dlgradient
使用自动微分计算自定义训练循环的梯度
说明
dlgradient 函数使用自动微分来计算导数。
提示
对于大多数深度学习任务,您可以使用预训练神经网络,并使其适应您自己的数据。有关说明如何使用迁移学习来重新训练卷积神经网络以对一组新图像进行分类的示例,请参阅重新训练神经网络以对新图像进行分类。您也可以使用 trainnet 和 trainingOptions 函数从头创建和训练神经网络。
如果 trainingOptions 函数没有提供您的任务所需的训练选项,则您可以使用自动微分创建自定义训练循环。要了解详细信息,请参阅使用自定义训练循环训练网络。
如果 trainnet 函数没有提供您的任务所需的损失函数,您可以将 trainnet 的自定义损失函数指定为函数句柄。对于需要比预测值和目标值更多输入的损失函数(例如,需要访问神经网络或额外输入的损失函数),请使用自定义训练循环来训练模型。要了解详细信息,请参阅使用自定义训练循环训练网络。
如果 Deep Learning Toolbox™ 没有提供您的任务所需的层,则您可以创建一个自定义层。要了解详细信息,请参阅定义自定义深度学习层。对于无法指定为由层组成的网络的模型,可以将模型定义为函数。要了解详细信息,请参阅Train Network Using Model Function。
有关对哪项任务使用哪种训练方法的详细信息,请参阅Train Deep Learning Model in MATLAB。
[ 返回 dydx1,...,dydxk] = dlgradient(y,x1,...,xk)y 关于变量 x1 到 xk 的梯度。
从传递给 dlfeval 的函数内部调用 dlgradient。请参阅使用自动微分计算梯度和Use Automatic Differentiation In Deep Learning Toolbox。
[ 返回梯度并使用一个或多个名称-值对组指定其他选项。例如,dydx1,...,dydxk] = dlgradient(y,x1,...,xk,Name,Value)dydx = dlgradient(y,x,'RetainData',true) 会导致梯度保留中间值,以供在后续 dlgradient 调用中重用。此语法可以节省时间,但会使用更多内存。有关详细信息,请参阅提示。
示例
罗森布罗克函数是用于优化的标准测试函数。rosenbrock.m 辅助函数计算函数值并使用自动微分来计算其梯度。
type rosenbrock.mfunction [y,dydx] = rosenbrock(x) y = 100*(x(2) - x(1).^2).^2 + (1 - x(1)).^2; dydx = dlgradient(y,x); end
要计算点 [–1,2] 处的罗森布罗克函数值及其梯度,请创建该点的 dlarray,然后在函数句柄 @rosenbrock 上调用 dlfeval。
x0 = dlarray([-1,2]); [fval,gradval] = dlfeval(@rosenbrock,x0)
fval = 1×1 dlarray 104
gradval = 1×2 dlarray 396 200
或者,将罗森布罗克函数定义为具有两个输入(x1 和 x2)的函数。
type rosenbrock2.mfunction [y,dydx1,dydx2] = rosenbrock2(x1,x2) y = 100*(x2 - x1.^2).^2 + (1 - x1).^2; [dydx1,dydx2] = dlgradient(y,x1,x2); end
调用 dlfeval 来对表示输入 –1 和 2 的两个 dlarray 参量计算 rosenbrock2。
x1 = dlarray(-1); x2 = dlarray(2); [fval,dydx1,dydx2] = dlfeval(@rosenbrock2,x1,x2)
fval = 1×1 dlarray 104
dydx1 = 1×1 dlarray 396
dydx2 = 1×1 dlarray 200
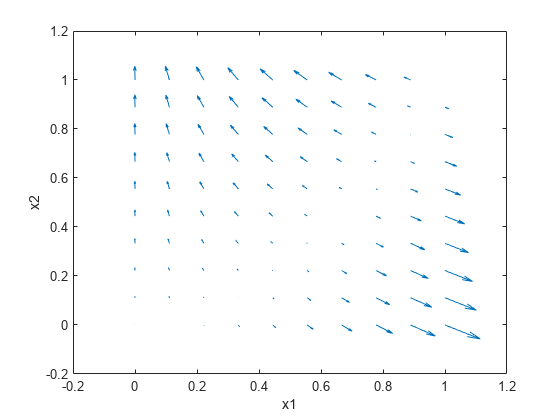
绘制单位正方形中多个点的罗森布罗克函数梯度图。首先,初始化表示计算点和函数输出的数组。
[X1 X2] = meshgrid(linspace(0,1,10)); X1 = dlarray(X1(:)); X2 = dlarray(X2(:)); Y = dlarray(zeros(size(X1))); DYDX1 = Y; DYDX2 = Y;
在循环中计算函数值。使用 quiver 绘制结果。
for i = 1:length(X1) [Y(i),DYDX1(i),DYDX2(i)] = dlfeval(@rosenbrock2,X1(i),X2(i)); end quiver(extractdata(X1),extractdata(X2),extractdata(DYDX1),extractdata(DYDX2)) xlabel('x1') ylabel('x2')
使用 dlgradient 和 dlfeval 计算涉及复数的函数的值和梯度。您可以计算复数梯度,也可以将梯度仅限为实数。
