使用深度学习网络对语音去噪
此示例说明如何使用深度学习网络对语音信号去噪。该示例比较应用于同一任务的两种类型的网络:全连接网络和卷积网络。
简介
语音去噪的目的是去除语音信号中的噪声,同时提高语音的质量和清晰度。此示例说明如何使用深度学习网络从语音信号中去除洗衣机噪声。该示例比较应用于同一任务的两种类型的网络:全连接网络和卷积网络。
问题摘要
假设有以下以 8 kHz 频率采样的语音信号。
[cleanAudio,fs] = audioread("SpeechDFT-16-8-mono-5secs.wav");
sound(cleanAudio,fs)给语音信号增加洗衣机噪声。设置噪声功率,使信噪比 (SNR) 为零 dB。
noise = audioread("WashingMachine-16-8-mono-1000secs.mp3"); % Extract a noise segment from a random location in the noise file ind = randi(numel(noise) - numel(cleanAudio) + 1,1,1); noiseSegment = noise(ind:ind + numel(cleanAudio) - 1); speechPower = sum(cleanAudio.^2); noisePower = sum(noiseSegment.^2); noisyAudio = cleanAudio + sqrt(speechPower/noisePower)*noiseSegment;
收听含噪的语音信号。
sound(noisyAudio,fs)
可视化原始信号和含噪信号。
t = (1/fs)*(0:numel(cleanAudio) - 1); figure(1) tiledlayout(2,1) nexttile plot(t,cleanAudio) title("Clean Audio") grid on nexttile plot(t,noisyAudio) title("Noisy Audio") xlabel("Time (s)") grid on
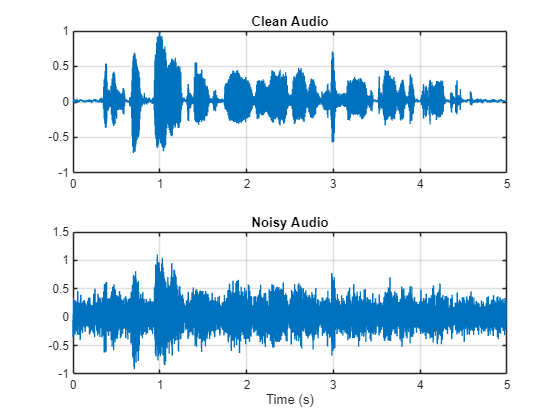
语音去噪的目标是从语音信号中去除洗衣机噪声,同时最小化输出语音中不需要的内容。
检查数据集
此示例使用 Mozilla 通用语音数据集 [1] 的一部分来训练和测试深度学习网络。该数据集包含受试者口述短句的 48 kHz 录音。下载该数据集并解压缩下载的文件。
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","commonvoice.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder) dataset = fullfile(dataFolder,"commonvoice");
使用 audioDatastore 为训练集创建数据存储。要以牺牲性能为代价来加快示例的运行时间,请将 speedupExample 设置为 true。
adsTrain = audioDatastore(fullfile(dataset,"train"),IncludeSubfolders=true); speedupExample =false; if speedupExample adsTrain = shuffle(adsTrain); adsTrain = subset(adsTrain,1:1000); end
使用 read 获取数据存储中第一个文件的内容。
[audio,adsTrainInfo] = read(adsTrain);
收听语音信号。
sound(audio,adsTrainInfo.SampleRate)
对语音信号绘图。
figure(2) t = (1/adsTrainInfo.SampleRate) * (0:numel(audio)-1); plot(t,audio) title("Example Speech Signal") xlabel("Time (s)") grid on

