对分类数据绘图
此示例演示了如何对 categorical 数组中的数据绘图。
加载样本数据
加载从 100 位患者收集的样本数据。显示 patients MAT 文件中数组的数据类型和大小。
load patients
whosName Size Bytes Class Attributes Age 100x1 800 double Diastolic 100x1 800 double Gender 100x1 11412 cell Height 100x1 800 double LastName 100x1 11616 cell Location 100x1 14208 cell SelfAssessedHealthStatus 100x1 11540 cell Smoker 100x1 100 logical Systolic 100x1 800 double Weight 100x1 800 double
创建分类数组
工作区变量 Location 列出了患者就医的三个唯一医疗机构。
为了更方便地访问和比较数据,请将 Location 转换为一个 categorical 数组。
Location = categorical(Location);
汇总 categorical 数组。汇总显示每个类别在 Location 中出现的次数。
summary(Location)
County General Hospital 39
St. Mary's Medical Center 24
VA Hospital 37
39 位患者在 County General Hospital 就医,24 位患者在 St. Mary's Medical Center 就医,37 位患者在 VA Hospital 就医。
工作区变量 SelfAssessedHealthStatus 包含四个唯一值 Excellent、Fair、Good 和 Poor。
将 SelfAssessedHealthStatus 转换为一个有序 categorical 数组,这样这些类别采用数学排序 Poor < Fair < Good < Excellent。
SelfAssessedHealthStatus = categorical(SelfAssessedHealthStatus,... ["Poor","Fair","Good","Excellent"],"Ordinal",true);
汇总 categorical 数组 SelfAssessedHealthStatus。
summary(SelfAssessedHealthStatus)
Poor 11
Fair 15
Good 40
Excellent 34
绘制直方图
直接基于 SelfAssessedHealthStatus 创建一个直方条形图。此 categorical 数组是有序 categorical 数组。类别的顺序为 Poor < Fair < Good < Excellent,这确定了类别在图的 x 轴上的顺序。histogram 函数为四个类别中的每个类别绘制类别计数。
figure
histogram(SelfAssessedHealthStatus)
title("Self Assessed Health Status From 100 Patients")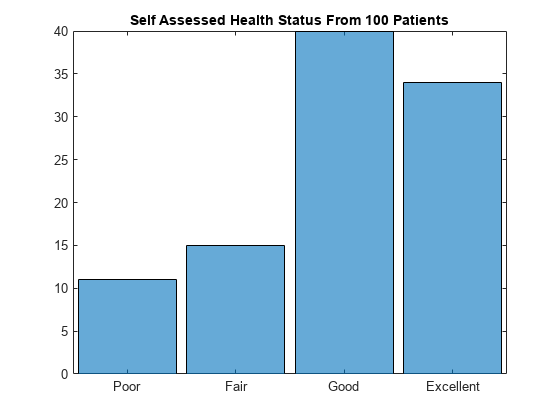
仅为健康状况评估为 Fair 或 Poor 的患者绘制医院位置直方图。
figure histogram(Location(SelfAssessedHealthStatus <= "Fair")) title("Location of Patients in Fair or Poor Health")

创建饼图
从 categorical 数组直接创建饼图。
figure
pie(SelfAssessedHealthStatus);
title("Self Assessed Health Status From 100 Patients")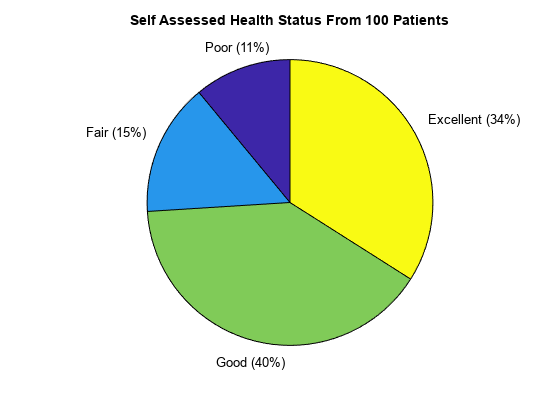
函数 pie 接受 categorical 数组 SelfAssessedHealthStatus,并绘制了一个包含四个类别的饼图。
创建帕累托图
根据 SelfAssessedHealthStatus 的四个类别各自的类别计数创建帕累托图。
figure
A = countcats(SelfAssessedHealthStatus);
C = categories(SelfAssessedHealthStatus);
pareto(A,C);
title("Self Assessed Health Status From 100 Patients")
pareto 的第一个输入参量必须是向量。如果 categorical 数组为矩阵或多维数组,则在调用 countcats 和 pareto 之前将其重构为向量。
创建散点图
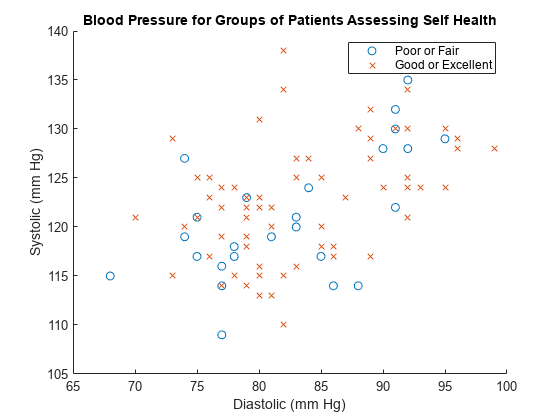
确定自我评估的健康状况是否与血压读数相关。创建一个两组患者的 Diastolic 和 Systolic 读数的散点图。
首先,为两组患者创建 x 和 y 血压读数数组。第一组患者包括那些将自我健康状况评估为 Poor 或 Fair 的患者。第二组包括那些将自我健康状况评估为 Good 或 Excellent 的患者。
您可以使用 categorical 数组 SelfAssessedHealthStatus 来创建逻辑索引。使用逻辑索引将 Diastolic 和 Systolic 中的值提取到不同数组中。
X1 = Diastolic(SelfAssessedHealthStatus <= "Fair"); Y1 = Systolic(SelfAssessedHealthStatus <= "Fair"); X2 = Diastolic(SelfAssessedHealthStatus >= "Good"); Y2 = Systolic(SelfAssessedHealthStatus >= "Good");
X1 和 Y1 是 26×1 数值数组,包含健康状况为 Poor 或 Fair 的患者的数据。
X2 和 Y2 是 74×1 数值数组,包含健康状况为 Good 或 Excellent 的患者的数据。
创建一个两组患者的血压读数的散点图。该图显示两组之间没有提示性差异,可能表明血压不影响这些患者对自身健康状况的评估。
figure h1 = scatter(X1,Y1,"o"); hold on h2 = scatter(X2,Y2,"x"); title("Blood Pressure for Groups of Patients Assessing Self Health"); xlabel("Diastolic (mm Hg)") ylabel("Systolic (mm Hg)") legend("Poor or Fair","Good or Excellent")
另请参阅
categorical | summary | countcats | histogram | pie | bar | rose | scatter
相关主题
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)