训练生成对抗网络 (GAN)
此示例说明如何训练生成对抗网络来生成图像。
生成对抗网络 (GAN) 是一种深度学习网络,它能够生成与真实输入数据具有相似特征的数据。
trainnet 函数不支持训练 GAN,因此您必须实现一个自定义训练循环。要使用自定义训练循环训练 GAN,您可以使用 dlarray 和 dlnetwork 对象进行自动微分。
一个 GAN 由两个一起训练的网络组成:
生成器 - 给定随机值(潜在输入)向量作为输入,此网络可生成与训练数据具有相同结构的数据。
判别器 - 给定包含来自训练数据和来自生成器的生成数据的观测值的数据批量,此网络尝试将观测值划分为
"real"或"generated"。
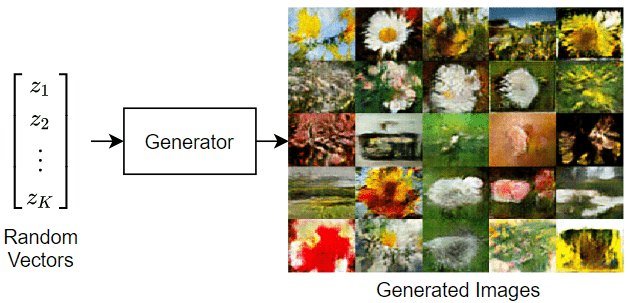
此图说明从随机输入向量生成图像的 GAN 的生成器网络。
此图说明 GAN 的结构。
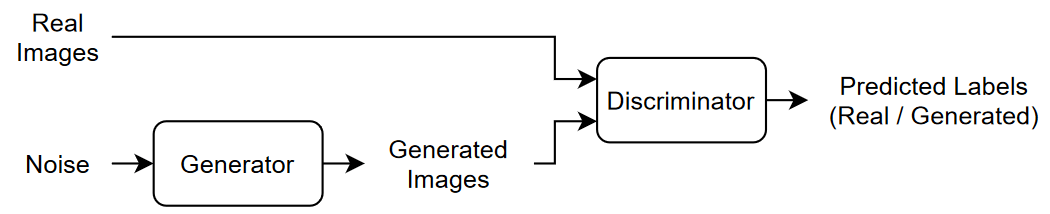
要训练 GAN,需要同时训练两个网络以最大化两个网络的性能:
训练生成器以生成“欺骗”判别器的数据。
训练判别器以区分真实数据和生成的数据。
为了优化生成器的性能,当给定生成的数据时,最大化判别器的损失。也就是说,生成器的目标是生成判别器分类为 "real" 的数据。
为了优化判别器的性能,当给定真实数据和生成的数据批量时,最小化判别器的损失。即判别器的目标是不被生成器“欺骗”。
理想情况下,这些策略会得到能够生成令人信服的真实数据的生成器,以及已学习到训练数据特有的强特征表示的判别器。
此示例使用 Flowers 数据集 [1](其中包含花卉图像)训练 GAN 以生成图像。
加载训练数据
下载并提取 Flowers 数据集 [1]。
url = "http://download.tensorflow.org/example_images/flower_photos.tgz"; downloadFolder = tempdir; filename = fullfile(downloadFolder,"flower_dataset.tgz"); imageFolder = fullfile(downloadFolder,"flower_photos"); if ~datasetExists(imageFolder) disp("Downloading Flowers data set (218 MB)...") websave(filename,url); untar(filename,downloadFolder) end
创建一个包含花卉照片的图像数据库。
imds = imageDatastore(imageFolder,IncludeSubfolders=true);
增强数据以包括随机水平翻转,并将图像大小调整为 64×64。
augmenter = imageDataAugmenter(RandXReflection=true); augimds = augmentedImageDatastore([64 64],imds,DataAugmentation=augmenter);
定义生成对抗网络
一个 GAN 由两个一起训练的网络组成:
生成器 - 给定随机值(潜在输入)向量作为输入,此网络可生成与训练数据具有相同结构的数据。
判别器 - 给定包含来自训练数据和来自生成器的生成数据的观测值的数据批量,此网络尝试将观测值划分为
"real"或"generated"。
此图说明 GAN 的结构。

定义生成器网络
定义以下网络架构,它使用随机向量生成图像。

此网络:
使用投影和重构操作将大小为 100 的随机向量转换为 4×4×512 数组。
使用一系列带批量归一化和 ReLU 层的转置卷积层,将生成的数组扩增到 64×64×3 数组。
将此网络架构定义为一个层图,并指定以下网络属性。
对于转置卷积层,指定 5×5 滤波器,每一层的滤波器数量递减,步幅为 2,并在每条边裁剪输出。
对于最终的转置卷积层,指定与生成图像的三个 RGB 通道对应的三个 5×5 滤波器,以及前一层的输出大小。
在网络末尾,包括一个 tanh 层。
要投影和重构噪声输入,请使用自定义层 projectAndReshapeLayer,该层以支持文件的形式包含在此示例中。要访问此层,请以实时脚本形式打开此示例。
filterSize = 5;
numFilters = 64;
numLatentInputs = 100;
projectionSize = [4 4 512];
layersGenerator = [
featureInputLayer(numLatentInputs)
projectAndReshapeLayer(projectionSize)
transposedConv2dLayer(filterSize,4*numFilters)
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,2*numFilters,Stride=2,Cropping="same")
