
Threshold: 0.9998
Load a pretrained regression network.
load("digitsRegressionMLPNetwork.mat")Load ID data. Convert the data to a dlarray object.
XID = digitTrain4DArrayData;
XID = dlarray(XID,"SSCB");Modify the ID training data to create an OOD set.
XOOD = XID*0.3 + 0.1;
Create a discriminator. For regression tasks, set the method to "hbos". When using the HBOS method, you can specify additional options. Set the variance cutoff to 0.0001 and use the penultimate layer to compute the HBOS distribution scores.
method = "hbos"; discriminator = networkDistributionDiscriminator(net,XID,XOOD,method, ... VarianceCutoff=0.0001, ... LayerNames="relu_2")
discriminator =
HBOSDistributionDiscriminator with properties:
Method: "hbos"
Network: [1×1 dlnetwork]
LayerNames: "relu_2"
VarianceCutoff: 1.0000e-04
Threshold: -54.1225
Load a pretrained classification network.
load('digitsClassificationMLPNetwork.mat');Load ID data. Convert the data to a dlarray object and count the number of observations.
XID = digitTrain4DArrayData;
XID = dlarray(XID,"SSCB");
numObservations = size(XID,4);Modify the ID training data to create an OOD set.
XOOD = XID*0.3 + 0.1;
Create a discriminator. The function finds the threshold that best separates the two distributions of data.
method = "baseline";
discriminator = networkDistributionDiscriminator(net,XID,XOOD,method);Test the discriminator on the ID and OOD data using the isInNetworkDistribution function. The isInNetworkDistribution function returns a logical array indicating which observations are ID and which observations are OOD.
Xdata = cat(4,XID,XOOD); trueClass = [true(numObservations,1); false(numObservations,1)]; predictedClass = isInNetworkDistribution(discriminator,Xdata);
Calculate the accuracy for the ID and OOD observations.
accuracy = sum(trueClass == predictedClass)/numel(trueClass)
accuracy = 0.9629
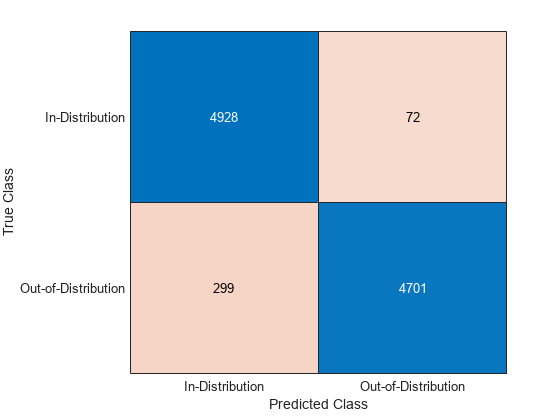
Create a confusion chart for the ID and OOD data.
cm = confusionchart(trueClass,predictedClass);
Display the underlying class labels.
cm.ClassLabels
ans = 2×1 logical array
0
1
Specify the row and column display labels in the same order.
displayLabels = ["OOD" "ID"]; cm.RowDisplayLabels = displayLabels; cm.ColumnDisplayLabels = displayLabels;
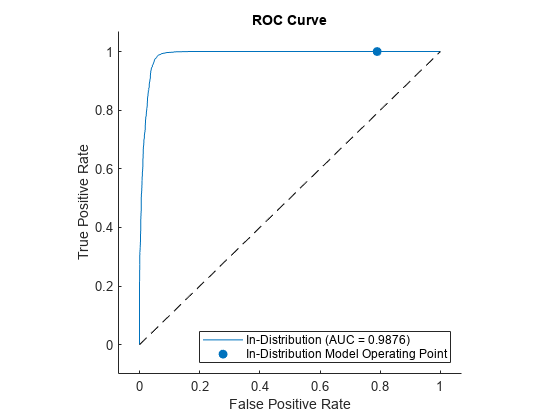
Use the distributionScores function to find the distribution scores for the ID and OOD data.