深度学习系统概述
基本的深度学习训练方案如下所示。请注意,因为语音通常低于 4 kHz,您首先将干净和含噪音频信号下采样到 8 kHz,以减轻网络的计算负荷。预测变量信号和网络目标信号分别是含噪音频信号和干净音频信号的幅值频谱。网络的输出是去噪信号的幅值频谱。回归网络使用预测变量输入来最小化其输出和输入目标之间的均方误差。使用输出的幅值频谱和含噪信号的相位将去噪后的音频转换回时域 [2]。
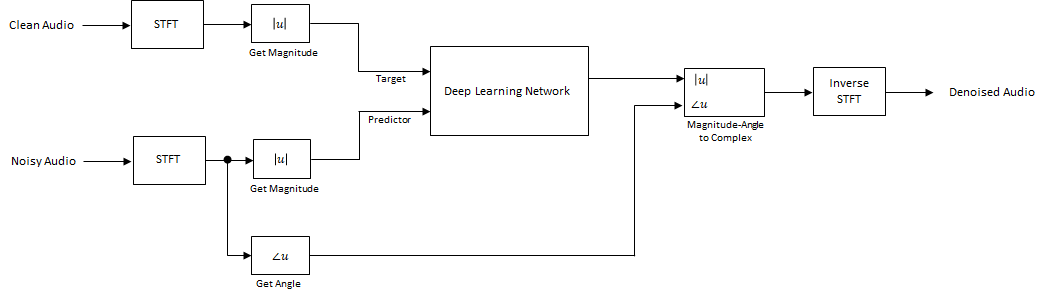
您可以使用短时傅里叶变换 (STFT) 将音频变换为频域,使用的窗长度为 256 个采样、重叠率为 75% 并使用汉明窗。通过丢弃对应于负频率的频率采样,可以将频谱向量的大小减小到 129(因为时域语音信号是实信号,这样不会导致任何信息丢失)。预测变量输入由 8 个连续含噪 STFT 向量组成,因此每个 STFT 输出估计是基于当前含噪 STFT 和 7 个前面的含噪 STFT 向量计算的。
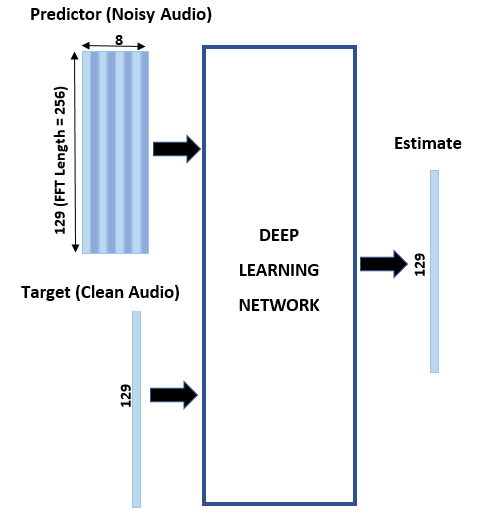
STFT 目标和预测变量
本节说明如何从一个训练文件中生成目标和预测变量信号。
首先,定义系统参数:
windowLength = 256;
win = hamming(windowLength,"periodic");
overlap = round(0.75*windowLength);
fftLength = windowLength;
inputFs = 48e3;
fs = 8e3;
numFeatures = fftLength/2 + 1;
numSegments = 8;创建一个 dsp.SampleRateConverter (DSP System Toolbox) 对象以将 48 kHz 音频转换为 8 kHz。
src = dsp.SampleRateConverter(InputSampleRate=inputFs,OutputSampleRate=fs,Bandwidth=7920);
使用 read 从数据存储中获取音频文件的内容。
audio = read(adsTrain);
确保音频长度是采样率转换器抽取因子的倍数。
decimationFactor = inputFs/fs; L = floor(numel(audio)/decimationFactor); audio = audio(1:decimationFactor*L);
将音频信号转换为 8 kHz。
audio = src(audio); reset(src)
使用洗衣机噪声向量创建一个随机噪声段。
randind = randi(numel(noise) - numel(audio),[1 1]); noiseSegment = noise(randind:randind + numel(audio) - 1);
向语音信号添加噪声,使 SNR 为 0 dB。
noisePower = sum(noiseSegment.^2); cleanPower = sum(audio.^2); noiseSegment = noiseSegment.*sqrt(cleanPower/noisePower); noisyAudio = audio + noiseSegment;
使用 stft 基于原始和含噪音频信号生成幅值 STFT 向量。
cleanSTFT = stft(audio,Window=win,OverlapLength=overlap,fftLength=fftLength); cleanSTFT = abs(cleanSTFT(numFeatures-1:end,:)); noisySTFT = stft(noisyAudio,Window=win,OverlapLength=overlap,fftLength=fftLength); noisySTFT = abs(noisySTFT(numFeatures-1:end,:));