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,numFilters,Stride=2,Cropping="same")
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,3,Stride=2,Cropping="same")
tanhLayer];要使用自定义训练循环训练网络并支持自动微分,请将层图转换为 dlnetwork 对象。
netG = dlnetwork(layersGenerator);
定义判别器网络
定义以下网络,它对真实图像和生成的 64×64 图像进行分类。
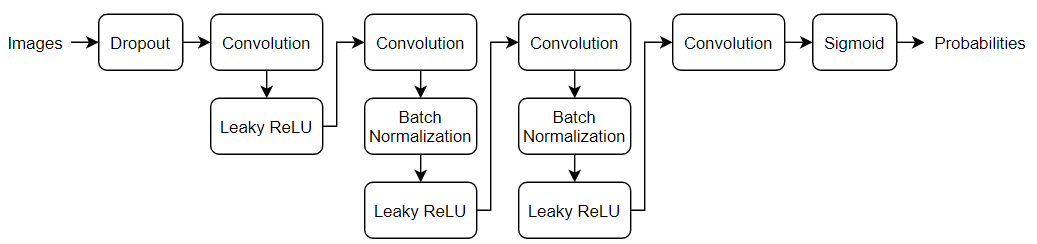
创建一个网络,该网络接受 64×64×3 图像,并使用一系列具有批量归一化和泄漏 ReLU 层的卷积层返回一个标量预测分数。使用丢弃法给输入图像添加噪声。
对于丢弃层,指定丢弃概率为 0.5。
对于卷积层,指定 5×5 滤波器,每一层的滤波器数量递增。同时指定步幅为 2 以及对输出进行填充。
对于泄漏 ReLU 层,指定 0.2 的尺度。
要输出 [0,1] 范围中的概率,请指定一个包含 4×4 滤波器并后跟一个 sigmoid 层的卷积层。
dropoutProb = 0.5;
numFilters = 64;
scale = 0.2;
inputSize = [64 64 3];
filterSize = 5;
layersDiscriminator = [
imageInputLayer(inputSize,Normalization="none")
dropoutLayer(dropoutProb)
convolution2dLayer(filterSize,numFilters,Stride=2,Padding="same")
leakyReluLayer(scale)
convolution2dLayer(filterSize,2*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(filterSize,4*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(filterSize,8*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(4,1)
sigmoidLayer];要使用自定义训练循环训练网络并支持自动微分,请将层图转换为 dlnetwork 对象。
netD = dlnetwork(layersDiscriminator);
定义模型损失函数
创建在示例的模型损失函数部分列出的函数 modelLoss,该函数接受生成器和判别器网络、小批量输入数据、随机值数组和翻转因子作为输入,并返回损失值和损失值关于网络中可学习参数的梯度、生成器状态和两个网络的分数。
指定训练选项
使用小批量大小 128 进行 500 轮训练。对于较大的数据集,您可能不需要进行这么多轮训练。
numEpochs = 500; miniBatchSize = 128;
指定 Adam 优化的选项。对于两个网络,都指定:
学习率为 0.0002
梯度衰减因子为 0.5
梯度平方衰减因子为 0.999
learnRate = 0.0002; gradientDecayFactor = 0.5; squaredGradientDecayFactor = 0.999;
如果判别器过快地学会了如何判别真实图像和生成的图像,则生成器可能无法进行训练。为了更好地平衡判别器和生成器的学习,请通过随机翻转分配给真实图像的标签向真实数据添加噪声。
指定以 0.35 的概率翻转真实标签。请注意,这不会减损生成器,因为所有生成的图像仍被正确标注。
flipProb = 0.35;
每经过 100 次迭代就显示生成的验证图像。
validationFrequency = 100;
训练模型
要训练 GAN,需要同时训练两个网络以最大化两个网络的性能:
训练生成器以生成“欺骗”判别器的数据。
训练判别器以区分真实数据和生成的数据。
为了优化生成器的性能,当给定生成的数据时,最大化判别器的损失。也就是说,生成器的目标是生成判别器分类为 "real" 的数据。
为了优化判别器的性能,当给定真实数据和生成的数据批量时,最小化判别器的损失。即判别器的目标是不被生成器“欺骗”。
理想情况下,这些策略会得到能够生成令人信服的真实数据的生成器,以及已学习到训练数据特有的强特征表示的判别器。
使用 minibatchqueue 处理和管理小批量图像。对于每个小批量:
使用自定义小批量预处理函数
preprocessMiniBatch(在此示例末尾定义)在[-1,1]范围内重新缩放图像。丢弃观测值少于指定小批量大小的任何不完整小批量。
使用格式
"SSCB"(空间、空间、通道、批量)格式化图像数据。默认情况下,minibatchqueue对象将数据转换为基础类型为single的dlarray对象。在 GPU 上(如果有)进行训练。默认情况下,如果 GPU 可用,则
