scatteredInterpolant
对二维或三维散点数据插值
说明
使用 scatteredInterpolant 对散点数据的二维或三维数据集执行插值。scatteredInterpolant 返回给定数据集的插值 F。您可以计算一组查询点(例如二维 (xq,yq))处的 F 值,以得出插入的值 vq = F(xq,yq)。
使用 griddedInterpolant 对网格数据执行插值。
创建对象
语法
描述
F = scatteredInterpolant
F = scatteredInterpolant(___,Method)'nearest'、'linear' 或 'natural' 作为最后一个输入参量。
F = scatteredInterpolant(___,Method,ExtrapolationMethod)Method 和 ExtrapolationMethod 作为最后两个输入参量。
输入参量
属性
用途
描述
使用 scatteredInterpolant 创建插值 F。然后,您可以使用以下任何语法在特定点处计算 F。
Vq = F(Pq) 在矩阵 Pq 中的查询点处对 F 求值。Pq 中的每行都包含查询点的坐标。
Vq = F(Xq,Yq) 和 Vq = F(Xq,Yq,Zq) 将查询点指定为两个或三个大小相等的数组。F 将查询点视为列向量,例如,Xq(:)。
如果
F的Values属性是表示样本点处的一组值的列向量,则Vq与查询点的大小相同。如果
F的Values属性是表示样本点处多组值的矩阵,则Vq是矩阵,每列表示查询点处不同的一组值。
示例
定义一些样本点,并计算这些位置的三角函数的值。这些点是用于插值的样本值。
t = linspace(3/4*pi,2*pi,50)'; x = [3*cos(t); 2*cos(t); 0.7*cos(t)]; y = [3*sin(t); 2*sin(t); 0.7*sin(t)]; v = repelem([-0.5; 1.5; 2],length(t));
创建插值。
F = scatteredInterpolant(x,y,v);
计算位于查询位置 (xq, yq) 处的插值。
tq = linspace(3/4*pi+0.2,2*pi-0.2,40)'; xq = [2.8*cos(tq); 1.7*cos(tq); cos(tq)]; yq = [2.8*sin(tq); 1.7*sin(tq); sin(tq)]; vq = F(xq,yq);
绘制结果。
plot3(x,y,v,'.',xq,yq,vq,'.'), grid on title('Linear Interpolation') xlabel('x'), ylabel('y'), zlabel('Values') legend('Sample data','Interpolated query data','Location','Best')

为一组散点样本点创建插值,然后计算一组三维查询点处的插值。
定义 200 个随机点并对三角函数采样。这些点是用于插值的样本值。
rng default;
P = -2.5 + 5*rand([200 3]);
v = sin(P(:,1).^2 + P(:,2).^2 + P(:,3).^2)./(P(:,1).^2+P(:,2).^2+P(:,3).^2);创建插值。
F = scatteredInterpolant(P,v);
计算位于查询位置 (xq,yq,zq) 处的插值。
[xq,yq,zq] = meshgrid(-2:0.25:2); vq = F(xq,yq,zq);
绘制结果的切片。
xslice = [-.5,1,2]; yslice = [0,2]; zslice = [-2,0]; slice(xq,yq,zq,vq,xslice,yslice,zslice)