基于含噪 STFT 生成包含 8 个段的训练预测变量信号。连续预测变量之间的重叠是 7 个段。
noisySTFT = [noisySTFT(:,1:numSegments - 1),noisySTFT]; stftSegments = zeros(numFeatures,numSegments,size(noisySTFT,2) - numSegments + 1); for index = 1:size(noisySTFT,2) - numSegments + 1 stftSegments(:,:,index) = noisySTFT(:,index:index + numSegments - 1); end
设置目标和预测变量。两个变量的最后一个维度对应于由音频文件生成的非重复预测变量/目标对组的数量。每个预测变量为 129×8,每个目标为 129×1。
targets = cleanSTFT; size(targets)
ans = 1×2
129 751
predictors = stftSegments; size(predictors)
ans = 1×3
129 8 751
使用 tall 数组提取特征
为了加快处理速度,使用 tall 数组从数据存储中所有音频文件的语音段中提取特征序列。与内存数组不同,在您调用 gather 函数之前,tall 数组通常不会实际进行计算。这种延迟计算使您能够快速处理大型数据集。当使用 gather 最终请求输出时,MATLAB 会尽可能地合并排队的计算,并执行最少次数的数据遍历。如果您有 Parallel Computing Toolbox™,您可以在本地 MATLAB 会话中或在本地并行池中使用 tall 数组。如果安装了 MATLAB® Parallel Server™,您还可以在集群上运行 tall 数组计算。
首先,将数据存储转换为 tall 数组。
reset(adsTrain) T = tall(adsTrain)
T =
M×1 tall cell array
{281712×1 double}
{289776×1 double}
{251760×1 double}
{332400×1 double}
{296688×1 double}
{113520×1 double}
{211440×1 double}
{ 97392×1 double}
: : :
: : :
上面的输出内容指示行数(对应于数据存储中的文件数)M 未知。M 是占位符,直到计算完成才会填充该值。
从 tall 表中提取目标幅值 STFT 和预测变量幅值 STFT。此操作会创建新 tall 数组变量以用于后续计算。函数 HelperGenerateSpeechDenoisingFeatures 执行在 STFT 目标和预测变量部分中已着重介绍的步骤。cellfun 命令将 HelperGenerateSpeechDenoisingFeatures 应用于数据存储中每个音频文件的内容。
[targets,predictors] = cellfun(@(x)HelperGenerateSpeechDenoisingFeatures(x,noise,src),T,UniformOutput=false);
使用 gather 计算目标和预测变量。
[targets,predictors] = gather(targets,predictors);
Evaluating tall expression using the Parallel Pool 'Processes': - Pass 1 of 1: Completed in 1 min 18 sec Evaluation completed in 2 min 47 sec
将所有特征归一化为具有零均值和单位标准差是很好的做法。
分别计算预测变量和目标的均值和标准差,并使用它们来归一化数据。
predictors = cat(3,predictors{:});