minibatchqueue对象会将每个输出都转换为一个gpuArray。使用 GPU 需要 Parallel Computing Toolbox™ 和支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。
augimds.MiniBatchSize = miniBatchSize; mbq = minibatchqueue(augimds, ... MiniBatchSize=miniBatchSize, ... PartialMiniBatch="discard", ... MiniBatchFcn=@preprocessMiniBatch, ... MiniBatchFormat="SSCB");
使用自定义训练循环训练模型。在每次迭代中遍历训练数据并更新网络参数。为了监控训练进度,以保留的随机值数组作为生成器输入来显示一批生成图像,同时显示其相关的分数图。
为 Adam 优化初始化参数。
trailingAvgG = []; trailingAvgSqG = []; trailingAvg = []; trailingAvgSqD = [];
为了监控训练进度,使用一批保留的随机值固定向量作为输入馈送到生成器,显示一批生成图像并绘制其网络分数图。
创建一个由保留的随机值组成的数组。
numValidationImages = 25;
ZValidation = randn(numLatentInputs,numValidationImages,"single");将数据转换为 dlarray 对象,并指定格式 "CB"(通道、批处理)。
ZValidation = dlarray(ZValidation,"CB"); 对于 GPU 训练,将数据转换为 gpuArray 对象。
if canUseGPU ZValidation = gpuArray(ZValidation); end
要跟踪生成器和判别器的分数,请使用 trainingProgressMonitor 对象。计算监视器对象的总迭代次数。
numObservationsTrain = numel(imds.Files); numIterationsPerEpoch = floor(numObservationsTrain/miniBatchSize); numIterations = numEpochs*numIterationsPerEpoch;
初始化 TrainingProgressMonitor 对象。由于计时器在您创建监视器对象时启动,请确保您创建的对象靠近训练循环。
monitor = trainingProgressMonitor( ... Metrics=["GeneratorScore","DiscriminatorScore"], ... Info=["Epoch","Iteration"], ... XLabel="Iteration"); groupSubPlot(monitor,Score=["GeneratorScore","DiscriminatorScore"])
训练 GAN。对于每轮训练,对数据存储进行乱序处理,并遍历小批量数据。
对于每个小批量:
如果
TrainingProgressMonitor对象的Stop属性为true,则停止。当您点击停止按钮时,Stop属性会更改为true。使用
dlfeval和modelLoss函数,评估损失对于可学习参数的梯度、生成器状态和网络分数。使用
adamupdate函数更新网络参数。绘制两个网络的分数。
在每
validationFrequency次迭代后,显示一批基于固定保留生成器输入的生成图像。
训练可能需要一些时间来运行。
epoch = 0; iteration = 0; % Loop over epochs. while epoch < numEpochs && ~monitor.Stop epoch = epoch + 1; % Reset and shuffle datastore. shuffle(mbq); % Loop over mini-batches. while hasdata(mbq) && ~monitor.Stop iteration = iteration + 1; % Read mini-batch of data. X = next(mbq); % Generate latent inputs for the generator network. Convert to % dlarray and specify the format "CB" (channel, batch). If a GPU is % available, then convert latent inputs to gpuArray. Z = randn(numLatentInputs,miniBatchSize,"single"); Z = dlarray(Z,"CB"); if canUseGPU Z = gpuArray(Z); end % Evaluate the gradients of the loss with respect