定义在此示例末尾列出的 complexFun 函数。此函数实现以下复数公式:
定义在此示例末尾列出的 gradFun 函数。此函数调用 complexFun 并使用 dlgradient 来计算结果关于输入的梯度。对于自动微分,要微分的值(即根据输入计算出的函数值)必须是实数标量,因此该函数在计算梯度之前会取结果实部之和。该函数返回函数值的实部和梯度(可能是复数)。
在复平面上定义 -2 到 2 以及 -2 到 2 之间的采样点,并转换为 dlarray。
functionRes = linspace(-2,2,100); x = functionRes + 1i*functionRes.'; x = dlarray(x);
计算每个样本点处的函数值和梯度。
[y, grad] = dlfeval(@gradFun,x); y = extractdata(y);
定义要显示其梯度的样本点。
gradientRes = linspace(-2,2,11); xGrad = gradientRes + 1i*gradientRes.';
提取这些样本点处的梯度值。
[~,gradPlot] = dlfeval(@gradFun,dlarray(xGrad)); gradPlot = extractdata(gradPlot);
绘制结果。使用 imagesc 在复平面上显示函数的值。使用 quiver 来显示梯度的方向和幅值。
imagesc([-2,2],[-2,2],y); axis xy colorbar hold on quiver(real(xGrad),imag(xGrad),real(gradPlot),imag(gradPlot),"k"); xlabel("Real") ylabel("Imaginary") title("Real Value and Gradient","Re$(f(x)) = $ Re$((2+3i)x)$","interpreter","latex")
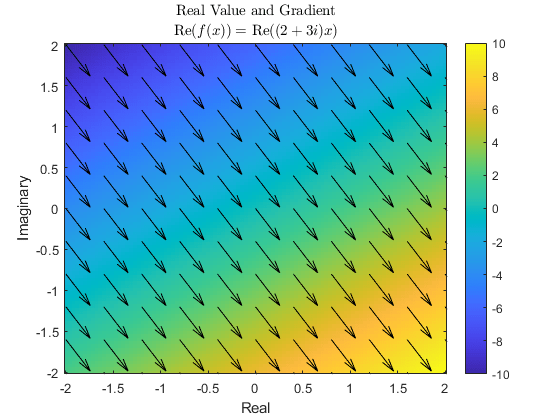
该函数的梯度在整个复平面上是相同的。提取自动微分计算出的梯度值。
grad(1,1)
ans = 1×1 dlarray 2.0000 - 3.0000i
经检查,函数的复数导数的值为
然而,Re() 函数不是解析函数,因此没有定义复数导数。对于 MATLAB 中的自动微分,要微分的值必须始终是实数,因此该函数永远不能是复数解析函数。在这种情况下,计算导数,使得返回的梯度指向上升坡度最大的方向,如图所示。这是通过将函数 Re:C R 解释为函数 Re:R R R 来完成的。
function y = complexFun(x) y = (2+3i)*x; end function [y,grad] = gradFun(x) y = complexFun(x); y = real(y); grad = dlgradient(sum(y,"all"),x); end
输入参数
名称-值参数
输出参量
限制
当使用的
dlnetwork对象包含具有自定义后向函数的自定义层时,dlgradient函数不支持计算高阶导数。当使用包含以下层的
dlnetwork对象时,dlgradient函数不支持计算高阶导数:gruLayerlstmLayerbilstmLayer
dlgradient函数不支持计算依赖于以下函数的高阶导数:grulstmembedprodinterp1
详细信息
提示
dlgradient调用必须在函数内部。要获取梯度的数值,您必须使用dlfeval计算函数,并且函数的参量必须是dlarray。请参阅Use Automatic Differentiation In Deep Learning Toolbox。为了能够正确计算梯度,
y参量必须仅使用dlarray支持的函数。请参阅List of Functions with dlarray Support。如果将
'RetainData'名称-值对组参量设置为true,则软件会在dlfeval函数调用期间保留跟踪,而不是在导数计算后立即擦除跟踪。这种保留可以加快同一dlfeval调用中后续dlgradient调用的执行速度,但使用的内存更多。例如,在训练对抗网络时,'RetainData'设置很有用,因为两个网络在训练期间共享数据和函数。请参阅训练生成对抗网络 (GAN)。当您只需要计算一阶导数时,请确保
'EnableHigherDerivatives'选项为false,因为这通常速度更快并且需要的内存更少。复数梯度是使用 Wirtinger 导数计算的。梯度沿着要微分的函数的实部增加的方向定义。这是因为即使函数是复数函数,要微分的变量(例如损失)也必须是实数。
要加快对深度学习函数(例如模型函数和模型损失函数)的调用,可以使用
dlaccelerate函数。该函数返回一个AcceleratedFunction对象,该对象自动优化、缓存和重用跟踪。
扩展功能
版本历史记录
在 R2019b 中推出
另请参阅
dlarray | dlfeval | dlnetwork | dljacobian | dldivergence | dllaplacian | dlaccelerate