noisyMean = mean(predictors(:));
noisyStd = std(predictors(:));
predictors(:) = (predictors(:) - noisyMean)/noisyStd;
targets = cat(2,targets{:});
cleanMean = mean(targets(:));
cleanStd = std(targets(:));
targets(:) = (targets(:) - cleanMean)/cleanStd;将预测变量和目标重构为深度学习网络需要的维度。
predictors = reshape(predictors,size(predictors,1),size(predictors,2),1,size(predictors,3)); targets = reshape(targets,1,1,size(targets,1),size(targets,2));
在训练期间,您将使用 1% 的数据进行验证。验证对于检测网络过拟合训练数据的情况非常有用。
将数据随机分成训练集和验证集。
inds = randperm(size(predictors,4)); L = round(0.99*size(predictors,4)); trainPredictors = predictors(:,:,:,inds(1:L)); trainTargets = targets(:,:,:,inds(1:L)); validatePredictors = predictors(:,:,:,inds(L+1:end)); validateTargets = targets(:,:,:,inds(L+1:end));
使用全连接层进行语音去噪
首先以由全连接层组成的网络的去噪为例。全连接层中的每个神经元都连接到前一个层的所有激活。全连接层将输入乘以权重矩阵,然后添加偏置向量。权重矩阵和偏置向量的维度由层中神经元的数量和前一个层中激活的数量决定。
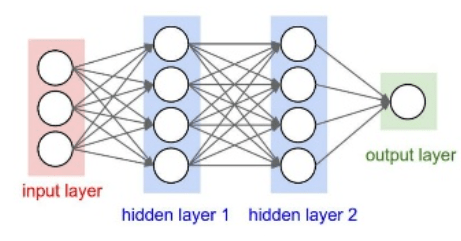
定义网络的各层。将输入大小指定为大小为 NumFeatures×NumSegments(本示例中为 129×8)的图像。定义两个隐藏的全连接层,每个层有 1024 个神经元。由于是纯线性系统,每个隐藏的全连接层后面都有一个修正线性单元 (ReLU) 层。批量归一化层对输出的均值和标准差进行归一化。添加一个包含 129 个神经元的全连接层,后跟一个回归层。
layers = [
imageInputLayer([numFeatures,numSegments])
fullyConnectedLayer(1024)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(1024)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(numFeatures)
];接下来,指定网络的训练选项。将 MaxEpochs 设置为 3 以便基于训练数据对网络进行 3 轮训练。将 MiniBatchSize 设置为 128 以便网络可以一次查看 128 个训练信号。将 Plots 指定为 "training-progress" 以生成随着迭代次数增加显示训练进度的图。将 Verbose 设置为 false 以禁止将对应于图中所示数据的表输出打印到命令行窗口中。将 Shuffle 指定为 "every-epoch" 以在每轮开始时打乱训练序列。将 LearnRateSchedule 指定为 "piecewise" 以便每经过一定数量的轮次 (1) 时,按指定的因子 (0.9) 降低学习率。将 ValidationData 设置为验证预测变量和目标。设置 ValidationFrequency 以便每轮计算一次验证均方误差。此示例使用自适应矩估计 (Adam) 求解器。