to the learnable % parameters, the generator state, and the network scores using % dlfeval and the modelLoss function. [~,~,gradientsG,gradientsD,stateG,scoreG,scoreD] = ... dlfeval(@modelLoss,netG,netD,X,Z,flipProb); netG.State = stateG; % Update the discriminator network parameters. [netD,trailingAvg,trailingAvgSqD] = adamupdate(netD, gradientsD, ... trailingAvg, trailingAvgSqD, iteration, ... learnRate, gradientDecayFactor, squaredGradientDecayFactor); % Update the generator network parameters. [netG,trailingAvgG,trailingAvgSqG] = adamupdate(netG, gradientsG, ... trailingAvgG, trailingAvgSqG, iteration, ... learnRate, gradientDecayFactor, squaredGradientDecayFactor); % Every validationFrequency iterations, display batch of generated % images using the held-out generator input. if mod(iteration,validationFrequency) == 0 || iteration == 1 % Generate images using the held-out generator input. XGeneratedValidation = predict(netG,ZValidation); % Tile and rescale the images in the range [0 1]. I = imtile(extractdata(XGeneratedValidation)); I = rescale(I); % Display the images. image(I) xticklabels([]); yticklabels([]); title("Generated Images"); end % Update the training progress monitor. recordMetrics(monitor,iteration, ... GeneratorScore=scoreG, ... DiscriminatorScore=scoreD); updateInfo(monitor,Epoch=epoch,Iteration=iteration); monitor.Progress = 100*iteration/numIterations; end end


此时,判别器已学会在生成的图像中识别真实图像的强特征表示。顺带,生成器已学会类似的强特征表示,能够生成类似于训练数据的图像。
训练图显示生成器和判别器网络的分数。要了解有关如何解释网络分数的详细信息,请参阅Monitor GAN Training Progress and Identify Common Failure Modes。
生成新图像
要生成新图像,请使用生成器上的 predict 函数和包含一批随机向量的 dlarray 对象。要一起显示图像,请使用 imtile 函数,并使用 rescale 函数重新缩放图像。
创建一个 dlarray 对象(其中包含 25 个随机向量),以输入到生成器网络中。
numObservations = 25; ZNew = randn(numLatentInputs,numObservations,"single"); ZNew = dlarray(ZNew,"CB");
如果 GPU 可用,则将潜在向量转换为 gpuArray。
if canUseGPU ZNew = gpuArray(ZNew); end
使用 predict 函数以及生成器和输入数据生成新图像。
XGeneratedNew = predict(netG,ZNew);
显示图像。
I = imtile(extractdata(XGeneratedNew)); I = rescale(I); figure image(I) axis off title("Generated Images")

模型损失函数
函数 modelLoss 接受生成器和判别器 dlnetwork 对象 netG 和 netD、小批量输入数据 X、随机值数组 Z 和要翻转真实标签的概率 flipProb 作为输入,并返回损失值和损失值关于网络中可学习参数的梯度、生成器状态和两个网络的分数。
