使用自动微分进行自定义训练
如果 trainingOptions 函数不提供任务所需的训练选项,或您有 trainnet 函数不支持的损失函数,您可以定义自定义训练循环。对于无法指定为由层组成的网络的模型,可以将模型定义为函数。要了解详细信息,请参阅定义自定义训练循环、损失函数和网络。
函数
主题
自定义训练循环
- Train Deep Learning Model in MATLAB
Learn how to training deep learning models in MATLAB®. - 定义自定义训练循环、损失函数和网络
了解如何定义和自定义深度学习训练循环、损失函数和模型。 - 使用自定义训练循环训练网络
此示例说明如何使用自定义学习率调度来训练对手写数字进行分类的网络。 - Train Sequence Classification Network Using Custom Training Loop
This example shows how to train a network that classifies sequences with a custom learning rate schedule. - Specify Training Options in Custom Training Loop
Learn how to specify common training options in a custom training loop. - Define Model Loss Function for Custom Training Loop
Learn how to define a model loss function for a custom training loop. - Update Batch Normalization Statistics in Custom Training Loop
This example shows how to update the network state in a custom training loop. - 使用 dlnetwork 对象进行预测
此示例说明如何通过遍历小批量,使用dlnetwork对象进行预测。 - Monitor Custom Training Loop Progress
Track and plot custom training loop progress. - Compare Custom Solvers Using Custom Training Loop
This example shows how to train a deep learning network with different custom solvers and compare their accuracies. - Multiple-Input and Multiple-Output Networks
Learn how to define and train deep learning networks with multiple inputs or multiple outputs. - 训练具有多个输出的网络
此示例说明如何训练具有多个输出的深度学习网络,来预测手写数字的标签和旋转角度。 - Train Network in Parallel with Custom Training Loop
This example shows how to set up a custom training loop to train a network in parallel. - Run Custom Training Loops on a GPU and in Parallel
Speed up custom training loops by running on a GPU, in parallel using multiple GPUs, or on a cluster. - Detect Issues During Deep Neural Network Training
This example shows how to automatically detect issues while training a deep neural network. - Speed Up Deep Neural Network Training
Learn how to accelerate deep neural network training.
自动微分
- Automatic Differentiation Background
Learn how automatic differentiation works. - Deep Learning Data Formats
Learn about deep learning data formats. - List of Functions with dlarray Support
View the list of functions that supportdlarrayobjects. - Use Automatic Differentiation In Deep Learning Toolbox
How to use automatic differentiation in deep learning.
生成对抗网络
- 训练生成对抗网络 (GAN)
此示例说明如何训练生成对抗网络来生成图像。 - 训练条件生成对抗网络 (CGAN)
此示例说明如何训练条件生成对抗网络来生成图像。 - Train Wasserstein GAN with Gradient Penalty (WGAN-GP)
This example shows how to train a Wasserstein generative adversarial network with a gradient penalty (WGAN-GP) to generate images.
图形神经网络
- Multivariate Time Series Anomaly Detection Using Graph Neural Network
This example shows how to detect anomalies in multivariate time series data using a graph neural network (GNN). - Node Classification Using Graph Convolutional Network
This example shows how to classify nodes in a graph using a graph convolutional network (GCN). - Multilabel Graph Classification Using Graph Attention Networks
This example shows how to classify graphs that have multiple independent labels using graph attention networks (GATs).
深度学习函数加速
- Deep Learning Function Acceleration for Custom Training Loops
Accelerate model functions and model loss functions for custom training loops by caching and reusing traces. - Accelerate Custom Training Loop Functions
This example shows how to accelerate deep learning custom training loop and prediction functions. - 检查加速深度学习函数输出
此示例说明如何检查加速函数的输出是否与底层函数的输出匹配。 - Evaluate Performance of Accelerated Deep Learning Function
This example shows how to evaluate the performance gains of using an accelerated function.
相关信息
精选示例

Generate Images Using Diffusion
Generate new images using a diffusion model.
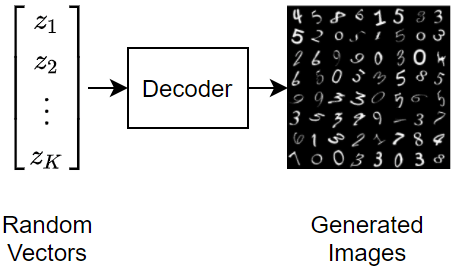
训练变分自编码器 (VAE) 以生成图像
此示例说明如何训练深度学习变分自编码器 (VAE) 来生成图像。
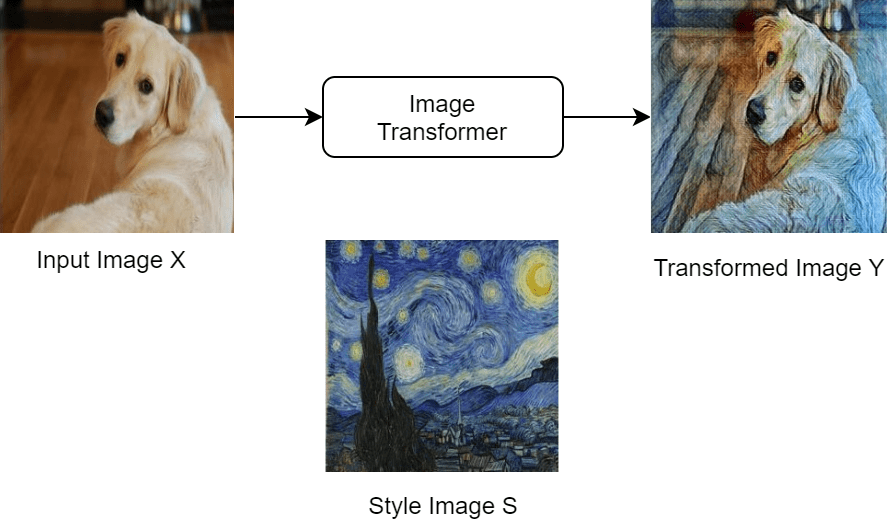
Train Fast Style Transfer Network
Train a network to transfer the style of an image to a second image. It is based on the architecture defined in [1].

