使用深度学习训练语音命令识别模型
此示例说明如何训练一个深度学习模型来检测音频中是否存在语音命令。此示例使用语音命令数据集 [1] 来训练卷积神经网络,以识别一组命令。
要使用预训练的语音命令识别系统,请参阅Speech Command Recognition Using Deep Learning (Audio Toolbox)。

要快速运行该示例,请将 speedupExample 设置为 true。要运行发布的完整示例,请将 speedupExample 设置为 false。
speedupExample =  false;
false;设置随机种子以实现可再现性。
rng default加载数据
此示例使用 Google Speech Commands Dataset [1]。下载并解压缩数据集。
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","google_speech.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder) dataset = fullfile(dataFolder,"google_speech");
增强数据
网络应不仅能够识别不同发音的单词,而且还能够检测音频输入是静音还是背景噪声。
支持函数 augmentDataset 使用 Google Speech Commands Dataset 的背景文件夹中的长音频文件来创建时长一秒的背景噪声片段。该函数从每个背景噪声文件创建相同数量的背景片段,然后将这些片段拆分到训练和验证文件夹中。
augmentDataset(dataset)
创建训练数据存储
创建一个指向该训练数据集的 audioDatastore (Audio Toolbox)。
ads = audioDatastore(fullfile(dataset,"train"), ... IncludeSubfolders=true, ... FileExtensions=".wav", ... LabelSource="foldernames");
指定您希望模型识别为命令的单词。将所有不是命令或背景噪声的文件标注为 unknown。将非命令单词标注为 unknown 会创建一个单词组,用来逼近除命令之外的所有单词的分布。网络使用该组来学习命令与所有其他单词之间的差异。
为了减少已知单词和未知单词之间的类不平衡并加快处理速度,只在训练集中包括未知单词的一小部分。
使用 subset (Audio Toolbox) 创建一个仅包含命令、背景噪声和未知单词子集的数据存储。计算属于每个类别的示例的数量。
commands = categorical(["yes","no","up","down","left","right","on","off","stop","go"]); background = categorical("background"); isCommand = ismember(ads.Labels,commands); isBackground = ismember(ads.Labels,background); isUnknown = ~(isCommand|isBackground); includeFraction = 0.2; % Fraction of unknowns to include. idx = find(isUnknown); idx = idx(randperm(numel(idx),round((1-includeFraction)*sum(isUnknown)))); isUnknown(idx) = false; ads.Labels(isUnknown) = categorical("unknown"); adsTrain = subset(ads,isCommand|isUnknown|isBackground); adsTrain.Labels = removecats(adsTrain.Labels);
创建验证数据存储
创建一个指向该验证数据集的 audioDatastore (Audio Toolbox)。按照用于创建训练数据存储的相同步骤进行操作。