miniBatchSize = 128; options = trainingOptions("adam", ... MaxEpochs=3, ... InitialLearnRate=1e-5,... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false, ... ValidationFrequency=floor(size(trainPredictors,4)/miniBatchSize), ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.9, ... LearnRateDropPeriod=1, ... ValidationData={validatePredictors,squeeze(validateTargets)'});
使用 trainnet (Deep Learning Toolbox) 以指定的训练选项和层架构训练网络。由于训练集很大,训练过程可能需要几分钟。要下载并加载预训练网络而不是从头开始训练网络,请将 downloadPretrainedSystem 设置为 true。
downloadPretrainedSystem =false; if downloadPretrainedSystem downloadFolder = matlab.internal.examples.downloadSupportFile("audio/examples","sefc.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder) netFolder = fullfile(dataFolder,"SpeechDenoising"); s = load(fullfile(dataFolder,"denoiseNetFullyConnected.mat")); cleanMean = s.cleanMean; cleanStd = s.cleanStd; noisyMean = s.noisyMean; noisyStd = s.noisyStd; denoiseNetFullyConnected = s.denoiseNetFullyConnected; else denoiseNetFullyConnected = trainnet(trainPredictors,squeeze(trainTargets)',layers,"mse",options); end
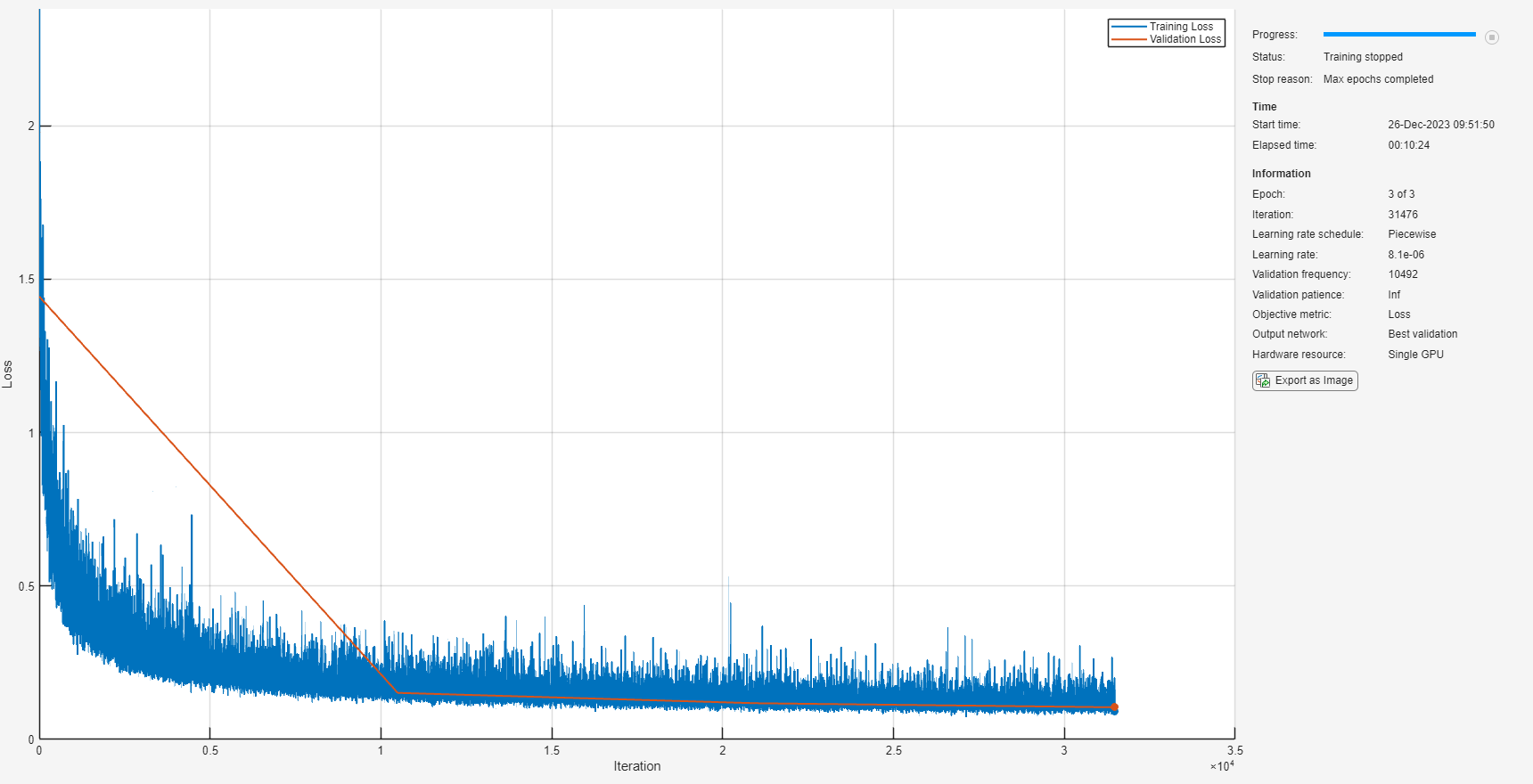
显示网络中可学习参数的数量。
summary(denoiseNetFullyConnected)
Initialized: true
Number of learnables: 2.2M
Inputs:
1 'imageinput' 129×8×1 images
使用卷积层进行语音去噪
以使用卷积层而不是全连接层的网络为例 [3]。二维卷积层对输入应用滑动滤波器。该层通过沿输入的纵向和横向移动滤波器来对输入进行卷积,并计算权重和输入的点积,然后加上偏置项。卷积层通常具有由比全连接层更少的参数。
定义由 16 个卷积层组成的 [3] 中所述的全卷积网络的层。前 15 个卷积层是重复 5 次的含 3 层的组,滤波器宽度分别为 9、5 和 9,滤波器数量分别为 18、30 和 8。最后一个卷积层具有 129 的滤波器宽度和 1 个滤波器。在此网络中,卷积仅在一个方向(沿频率维度)上执行,并且对于除第一层之外的所有层,沿时间维度的滤波器宽度设置为 1。与全连接网络相似,卷积层后是 ReLU 和批量归一化层。
layers = [imageInputLayer([numFeatures,numSegments])
convolution2dLayer([9 8],18,Stride=[1 100],Padding="same")
batchNormalizationLayer
reluLayer
repmat( ...
