使用自定义训练循环训练网络
此示例说明如何使用自定义学习率调度来训练对手写数字进行分类的网络。
您可以使用 trainnet 和 trainingOptions 函数训练大多数类型的神经网络。如果 trainingOptions 函数没有提供您需要的选项(例如,自定义求解器),则您可以定义自己的自定义训练循环,使用 dlarray 和 dlnetwork 对象进行自动微分。有关说明如何使用 trainnet 函数重新训练已经过预训练的深度学习网络的示例,请参阅重新训练神经网络以对新图像进行分类。
训练深度神经网络是一项优化任务。通过将神经网络视为 函数(其中 是网络输入,而 是可学习参数集),您可以优化 ,以便根据训练数据最小化某些损失值。例如,优化可学习参数 ,以便对于给定的输入 和对应的目标值 ,它们可以最小化预测值 和 之间的误差。
使用的损失函数取决于任务的类型。例如:
对于分类任务,您可以最小化预测值和目标值之间的交叉熵误差。
对于回归任务,您可以最小化预测值和目标值之间的均方误差。
您可以使用梯度下降算法来优化目标,即:使用损失函数相对于可学习参数的梯度来逐步接近最小值,以通过迭代更新可学习参数 来最小化损失 。梯度下降算法通常使用 形式的更新步长变体来更新可学习参数,其中 是迭代序号, 是学习率, 表示梯度(损失函数相对于可学习参数的导数)。
此示例使用随机梯度下降算法(不带动量)训练网络对手写数字进行分类。
加载训练数据
使用 imageDatastore 函数将位数数据加载为图像数据存储,并指定包含图像数据的文件夹。
unzip("DigitsData.zip") imds = imageDatastore("DigitsData", ... IncludeSubfolders=true, ... LabelSource="foldernames");
将数据划分为训练集和测试集。留出 10% 的数据用于使用 splitEachLabel 函数进行测试。
[imdsTrain,imdsTest] = splitEachLabel(imds,0.9,"randomize");此示例中使用的网络需要大小为 28×28×1 的输入图像。要自动调整训练图像的大小,请使用增强的图像数据存储。指定要对训练图像额外执行的增强操作:在水平和垂直坐标区上随机平移图像最多 5 个像素。数据增强有助于防止网络过拟合和记忆训练图像的具体细节。
inputSize = [28 28 1]; pixelRange = [-5 5]; imageAugmenter = imageDataAugmenter( ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain,DataAugmentation=imageAugmenter);
要在不执行进一步数据增强的情况下自动调整测试图像的大小,请使用增强的图像数据存储,而不指定任何其他预处理操作。
augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
确定训练数据中类的数量。
classes = categories(imdsTrain.Labels); numClasses = numel(classes);
定义网络
定义用于图像分类的网络。
对于图像输入,请指定输入大小与训练数据匹配的图像输入层。
不对图像输入进行归一化,将输入层的
Normalization选项设置为"none"。指定三个 convolution-batchnorm-ReLU 模块。
通过将
Padding选项设置为"same",填充卷积层的输入,使输出具有相同的大小。对于第一个卷积层,指定 20 个大小为 5 的滤波器。对于其余卷积层,指定 20 个大小为 3 的滤波器。
对于分类,指定一个大小与类数目匹配的全连接层
要将输出映射到概率,请包括一个 softmax 层。
使用自定义训练循环训练网络时,不要包含输出层。
layers = [
imageInputLayer(inputSize,Normalization="none")
convolution2dLayer(5,20,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,20,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,20,Padding="same")
batchNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];基于层数组创建一个 dlnetwork 对象。
net = dlnetwork(layers)
net =
dlnetwork with properties:
Layers: [12×1 nnet.cnn.layer.Layer]
Connections: [11×2 table]
Learnables: [14×3 table]
State: [6×3 table]
InputNames: {'imageinput'}
OutputNames: {'softmax'}
Initialized: 1
View summary with summary.