Train a Twin Network for Dimensionality Reduction
Train a twin neural network with shared weights to compare handwritten digits using dimensionality reduction.
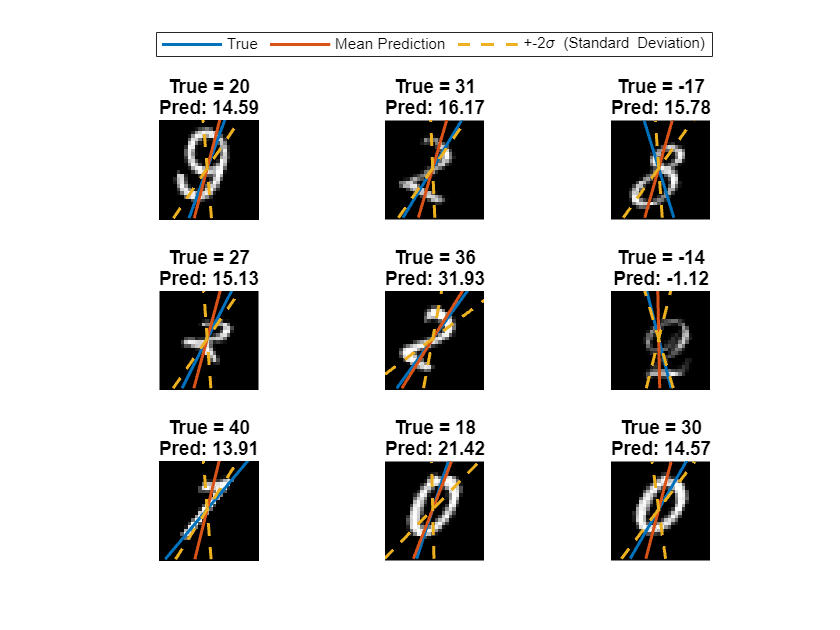
Train Bayesian Neural Network
Train a Bayesian neural network (BNN) for image regression using Bayes by Backpropagation.

Train Image Classification Network Robust to Adversarial Examples
Train a neural network that is robust to adversarial examples using fast gradient sign method (FGSM) adversarial training.

Train Robust Deep Learning Network with Jacobian Regularization
Train a neural network that is robust to adversarial examples using a Jacobian regularization scheme.

Train a Twin Neural Network to Compare Images
Train a twin neural network with shared weights to identify similar images of handwritten characters.
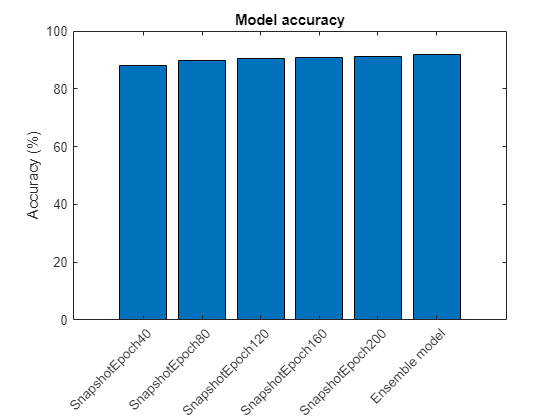
Train Network Using Cyclical Learning Rate for Snapshot Ensembling
Train a network to classify images of objects using a cyclical learning rate schedule and snapshot ensembling for better test accuracy. In the example, you learn how to use a cosine function for the learning rate schedule, take snapshots of the network during training to create a model ensemble, and add L2-norm regularization (weight decay) to the training loss.
Train Network Using Federated Learning
Train a network using federated learning. Federated learning is a technique that enables you to train a network in a distributed, decentralized way [1].
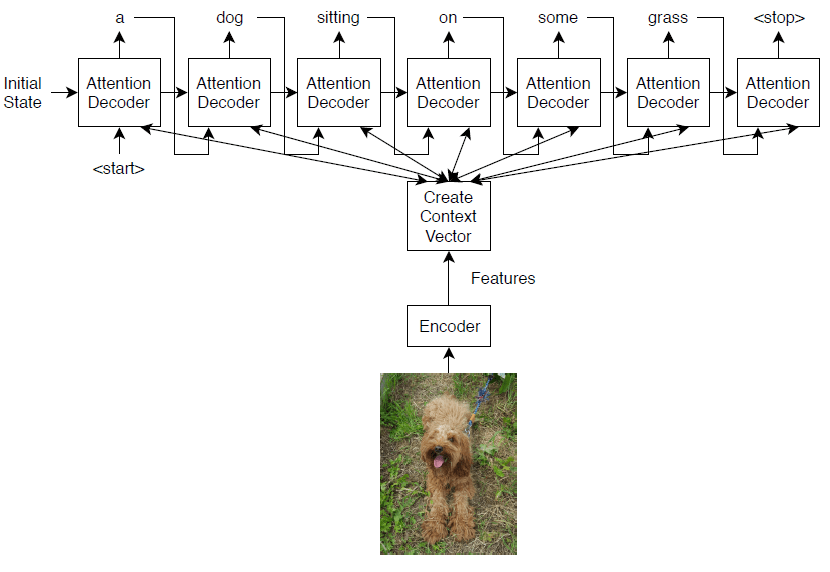
Image Captioning Using Attention
Train a deep learning model for image captioning using attention.