[convolution2dLayer([5 1],30,Stride=[1 100],Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer([9 1],8,Stride=[1 100],Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer([9 1],18,Stride=[1 100],Padding="same")
batchNormalizationLayer
reluLayer],4,1)
convolution2dLayer([5 1],30,Stride=[1 100],Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer([9 1],8,Stride=[1 100],Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer([129 1],1,Stride=[1 100],Padding="same")
];除验证目标信号的大小置换为与回归层预期的大小一致之外,训练选项与完全连接网络的选项相同。
options = trainingOptions("adam", ... MaxEpochs=3, ... InitialLearnRate=1e-5, ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false, ... ValidationFrequency=floor(size(trainPredictors,4)/miniBatchSize), ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.9, ... LearnRateDropPeriod=1, ... ValidationData={validatePredictors,permute(validateTargets,[3 1 2 4])});
使用 trainNetwork 以指定的训练选项和层架构训练网络。由于训练集很大,训练过程可能需要几分钟。要下载并加载预训练网络而不是从头开始训练网络,请将 downloadPretrainedSystem 设置为 true。
downloadPretrainedSystem =false; if downloadPretrainedSystem downloadFolder = matlab.internal.examples.downloadSupportFile("audio/examples","secnn.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder) s = load(fullfile(dataFolder,"denoiseNetFullyConvolutional.mat")); cleanMean = s.cleanMean; cleanStd = s.cleanStd; noisyMean = s.noisyMean; noisyStd = s.noisyStd; denoiseNetFullyConvolutional = s.denoiseNetFullyConvolutional; else denoiseNetFullyConvolutional = trainnet(trainPredictors,permute(trainTargets,[3 1 2 4]),layers,"mse",options); end
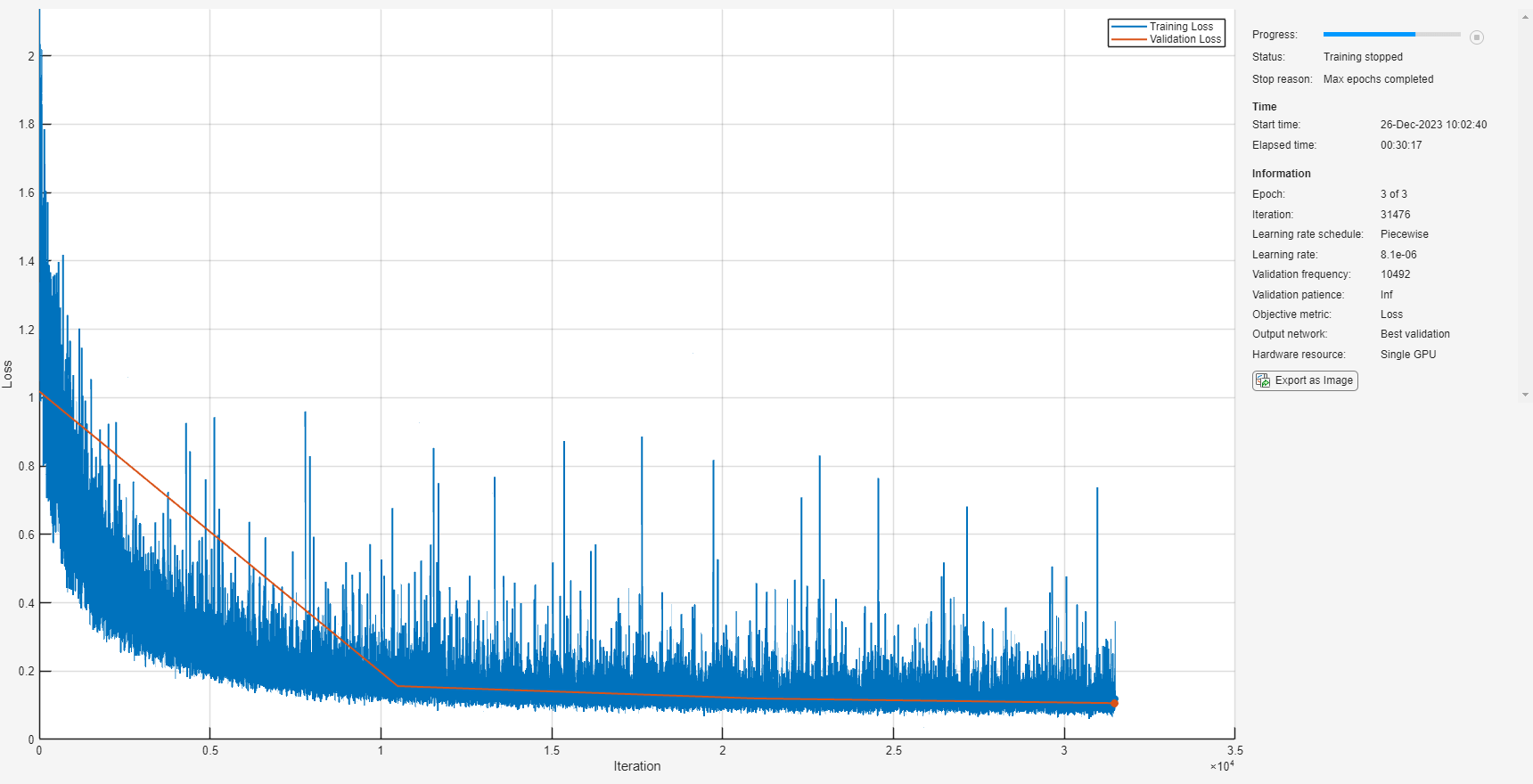
显示网络中可学习参数的数量。
summary(denoiseNetFullyConvolutional)
Initialized: true
Number of learnables: 32.6k
Inputs:
1 'imageinput' 129×8×1 images
测试去噪网络
读入测试数据集。