ads = audioDatastore(fullfile(dataset,"validation"), ... IncludeSubfolders=true, ... FileExtensions=".wav", ... LabelSource="foldernames"); isCommand = ismember(ads.Labels,commands); isBackground = ismember(ads.Labels,background); isUnknown = ~(isCommand|isBackground); includeFraction = 0.2; % Fraction of unknowns to include. idx = find(isUnknown); idx = idx(randperm(numel(idx),round((1-includeFraction)*sum(isUnknown)))); isUnknown(idx) = false; ads.Labels(isUnknown) = categorical("unknown"); adsValidation = subset(ads,isCommand|isUnknown|isBackground); adsValidation.Labels = removecats(adsValidation.Labels);
可视化训练和验证标签分布。
figure(Units="normalized",Position=[0.2,0.2,0.5,0.5]) tiledlayout(2,1) nexttile histogram(adsTrain.Labels) title("Training Label Distribution") ylabel("Number of Observations") grid on nexttile histogram(adsValidation.Labels) title("Validation Label Distribution") ylabel("Number of Observations") grid on
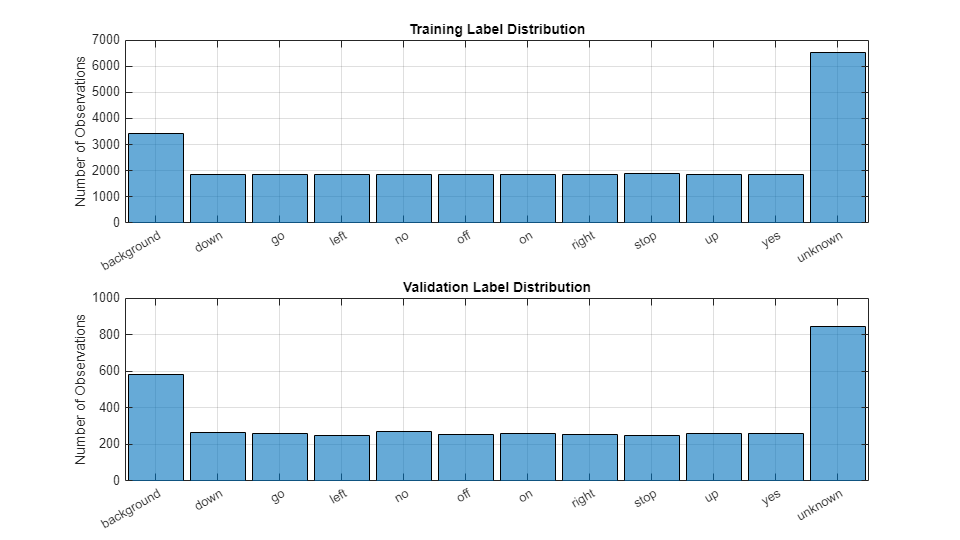
如果需要,通过减少数据集来加快示例速度。
if speedupExample numUniqueLabels = numel(unique(adsTrain.Labels)); %#ok<UNRCH> % Reduce the dataset by a factor of 20 adsTrain = splitEachLabel(adsTrain,round(numel(adsTrain.Files) / numUniqueLabels / 20)); adsValidation = splitEachLabel(adsValidation,round(numel(adsValidation.Files) / numUniqueLabels / 20)); end
准备要训练的数据
为了准备能够高效训练卷积神经网络的数据,请将语音波形转换为基于听觉的频谱图。
为了加快处理速度,您可以在多个工作单元之间分配特征提取。如果您能够访问 Parallel Computing Toolbox™,请启动并行池。
if canUseParallelPool && ~speedupExample useParallel = true; gcp; else useParallel = false; end
提取特征
定义从音频输入提取听觉频谱图的参数。segmentDuration 是每个语音段的持续时间(以秒为单位)。frameDuration 是用于计算频谱的每个帧的持续时间。hopDuration 是每个频谱之间的时间步。numBands 是听觉频谱图中的滤波器的数量。
fs = 16e3; % Known sample rate of the data set.
segmentDuration = 1;
frameDuration = 0.025;
hopDuration = 0.010;
FFTLength = 512;
numBands = 50;
segmentSamples = round(segmentDuration*fs);
