unstack
将来自输入表或时间表的数据分列到输出表或时间表的多个变量中
说明
U = unstack(S,vars,ivar)vars 指定要分列的变量。通常,输出包含的变量比输入的变量多,但包含的行数更少。
输入参量 ivar 指定指示变量。在输入的每一行中,指示变量的值指示输出的对应变量。unstack 函数使用匹配指示值聚合数据。然后在输出的变量之间分发聚合值。
默认聚合方法取决于数据类型。例如,默认情况下,unstack 通过对数值数据求和来聚合数值数据。
输入可能包含未指定为 vars 或 ivar 的其他变量。unstack 函数对其他变量的处理方式会因表和时间表而不同。
如果
S是表,则unstack将其余的变量视为分组变量。分组变量中各个唯一的值组合标识了S中将要分列到U某一行的一组行。如果
S是时间表,则unstack将丢弃其余的变量。但是,unstack会将行时间向量视为分组变量。
您不能对表的行名称或时间表的行时间进行分列,也不能将行名称或行时间指定为指示变量。
示例
从 snowfall.mat 样本文件中载入一个表,该表指示各场暴风雪给各个城镇带来的降雪量。该表针对每场暴风雪包含三个降雪量条目,每个城镇一个。它采用堆叠格式,Storm 和 Town 具有 categorical 数据类型。具有 categorical 数据类型的表变量是有用的指示变量和分组变量。
load snowfall.mat
SS=12×3 table
Storm Town Snowfall
_____ _________ ________
3 Natick 0
3 Worcester 3
1 Natick 5
3 Boston 5
1 Boston 9
1 Worcester 10
4 Boston 12
2 Natick 13
4 Worcester 15
2 Worcester 16
4 Natick 17
2 Boston 21
将变量 Snowfall 分成三个变量,每个变量对应变量 Town 中指定的一个城镇。输出表为分列格式。U 中的各行包含来自 S 中的行(这些行在分组变量 Storm 中具有相同的值)的数据。Storm 中唯一值的顺序决定了 U 中数据的顺序。
U = unstack(S,"Snowfall","Town")
U=4×4 table
Storm Boston Natick Worcester
_____ ______ ______ _________
3 5 0 3
1 9 5 10
4 12 17 15
2 21 13 16
对于某些类型的分析和显示,分列格式可能更方便。例如,现在可以更直接地绘制每个城镇的降雪量。要绘制每个城镇的降雪量的散点图,请使用 scatter 函数。
scatter(U,"Storm",["Boston" "Natick" "Worcester"])
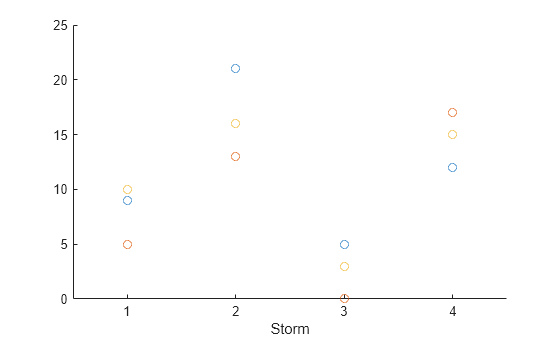
对数据进行分列运算,并向同一个组中具有相同指示变量值的多行应用聚合函数。还返回索引向量作为第二个参量。使用该参量对原始堆叠输入表进行索引。
从 stockPricesSmall.mat 样本文件载入一个时间表,该时间表包含两支股票两天内的价格数据。Stock 变量的数据类型为 categorical,因为该时间表具有一组固定的股票名称。
load stockPricesSmall.mat
SS=11×2 timetable
Date Stock Price
___________ ______ _____
12-Apr-2025 Stock1 60.35
12-Apr-2025 Stock2 27.68
12-Apr-2025 Stock1 64.19
12-Apr-2025 Stock2 25.47
12-Apr-2025 Stock2 28.11
12-Apr-2025 Stock2 27.98
15-Apr-2025 Stock1 63.85
15-Apr-2025 Stock2 27.55
15-Apr-2025 Stock2 26.43
15-Apr-2025 Stock1 65.73
15-Apr-2025 Stock2 25.94
S 包含 Stock1 第一天的两个价格和 Stock2 第一天的四个价格。
创建一个时间表,其中包含代表每支股票的不同变量,每一天占一行。将 Date(行时间向量)用作分组变量,并指定 mean 作为聚合函数。此操作分列 Price 变量中的价格,按日期对价格进行分组,并计算每支股票每天的均价。
[U,is] = unstack(S,"Price","Stock", ... AggregationFunction=@mean)
U=2×2 timetable
Date Stock1 Stock2
___________ ______ ______
12-Apr-2025 62.27 27.31
15-Apr-2025 64.79 26.64
is = 2×1
1
7
第二个输出 is 标识 S 中每个行组的第一个值的索引。例如,日期为 2025 年 4 月 15 日的组的第一个值位于 S 的第七行。
S(is(2),:)
ans=1×2 timetable
Date Stock Price
___________ ______ _____
15-Apr-2025 Stock1 63.85
输入参数
名称-值参数
输出参量
详细信息
提示
您可以指定输入的多个数据变量,每个变量都会变成输出中的一组分列数据变量。可使用正整数向量、包含多个变量名称的元胞数组或字符串数组或者逻辑向量来指定
vars。输入参量ivar指定的一个指示变量适用于vars指定的所有数据变量。