scores = distributionScores(discriminator,Xdata);
Use rocmetrics to plot a ROC curve to show how well the model is at separating the data into ID and OOD.
rocObj = rocmetrics(trueClass,scores,1); plot(rocObj)
Load a pretrained classification network.
load("digitsClassificationMLPNetwork.mat");Load the digit sample data and create an image datastore. The imageDatastore function automatically labels the images based on folder names.
digitDatasetPath = fullfile(matlabroot,'toolbox','nnet','nndemos', ... 'nndatasets','DigitDataset'); imds = imageDatastore(digitDatasetPath, ... 'IncludeSubfolders',true,'LabelSource','foldernames');
Create the minibatchqueue object.
Specify a mini-batch size of 64.
Preprocess the mini-batches using the
preprocessMiniBatchfunction, listed at the end of this example.Convert the output to a
dlarrayobject.Specify that the output data has format
"SSCB"(spatial, spatial, channel, batch).
mbq = minibatchqueue(imds, ... MiniBatchSize=64, ... MiniBatchFcn=@preprocessMiniBatch, ... OutputAsDlarray=true, ... MiniBatchFormat="SSCB");
Create a discriminator using the minibatchqueue object containing ID data. Set the method to "baseline" and the VerbosityLevel to "detailed".
method = "baseline"; discriminator = networkDistributionDiscriminator(net,mbq,[],method,VerbosityLevel="detailed");
Processing in-distribution data: Computing distribution scores... .......... .......... .......... .......... .......... (50 mini-batches) .......... .......... .......... .......... .......... (100 mini-batches) .......... .......... .......... .......... .......... (150 mini-batches) ....... (157 mini-batches) Done. Computing threshold...Done.
Mini-Batch Preprocessing Function
The preprocessMiniBatch function preprocesses the data using the following steps:
Extract the image data from the incoming cell array and concatenate the data into a numeric array.
Rescale the images to the range
[0 1].
function X = preprocessMiniBatch(dataX) X = cat(4,dataX{1:end}); X = rescale(X,InputMin=0,InputMax=1); end
Input Arguments
Name-Value Arguments
Output Arguments
More About
OOD data detection is a technique for assessing whether the inputs to a network are OOD. For methods that you apply after training, you can construct a discriminator which acts as an additional output of the trained network that classifies an observation as ID or OOD.
The discriminator works by finding a distribution confidence score for an input. You can then specify a threshold. If the score is less than or equal to that threshold, then the input is OOD. Two groups of metrics for computing distribution confidence scores are softmax-based and density-based methods. Softmax-based methods use the softmax layer to compute the scores. Density-based methods use the outputs of layers that you specify to compute the scores. For more information about how to compute distribution confidence scores, see Distribution Confidence Scores.
These images show how a discriminator acts as an additional output of a trained neural network.
Example Data Discriminators
| Example of Softmax-Based Discriminator | Example of Density-Based Discriminator |
|---|---|
|
For more information, see Softmax-Based Methods. |
For more information, see Density-Based Methods. |
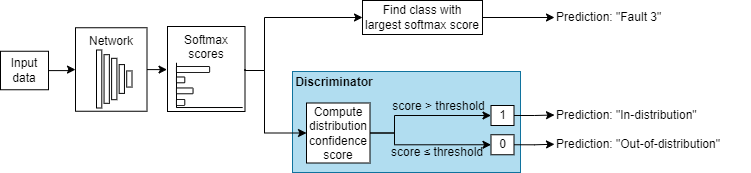
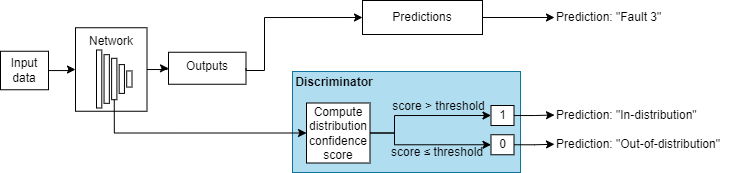
Algorithms
The function creates a discriminator using the trained network. The discriminator behaves as an additional output of the network and classifies an observation as ID or OOD using a threshold. For more information, see OOD Data Detection.