adsTest = audioDatastore(fullfile(dataset,"test"),IncludeSubfolders=true);从数据存储中读取一个文件的内容。
[cleanAudio,adsTestInfo] = read(adsTest);
确保音频长度是采样率转换器抽取因子的倍数。
L = floor(numel(cleanAudio)/decimationFactor); cleanAudio = cleanAudio(1:decimationFactor*L);
将音频信号转换为 8 kHz。
cleanAudio = src(cleanAudio); reset(src)
在此测试阶段,您用在训练阶段没有使用的洗衣机噪声干扰语音。
noise = audioread("WashingMachine-16-8-mono-200secs.mp3");使用洗衣机噪声向量创建一个随机噪声段。
randind = randi(numel(noise) - numel(cleanAudio), [1 1]); noiseSegment = noise(randind:randind + numel(cleanAudio) - 1);
向语音信号添加噪声,使 SNR 为 0 dB。
noisePower = sum(noiseSegment.^2); cleanPower = sum(cleanAudio.^2); noiseSegment = noiseSegment.*sqrt(cleanPower/noisePower); noisyAudio = cleanAudio + noiseSegment;
使用 stft 基于含噪音频信号生成幅值 STFT 向量。
noisySTFT = stft(noisyAudio,Window=win,OverlapLength=overlap,fftLength=fftLength); noisyPhase = angle(noisySTFT(numFeatures-1:end,:)); noisySTFT = abs(noisySTFT(numFeatures-1:end,:));
基于含噪 STFT 生成包含 8 个段的训练预测变量信号。连续预测变量之间的重叠是 7 个段。
noisySTFT = [noisySTFT(:,1:numSegments-1) noisySTFT]; predictors = zeros(numFeatures,numSegments,size(noisySTFT,2) - numSegments + 1); for index = 1:(size(noisySTFT,2) - numSegments + 1) predictors(:,:,index) = noisySTFT(:,index:index + numSegments - 1); end
通过训练阶段计算的均值和标准差将预测变量归一化。
predictors(:) = (predictors(:) - noisyMean)/noisyStd;
通过使用 predict 和两个经过训练的网络计算去噪后的 STFT 幅值。
predictors = reshape(predictors,[numFeatures,numSegments,1,size(predictors,3)]); STFTFullyConnected = predict(denoiseNetFullyConnected,predictors); STFTFullyConvolutional = predict(denoiseNetFullyConvolutional,predictors);
通过在训练阶段使用的均值和标准差来缩放输出。
STFTFullyConnected(:) = cleanStd*STFTFullyConnected(:) + cleanMean; STFTFullyConvolutional(:) = cleanStd*STFTFullyConvolutional(:) + cleanMean;
将单边 STFT 转换为居中 STFT。