frameSamples = round(frameDuration*fs);
hopSamples = round(hopDuration*fs);
overlapSamples = frameSamples - hopSamples;创建一个 audioFeatureExtractor (Audio Toolbox) 对象来执行特征提取。
afe = audioFeatureExtractor( ... SampleRate=fs, ... FFTLength=FFTLength, ... Window=hann(frameSamples,"periodic"), ... OverlapLength=overlapSamples, ... barkSpectrum=true); setExtractorParameters(afe,"barkSpectrum",NumBands=numBands,WindowNormalization=false);
基于 audioDatastore (Audio Toolbox) 定义一系列 transform (Audio Toolbox),以将音频填充到一致的长度,提取特征,然后应用对数。

transform1 = transform(adsTrain,@(x)[zeros(floor((segmentSamples-size(x,1))/2),1);x;zeros(ceil((segmentSamples-size(x,1))/2),1)]);
transform2 = transform(transform1,@(x)extract(afe,x));
transform3 = transform(transform2,@(x){log10(x+1e-6)});使用 readall (Audio Toolbox) 函数从数据存储中读取所有数据。在读取每个文件时,它都会经过变换再返回数据。
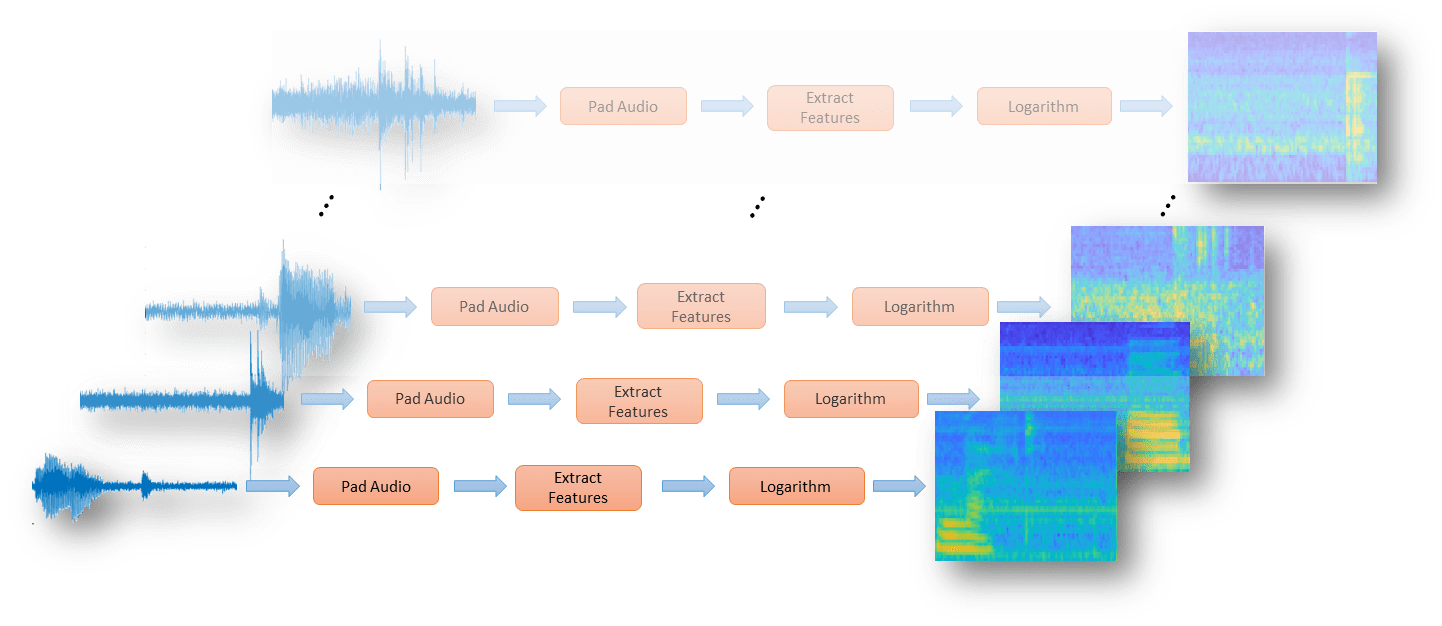
XTrain = readall(transform3,UseParallel=useParallel);
输出是一个 numFiles×1 元胞数组。该元胞数组的每个元素对应于从一个文件中提取的听觉频谱图。
numFiles = numel(XTrain)
numFiles = 28463
[numHops,numBands,numChannels] = size(XTrain{1})numHops = 98
numBands = 50
numChannels = 1
将元胞数组转换为 4 维数组,第 4 维为听觉频谱图。
XTrain = cat(4,XTrain{:});
[numHops,numBands,numChannels,numFiles] = size(XTrain)numHops = 98
numBands = 50
numChannels = 1
numFiles = 28463
对验证集执行上述特征提取步骤。
transform1 = transform(adsValidation,@(x)[zeros(floor((segmentSamples-size(x,1))/2),1);x;zeros(ceil((segmentSamples-size(x,1))/2),1)]);
transform2 = transform(transform1,@(x)extract(afe,x));
transform3 = transform(transform2,@(x){log10(x+1e-6)});
XValidation = readall(transform3,UseParallel=useParallel);
XValidation = cat(4,XValidation{:});为方便起见,对训练和验证目标标签进行隔离。
TTrain = adsTrain.Labels; TValidation = adsValidation.Labels;
可视化数据
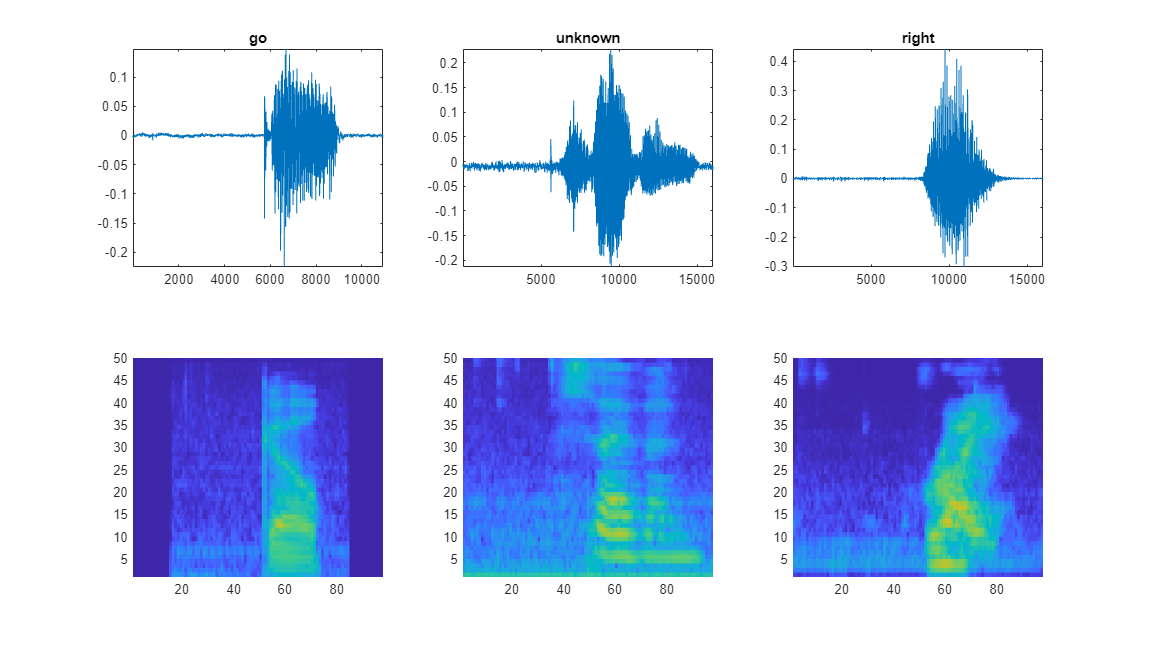
绘制几个训练样本的波形和听觉频谱图。播放对应的音频片段。