function [lossG,lossD,gradientsG,gradientsD,stateG,scoreG,scoreD] = ... modelLoss(netG,netD,X,Z,flipProb) % Calculate the predictions for real data with the discriminator network. YReal = forward(netD,X); % Calculate the predictions for generated data with the discriminator % network. [XGenerated,stateG] = forward(netG,Z); YGenerated = forward(netD,XGenerated); % Calculate the score of the discriminator. scoreD = (mean(YReal) + mean(1-YGenerated)) / 2; % Calculate the score of the generator. scoreG = mean(YGenerated); % Randomly flip the labels of the real images. numObservations = size(YReal,4); idx = rand(1,numObservations) < flipProb; YReal(:,:,:,idx) = 1 - YReal(:,:,:,idx); % Calculate the GAN loss. [lossG, lossD] = ganLoss(YReal,YGenerated); % For each network, calculate the gradients with respect to the loss. gradientsG = dlgradient(lossG,netG.Learnables,RetainData=true); gradientsD = dlgradient(lossD,netD.Learnables); end
GAN 损失函数和分数
生成器的目标是生成判别器分类为 "real" 的数据。为了最大化判别器将生成器生成的图像判别为真实图像的概率,最小化负对数似然函数。
给定判别器的输出 :
是输入图像属于
"real"类的概率。是输入图像属于
"generated"类的概率。
生成器的损失函数由下式给出
其中 包含生成图像的判别器输出概率。
判别器的目标是不被生成器“欺骗”。为了最大化判别器成功判别真实图像和生成图像的概率,最小化对应的负对数似然函数之和。
判别器的损失函数由下式给出
其中 包含真实图像的判别器输出概率。
要按照从 0 到 1 的范围来测量生成器和判别器实现各自目标的程度,可以使用分数的概念。
生成器分数是生成图像判别器输出的概率平均值:
判别器分数是真实图像和生成图像判别器输出的概率平均值:
分数与损失成反比,但实际上包含相同的信息。
function [lossG,lossD] = ganLoss(YReal,YGenerated) % Calculate the loss for the discriminator network. lossD = -mean(log(YReal)) - mean(log(1-YGenerated)); % Calculate the loss for the generator network. lossG = -mean(log(YGenerated)); end
小批量预处理函数
preprocessMiniBatch 函数使用以下步骤预处理数据:
从传入的元胞数组中提取图像数据,并串联成一个数值数组。
将图像重新缩放到
[-1,1]范围内。
function X = preprocessMiniBatch(data) % Concatenate mini-batch X = cat(4,data{:}); % Rescale the images in the range [-1 1]. X = rescale(X,-1,1,InputMin=0,InputMax=255); end
参考资料
The TensorFlow Team.Flowers http://download.tensorflow.org/example_images/flower_photos.tgz
Radford, Alec, Luke Metz, and Soumith Chintala.“Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.”Preprint, submitted November 19, 2015. http://arxiv.org/abs/1511.06434.
另请参阅
dlnetwork | forward | predict | dlarray | dlgradient | dlfeval | adamupdate | minibatchqueue