patchGANDiscriminator
Create PatchGAN discriminator network
Description
net = patchGANDiscriminator(inputSize)inputSize.
For more information about the PatchGAN network architecture, see PatchGAN Discriminator Network.
net = patchGANDiscriminator(inputSize,Name=Value)
You can create a 1-by-1 PatchGAN discriminator network, called a pixel discriminator
network, by specifying the NetworkType name-value argument as
"pixel". For more information about the pixel discriminator network
architecture, see Pixel Discriminator Network.
Examples
Input Arguments
Name-Value Arguments
Output Arguments
More About
A PatchGAN discriminator network consists of an encoder module that
downsamples the input by a factor of 2^NumDownsamplingBlocks. The
default network follows the architecture proposed by Zhu et. al. [2].
The encoder module consists of an initial block of layers that performs one downsampling
operation, NumDownsamplingBlocks–1 downsampling blocks, and a final
block.
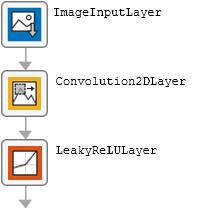
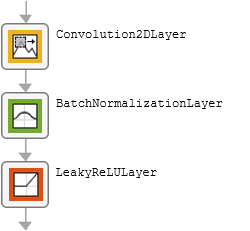
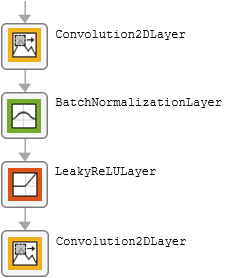
The table describes the blocks of layers that comprise the encoder module.
| Block Type | Layers | Diagram of Default Block |
|---|---|---|
| Initial block |
|
|
| Downsampling block |
|
|
| Final block |
|
|
A pixel discriminator network consists of an initial block and final block that return an output of size [H W C]. This network does not perform downsampling. The default network follows the architecture proposed by Zhu et. al. [2].
The table describes the blocks of layers that comprise the network.
| Block Type | Layers | Diagram of Default Block |
|---|---|---|
| Initial block |
|
|
| Final block |
|
|
References
[1]
[2]
Version History
Introduced in R2021a