To compute the distribution threshold, the function first computes the distribution
confidence scores using the method that you specify in the method input
argument. For more information, see Distribution Confidence Scores. The software then finds the
threshold that best separates the scores of the ID and OOD data. To find the threshold, the
software optimizes over these values:
True positive goal — Number of ID observations that the discriminator correctly classifies as ID. To optimize for this value, the ID data
XIDmust be nonempty and you must specifyTruePositiveGoal. If you specifyTruePositiveGoalasp, then the software finds the threshold above which the proportion of ID confidence scores isp. This process is equivalent to finding the 100(1-p)-th percentile for the ID confidence scores.False positive goal — Number of OOD observations that the discriminator incorrectly classifies as ID. To optimize for this value, the OOD data
XOODmust be nonempty and you must specifyFalsePositiveGoal. If you specifyFalsePositiveGoalasp, then the software finds the threshold above which the proportion of OOD confidence scores isp. This process is equivalent to finding the 100p-th percentile for the OOD confidence scores.
If you provide ID and OOD data and do not specify TruePositiveGoal or
FalsePositiveGoal,
then the software finds the threshold that maximizes the balanced accuracy . If you provide only ID data, then the software optimizes using only
TruePositiveGoal,
whose default is 0.95. If you provide only OOD data, then the software
optimizes using only FalsePositiveGoal,
whose default is 0.05.
This figure illustrates the different thresholds that the software chooses if you optimize over both the true positive rate and false positive rate, just the true positive rate, or just the false positive rate.
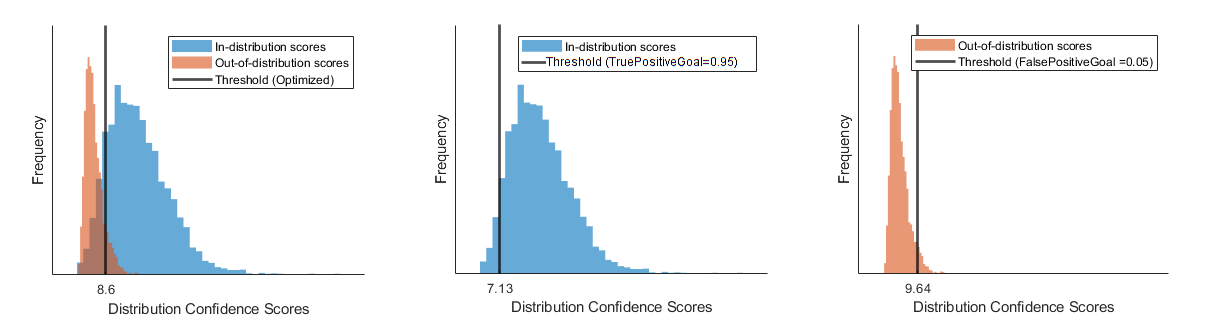
References
[5] Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu, “Generalized Out-of-Distribution Detection: A Survey” August 3, 2022, http://arxiv.org/abs/2110.11334.
[6] Lee, Kimin, Kibok Lee, Honglak Lee, and Jinwoo Shin. “A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks.” arXiv, October 27, 2018. http://arxiv.org/abs/1807.03888.
Extended Capabilities
Version History
Introduced in R2023aSee Also
isInNetworkDistribution | distributionScores | minibatchqueue | coder.loadNetworkDistributionDiscriminator
Topics
- Verification of Neural Networks
- Out-of-Distribution Detection for Deep Neural Networks
- Out-of-Distribution Data Discriminator for YOLO v4 Object Detector
- Out-of-Distribution Detection for LSTM Document Classifier
- Out-of-Distribution Detection for BERT Document Classifier
- Verify Robustness of Deep Learning Neural Network