specMin = min(XTrain,[],"all"); specMax = max(XTrain,[],"all"); idx = randperm(numel(adsTrain.Files),3); figure(Units="normalized",Position=[0.2,0.2,0.6,0.6]); tlh = tiledlayout(2,3); for ii = 1:3 [x,fs] = audioread(adsTrain.Files{idx(ii)}); nexttile(tlh,ii) plot(x) axis tight title(string(adsTrain.Labels(idx(ii)))) nexttile(tlh,ii+3) spect = XTrain(:,:,1,idx(ii))'; pcolor(spect) clim([specMin specMax]) shading flat sound(x,fs) pause(2) end
定义网络架构
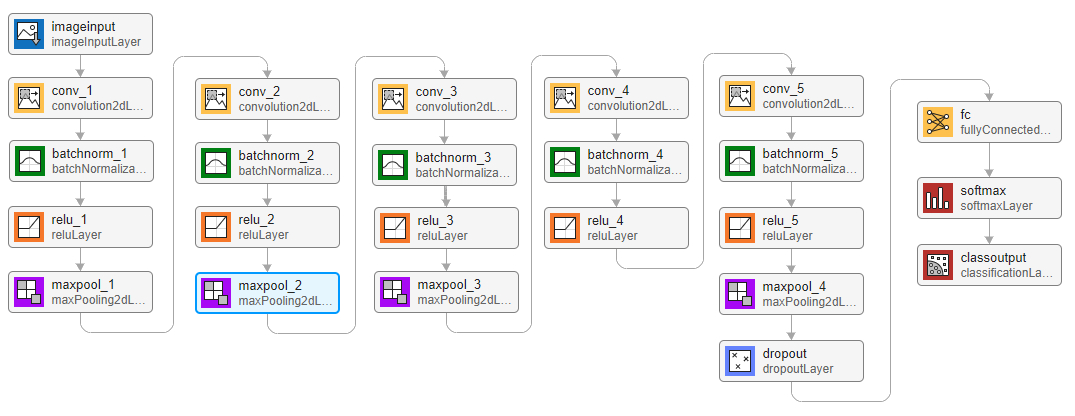
创建一个层数组形式的简单网络架构。使用卷积层和批量归一化层,并使用最大池化层“在空间上”(即,在时间和频率上)对特征图进行下采样。添加最终的最大池化层,它随时间对输入特征图进行全局池化。这会在输入频谱图中强制实施(近似的)时间平移不变性,从而使网络在对语音进行分类时不依赖于语音的准确时间位置,得到相同的分类结果。全局池化还可以显著减少最终全连接层中的参数数量。为了降低网络记住训练数据特定特征的可能性,可为最后一个全连接层的输入添加一个小的丢弃率。
该网络很小,因为它只有五个卷积层和几个滤波器。numF 控制卷积层中的滤波器数量。要提高网络的准确度,请尝试通过添加一些相同的模块(由卷积层、批量归一化层和 ReLU 层组成)来增加网络深度。还可以尝试通过增大 numF 来增加卷积滤波器的数量。
为了使每个类在损失中的总权重相等,使用的类权重应与每个类的训练样本数成反比。使用 Adam 优化器训练网络时,训练算法与类权重的整体归一化无关。
classes = categories(TTrain);
classWeights = 1./countcats(TTrain);
classWeights = classWeights'/mean(classWeights);
numClasses = numel(classes);
timePoolSize = ceil(numHops/8);
dropoutProb = 0.2;
numF = 12;
layers = [
imageInputLayer([numHops,afe.FeatureVectorLength])
convolution2dLayer(3,numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,2*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer([timePoolSize,1])
dropoutLayer(dropoutProb)
fullyConnectedLayer(numClasses)
softmaxLayer];指定训练选项
要定义训练参数,请使用 trainingOptions。使用小批量大小为 128 的 Adam 优化器。
miniBatchSize = 128; validationFrequency = floor(numel(TTrain)/miniBatchSize); options = trainingOptions("adam", ... InitialLearnRate=3e-4, ... MaxEpochs=15, ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false, ... ValidationData={XValidation,TValidation}, ... ValidationFrequency=validationFrequency, ... Metrics="accuracy");
训练网络
要训练网络,请使用 trainnet。如果您没有 GPU,则训练网络可能需要较长的时间。