在需要更改位于样本点处的值时替换 Values 属性中的元素。由于原始三角剖分没有改变,因此您在计算新插值时可立即获得结果。
创建 50 个随机点并对指数函数进行采样。这些点是用于插值的样本值。
rng('default')
x = -2.5 + 5*rand([50 1]);
y = -2.5 + 5*rand([50 1]);
v = x.*exp(-x.^2-y.^2);创建插值。
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×1 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
在 (1.40,1.90) 处计算插值。
F(1.40,1.90)
ans = 0.0069
更改插值样本值,并重新计算同一点处的插值。
vnew = x.^2 + y.^2; F.Values = vnew; F(1.40,1.90)
ans = 5.6491
使用 groupsummary 消除重复的采样点,并在调用 scatteredInterpolant 之前控制其合并方式。
创建一个由采样点位置组成的 200×3 矩阵。在最后五行添加重复的点。
P = -2.5 + 5*rand(200,3); P(197:200,:) = repmat(P(196,:),4,1);
创建一个由采样点上的随机值组成的向量。
V = rand(size(P,1),1);
如果您尝试对重复采样点使用 scatteredInterpolant,它会抛出警告,并对 V 中的对应值求平均值以产生一个唯一点。但您可以在创建插值之前使用 groupsummary 来消除重复点。如果要使用求平均值以外的方法合并重复点,此操作尤其有用。
使用 groupsummary 消除重复采样点,并在重复采样点位置保留 V 中的最大值。指定采样点矩阵作为分组变量,指定对应值作为数据。
[V_unique,P_unique] = groupsummary(V,P,@max);
由于分组变量有三列,groupsummary 以元胞数组形式返回唯一组 P_unique。将元胞数组转换回矩阵。
P_unique = [P_unique{:}];创建插值。由于采样点现在是唯一的,scatteredInterpolant 不会发出警告。
I = scatteredInterpolant(P_unique,V_unique);
比较 scatteredInterpolant 提供的几种不同插值算法的结果。
创建包含 50 个散点的样本数据集。这里有意使用较少的点数量,目的是为了突出插值方法之间的差异。
x = -3 + 6*rand(50,1); y = -3 + 6*rand(50,1); v = sin(x).^4 .* cos(y);
创建插值和查询点网格。
F = scatteredInterpolant(x,y,v); [xq,yq] = meshgrid(-3:0.1:3);
使用 'nearest'、'linear' 和 'natural' 方法绘制结果图。每当插值方法更改时,您都需要重新查询插值以获取更新后的结果。
F.Method = 'nearest'; vq1 = F(xq,yq); plot3(x,y,v,'mo') hold on mesh(xq,yq,vq1) title('Nearest Neighbor') legend('Sample Points','Interpolated Surface','Location','NorthWest')
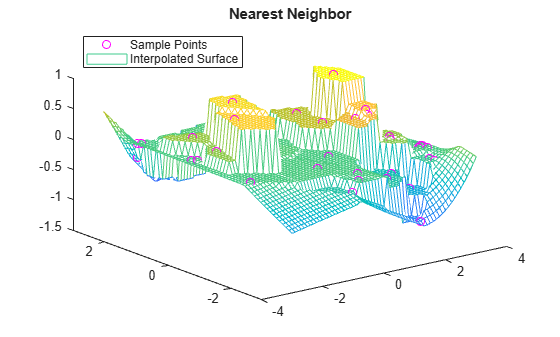
F.Method = 'linear'; vq2 = F(xq,yq); figure plot3(x,y,v,'mo') hold on mesh(xq,yq,vq2) title('Linear') legend('Sample Points','Interpolated Surface','Location','NorthWest')
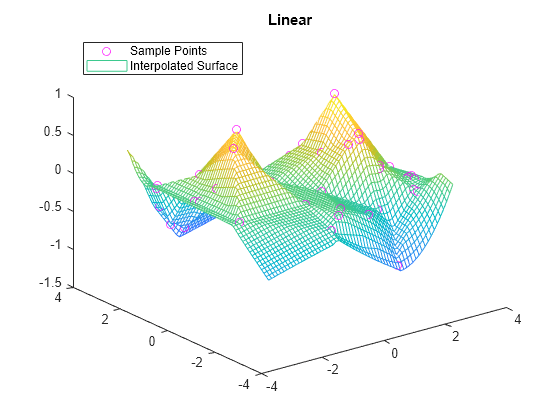
F.Method = 'natural'; vq3 = F(xq,yq); figure plot3(x,y,v,'mo') hold on mesh(xq,yq,vq3) title('Natural Neighbor') legend('Sample Points','Interpolated Surface','Location','NorthWest')
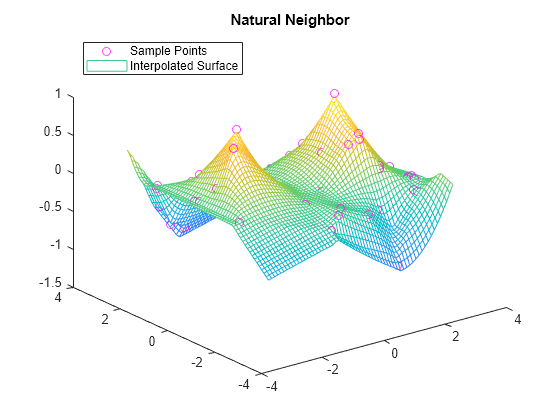
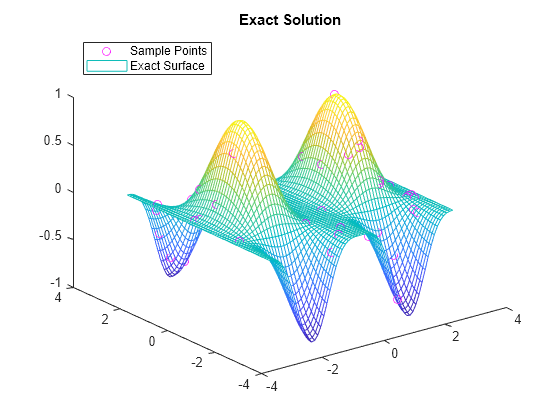
绘制精确解。
figure plot3(x,y,v,'mo') hold on mesh(xq,yq,sin(xq).^4 .* cos(yq)) title('Exact Solution') legend('Sample Points','Exact Surface','Location','NorthWest')
自 R2024a 起
比较 scatteredInterpolant 提供的几种不同外插方法的结果。
创建一个由 50 个散点组成的样本数据集,并计算在这些位置的三角函数的值。这些点是用于插值的样本值。
rng default
x = -3 + 6*rand(50,1);
y = -3 + 6*rand(50,1);
v = sin(x).^4 .* cos(y);创建插值。
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×1 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
计算输入数据的边界。
C = convhull(x,y); xc = [x(C); x(C(1))]; yc = [y(C); y(C(1))]; vc = [v(C); v(C(1))];
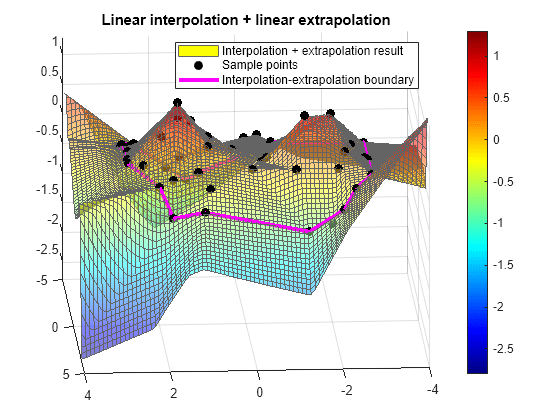
使用基于边界梯度的线性外插方法计算在查询位置 (xq,yq) 处的插值。然后,绘制内插和外插的结果。
[xq,yq] = meshgrid(-4:0.1:4); vq1 = F(xq,yq); surf(xq,yq,vq1,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + linear extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off
修改内插以使用最近邻外插,并计算和可视化内插。
F.ExtrapolationMethod = "nearest"; vq2 = F(xq,yq); surf(xq,yq,vq2,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + Nearest extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off