定义模型损失函数
训练深度神经网络是一项优化任务。通过将神经网络视为 函数(其中 是网络输入,而 是可学习参数集),您可以优化 ,以便根据训练数据最小化某些损失值。例如,优化可学习参数 ,以便对于给定的输入 和对应的目标值 ,它们可以最小化预测值 和 之间的误差。
定义 modelLoss 函数。modelLoss 函数接受 dlnetwork 对象 net、小批量输入数据 X和相应目标 T,并返回损失、损失相对于 net 中可学习参数的梯度以及网络状态。要自动计算梯度,请使用 dlgradient 函数。
function [loss,gradients,state] = modelLoss(net,X,T) % Forward data through network. [Y,state] = forward(net,X); % Calculate cross-entropy loss. loss = crossentropy(Y,T); % Calculate gradients of loss with respect to learnable parameters. gradients = dlgradient(loss,net.Learnables); end
定义 SGD 函数
创建 sgdStep 函数,该函数采用参数和损失相对于参数的梯度,并使用随机梯度下降算法返回更新后的参数,表示为 ,其中 是迭代序号, 是学习率, 表示梯度(损失相对于可学习参数的导数)。
function parameters = sgdStep(parameters,gradients,learnRate) parameters = parameters - learnRate .* gradients; end
定义自定义更新函数不是自定义训练循环的必要步骤。或者,您也可以使用内置更新函数,如 sgdmupdate、adamupdate 和 rmspropupdate。
指定训练选项
使用 128 的小批量大小和 0.01 的学习率进行十五轮训练。
numEpochs = 15; miniBatchSize = 128; learnRate = 0.01;
训练模型
创建一个 minibatchqueue 对象,用于在训练期间处理和管理小批量图像。对于每个小批量:
使用自定义小批量预处理函数
preprocessMiniBatch(在此示例末尾定义)将目标值转换为 one-hot 编码向量。用维度标签
"SSCB"(空间、空间、通道、批量)格式化图像数据。默认情况下,minibatchqueue对象将数据转换为基础类型为single的dlarray对象。不要格式化目标值。放弃部分小批量。
在 GPU 上(如果有)进行训练。默认情况下,如果 GPU 可用,则
minibatchqueue对象会将每个输出都转换为一个gpuArray。使用 GPU 需要 Parallel Computing Toolbox™ 和支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。
mbq = minibatchqueue(augimdsTrain,... MiniBatchSize=miniBatchSize,... MiniBatchFcn=@preprocessMiniBatch,... MiniBatchFormat=["SSCB" ""], ... PartialMiniBatch="discard");
计算训练进度监视器的总迭代次数。
numObservationsTrain = numel(imdsTrain.Files); numIterationsPerEpoch = floor(numObservationsTrain / miniBatchSize); numIterations = numEpochs * numIterationsPerEpoch;
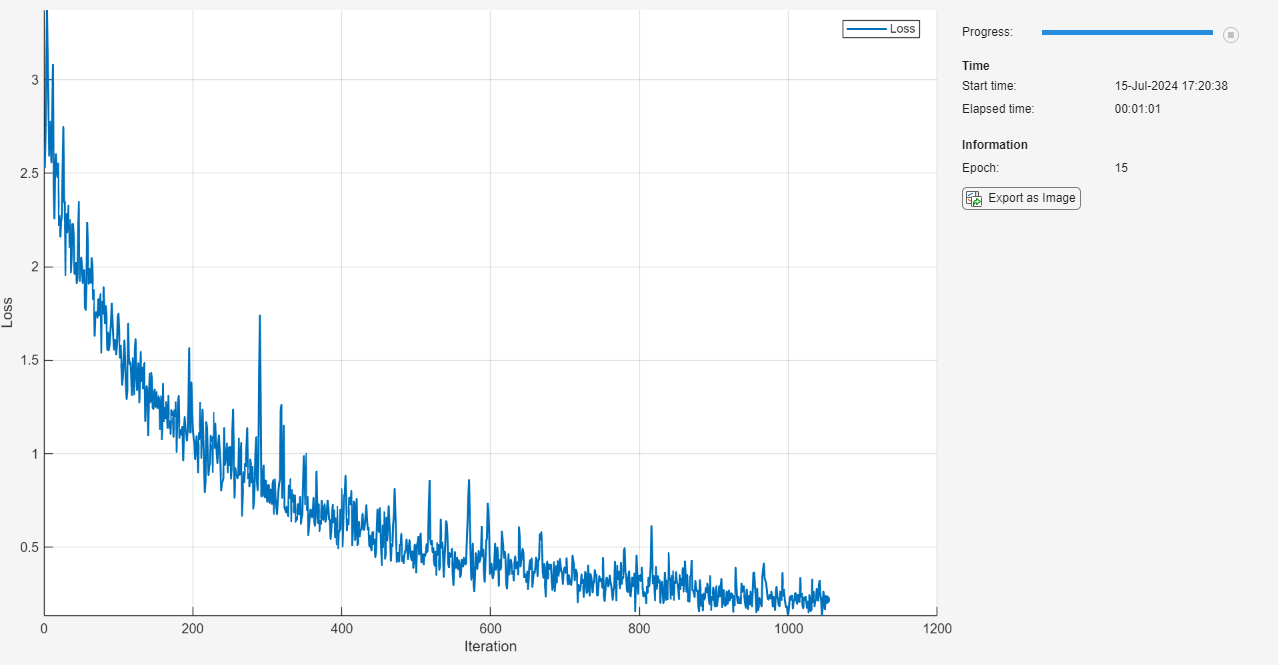
初始化 TrainingProgressMonitor 对象。由于计时器在您创建监视器对象时启动,请确保您创建的对象靠近训练循环。
monitor = trainingProgressMonitor( ... Metrics="Loss", ... Info="Epoch", ... XLabel="Iteration");
使用自定义训练循环来训练网络。对于每轮训练,对数据进行乱序处理,并遍历小批量数据。对于每个小批量:
使用
dlfeval和modelLoss函数计算模型损失、梯度和状态,并更新网络状态。使用
dlupdate函数和自定义更新函数更新网络参数。更新训练进度监视器中的损失值和轮数值。
如果 monitor 的 Stop 属性为 true,则停止。当您点击“停止”按钮时,
TrainingProgressMonitor对象的 Stop 属性值会更改为 true。