trainedNet = trainnet(XTrain,TTrain,layers,@(Y,T)crossentropy(Y,T,classWeights(:),WeightsFormat="C"),options);
评估经过训练的网络
要计算基于训练集和验证集的网络最终准确度,请使用 minibatchpredict。网络对于此数据集非常准确。但是,训练数据、验证数据和测试数据全都具有相似的分布,不一定能反映真实环境。尤其是对仅包含少量单词读音的 unknown 类别,更是如此。
scores = minibatchpredict(trainedNet,XValidation); YValidation = scores2label(scores,classes,"auto"); validationError = mean(YValidation ~= TValidation); scores = minibatchpredict(trainedNet,XTrain); YTrain = scores2label(scores,classes,"auto"); trainError = mean(YTrain ~= TTrain); disp(["Training error: " + trainError*100 + " %";"Validation error: " + validationError*100 + " %"])
"Training error: 3.2744 %"
"Validation error: 6.6217 %"
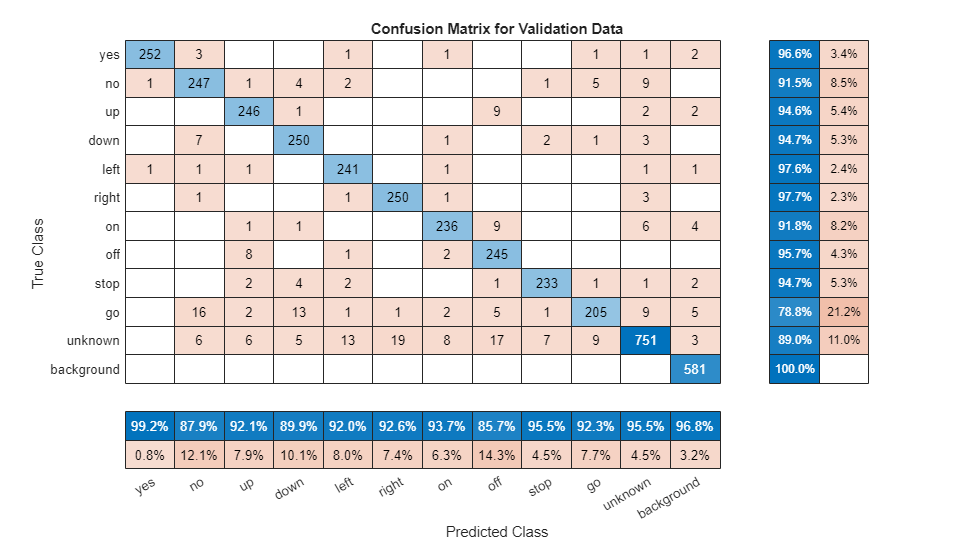
要绘制验证集的混淆矩阵,请使用 confusionchart。使用列汇总和行汇总显示每个类的准确率和召回率。
figure(Units="normalized",Position=[0.2,0.2,0.5,0.5]); cm = confusionchart(TValidation,YValidation, ... Title="Confusion Matrix for Validation Data", ... ColumnSummary="column-normalized",RowSummary="row-normalized"); sortClasses(cm,[commands,"unknown","background"])
在处理硬件资源受限的应用(如移动应用)时,必须考虑可用内存和计算资源的限制。当使用 CPU 时,以 KB 为单位计算网络总大小,并测试网络的预测速度。预测时间是指对单个输入图像进行分类的时间。如果向网络中输入多个图像,可以同时对它们进行分类,从而缩短每个图像的预测时间。然而,在对流音频进行分类时,单个图像预测时间是最相关的。
for ii = 1:100 x = randn([numHops,numBands]); predictionTimer = tic; y = predict(trainedNet,x); time(ii) = toc(predictionTimer); end disp(["Network size: " + whos("trainedNet").bytes/1024 + " kB"; ... "Single-image prediction time on CPU: " + mean(time(11:end))*1000 + " ms"])
"Network size: 310.5391 kB"
"Single-image prediction time on CPU: 1.8936 ms"
支持函数
用背景噪声增强数据集
function augmentDataset(datasetloc) adsBkg = audioDatastore(fullfile(datasetloc,"background")); fs = 16e3; % Known sample rate of the data set segmentDuration = 1; segmentSamples = round(segmentDuration*fs); volumeRange = log10([1e-4,1]); numBkgSegments = 4000; numBkgFiles = numel(adsBkg.Files); numSegmentsPerFile = floor(numBkgSegments/numBkgFiles); fpTrain = fullfile(datasetloc,"train","background"); fpValidation = fullfile(datasetloc,"validation","background"); if ~datasetExists(fpTrain) % Create directories mkdir(fpTrain) mkdir(fpValidation) for backgroundFileIndex = 1:numel(adsBkg.Files) [bkgFile,fileInfo] = read(adsBkg); [~,fn] = fileparts(fileInfo.FileName); % Determine starting index of each segment segmentStart = randi(size(bkgFile,1)-segmentSamples,numSegmentsPerFile,1); % Determine gain of each clip gain = 10.^((volumeRange(2)-volumeRange(1))*rand(numSegmentsPerFile,1) + volumeRange(1)); for segmentIdx = 1:numSegmentsPerFile % Isolate the randomly chosen segment of data. bkgSegment = bkgFile(segmentStart(segmentIdx):segmentStart(segmentIdx)+segmentSamples-1); % Scale the segment by the specified gain. bkgSegment = bkgSegment*gain(segmentIdx); % Clip the audio between -1 and 1. bkgSegment = max(min(bkgSegment,1),-1); % Create a file name. afn = fn + "_segment" + segmentIdx + ".wav"; % Randomly assign background segment to either the train or % validation set. if rand > 0.85 % Assign 15% to validation dirToWriteTo = fpValidation; else % Assign 85% to train set. dirToWriteTo = fpTrain; end % Write the audio to the file location. ffn = fullfile(dirToWriteTo,afn); audiowrite(ffn,bkgSegment,fs) end % Print progress fprintf('Progress = %d (%%)\n',round(100*progress(adsBkg))) end end end
参考资料
[1] Warden P."Speech Commands:A public dataset for single-word speech recognition", 2017.可从 https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz 获得。Copyright Google 2017.Speech Commands Dataset 是根据 Creative Commons Attribution 4.0 许可证授权的,可通过 https://creativecommons.org/licenses/by/4.0/legalcode 获得。
另请参阅
trainnet | trainingOptions | dlnetwork | testnet | minibatchpredict | scores2label | analyzeNetwork