修改内插以将内插边界扩展到外插域中,并计算和可视化内插。
F.ExtrapolationMethod = "boundary"; vq3 = F(xq,yq); surf(xq,yq,vq3,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + Boundary extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off

通过检查绘制的结果来比较外插方法。边界外插会保持内插和外插域之间的连续性,而最近邻外插沿边界可能是不连续的。边界外插不会在外插域中产生极值,而线性外插会产生极值。
自 R2023b 起
在相同的查询点对多个数据集进行插值。
创建一个包含 50 个散点的样本数据集,由样本点向量 x 和 y 表示。
rng("default")
x = -3 + 6*rand(50,1);
y = -3 + 6*rand(50,1);要对多个数据集进行插值,请创建一个矩阵,其中每列表示不同函数在样本点的值。
s1 = sin(x).^4 .* cos(y); s2 = sin(x) + cos(y); s3 = x + y; s4 = x.^2 + y; v = [s1 s2 s3 s4];
创建查询点向量,指示为 v 中的每组值执行插值的位置。
xq = -3:0.1:3; yq = -3:0.1:3;
创建插值 F。
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×4 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
计算位于查询位置的插值。Vq 的每页都包含 v 中对应数据集的插值。
Vq = F({xq,yq});
size(Vq)ans = 1×3
61 61 4
绘制每个数据集的插值。
tiledlayout(2,2) nexttile plot3(x,y,v(:,1),'mo') hold on mesh(xq,yq,Vq(:,:,1)') title("sin(x).^4 .* cos(y)") nexttile plot3(x,y,v(:,2),'mo') hold on mesh(xq,yq,Vq(:,:,2)') title("sin(x) + cos(y)") nexttile plot3(x,y,v(:,3),'mo') hold on mesh(xq,yq,Vq(:,:,3)') title("x + y") nexttile plot3(x,y,v(:,4),'mo') hold on mesh(xq,yq,Vq(:,:,4)') title("x.^2 + y") lg = legend("Sample Points","Interpolated Surface"); lg.Layout.Tile = "north";

详细信息
提示
计算多组不同查询点处的
scatteredInterpolant对象F的值比使用函数griddata或griddatan单独计算插值的速度更快。例如:% Fast to create interpolant F and evaluate multiple times F = scatteredInterpolant(X,Y,V) v1 = F(Xq1,Yq1) v2 = F(Xq2,Yq2) % Slower to compute interpolations separately using griddata v1 = griddata(X,Y,V,Xq1,Yq1) v2 = griddata(X,Y,V,Xq2,Yq2)
要更改插值样本值或插值方法,更新插值对象
F的属性比创建新scatteredInterpolant对象的效率更高。当您更新Values或Method时,输入数据的基础德劳内三角剖分不会更改,因此您可以快速计算新结果。使用
scatteredInterpolant进行的散点数据插值使用数据的德劳内三角剖分,因此插值对样本点x、y、z或P中的缩放问题非常敏感。出现缩放问题时,您可以使用normalize重新缩放数据并改进结果。有关详细信息,请参阅对不同量级的数据进行归一化。
算法
scatteredInterpolant 使用散点样本点的德劳内三角剖分执行插值 [1]。
参考
[1] Amidror, Isaac. “Scattered data interpolation methods for electronic imaging systems: a survey.” Journal of Electronic Imaging. Vol. 11, No. 2, April 2002, pp. 157–176.
扩展功能
版本历史记录
在 R2013a 中推出另请参阅
griddedInterpolant | griddata | griddatan | ndgrid | meshgrid