epoch = 0; iteration = 0; % Loop over epochs. while epoch < numEpochs && ~monitor.Stop epoch = epoch + 1; % Shuffle data. shuffle(mbq); % Loop over mini-batches. while hasdata(mbq) && ~monitor.Stop iteration = iteration + 1; % Read mini-batch of data. [X,T] = next(mbq); % Evaluate the model gradients, state, and loss using dlfeval and the % modelLoss function and update the network state. [loss,gradients,state] = dlfeval(@modelLoss,net,X,T); net.State = state; % Update the network parameters using SGD. updateFcn = @(parameters,gradients) sgdStep(parameters,gradients,learnRate); net = dlupdate(updateFcn,net,gradients); % Update the training progress monitor. recordMetrics(monitor,iteration,Loss=loss); updateInfo(monitor,Epoch=epoch); monitor.Progress = 100 * iteration/numIterations; end end
测试模型
使用 testnet 函数测试神经网络。对于单标签分类,需评估准确度。准确度是指正确预测的百分比。默认情况下,testnet 函数使用 GPU(如果有)。要手动选择执行环境,请使用 testnet 函数的 ExecutionEnvironment 参量。
accuracy = testnet(net,augimdsTest,"accuracy")accuracy = 96.3000
在混淆图中可视化预测。使用 minibatchpredict 函数进行预测,并使用 scores2label 函数将分类分数转换为标签。默认情况下,minibatchpredict 函数使用 GPU(如果有)。要手动选择执行环境,请使用 minibatchpredict 函数的 ExecutionEnvironment 参量。
scores = minibatchpredict(net,augimdsTest); YTest = scores2label(scores,classes);
在混淆图中可视化预测。
TTest = imdsTest.Labels; figure confusionchart(TTest,YTest)
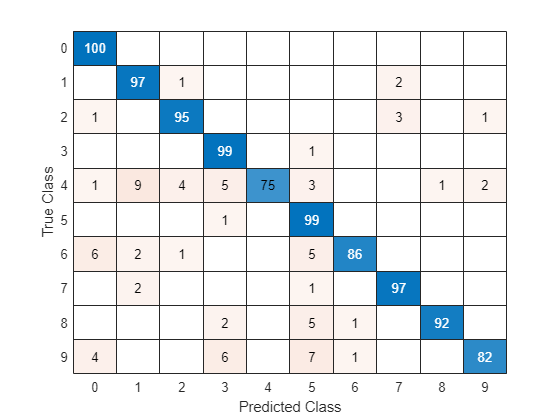
对角线上的较大值表示相应类的预测准确。非对角线上的较大值表示相应类之间的严重混淆。
支持函数
小批量预处理函数
preprocessMiniBatch 函数使用以下步骤预处理小批量预测变量和标签:
使用
preprocessMiniBatchPredictors函数预处理图像。从传入的元胞数组中提取标签数据,并沿第二个维度串联成一个分类数组。
将分类标签 one-hot 编码为数值数组。编码到第一个维度会生成与网络输出形状匹配的编码数组。
function [X,T] = preprocessMiniBatch(dataX,dataT) % Preprocess predictors. X = preprocessMiniBatchPredictors(dataX); % Extract label data from cell and concatenate. T = cat(2,dataT{:}); % One-hot encode labels. T = onehotencode(T,1); end
小批量预测变量预处理函数
preprocessMiniBatchPredictors 函数从输入元胞数组中提取图像数据并串联成一个数值数组,以此预处理小批量预测变量。对于灰度输入,在第四个维度上进行串联会向每个图像添加第三个维度,以用作单一通道维度。
function X = preprocessMiniBatchPredictors(dataX) % Concatenate. X = cat(4,dataX{:}); end
另请参阅
trainingProgressMonitor | dlarray | dlgradient | dlfeval | dlnetwork | forward | adamupdate | predict | minibatchqueue | onehotencode | onehotdecode