STFTFullyConnected = (STFTFullyConnected.').*exp(1j*noisyPhase); STFTFullyConnected = [conj(STFTFullyConnected(end-1:-1:2,:));STFTFullyConnected]; STFTFullyConvolutional = squeeze(STFTFullyConvolutional).*exp(1j*noisyPhase); STFTFullyConvolutional = [conj(STFTFullyConvolutional(end-1:-1:2,:));STFTFullyConvolutional];
计算去噪后的语音信号。istft 执行 STFT 逆变换。使用含噪 STFT 向量的相位来重新构造时域信号。
denoisedAudioFullyConnected = istft(STFTFullyConnected,Window=win,OverlapLength=overlap,fftLength=fftLength,ConjugateSymmetric=true); denoisedAudioFullyConvolutional = istft(STFTFullyConvolutional,Window=win,OverlapLength=overlap,fftLength=fftLength,ConjugateSymmetric=true);
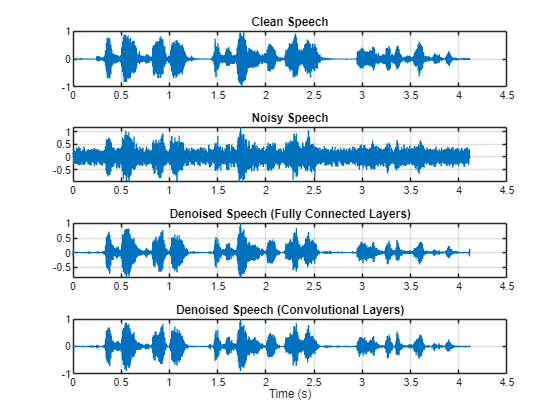
分别绘制干净、含噪和去噪的音频信号。
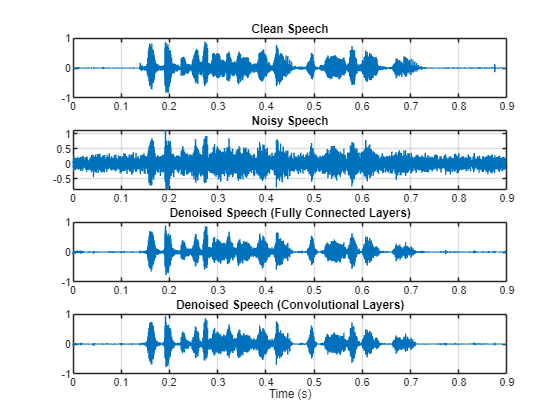
t = (1/fs)*(0:numel(denoisedAudioFullyConnected)-1); figure(3) tiledlayout(4,1) nexttile plot(t,cleanAudio(1:numel(denoisedAudioFullyConnected))) title("Clean Speech") grid on nexttile plot(t,noisyAudio(1:numel(denoisedAudioFullyConnected))) title("Noisy Speech") grid on nexttile plot(t,denoisedAudioFullyConnected) title("Denoised Speech (Fully Connected Layers)") grid on nexttile plot(t,denoisedAudioFullyConvolutional) title("Denoised Speech (Convolutional Layers)") grid on xlabel("Time (s)")
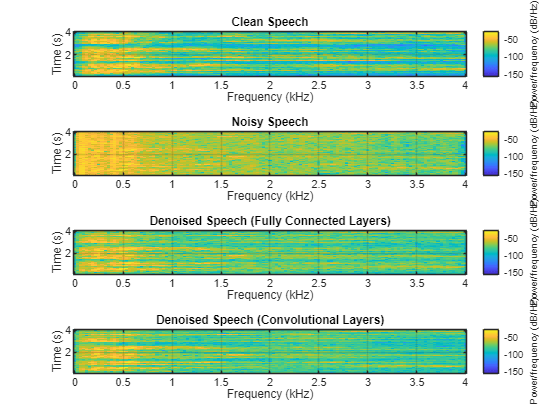
分别绘制干净、含噪和去噪的频谱图。
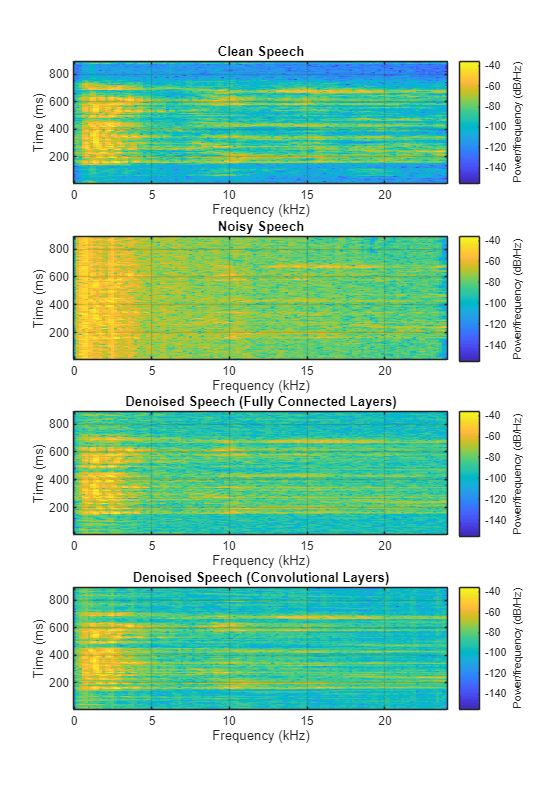
h = figure(4); tiledlayout(4,1) nexttile spectrogram(cleanAudio,win,overlap,fftLength,fs); title("Clean Speech") grid on nexttile spectrogram(noisyAudio,win,overlap,fftLength,fs); title("Noisy Speech") grid on nexttile spectrogram(denoisedAudioFullyConnected,win,overlap,fftLength,fs); title("Denoised Speech (Fully Connected Layers)") grid on nexttile spectrogram(denoisedAudioFullyConvolutional,win,overlap,fftLength,fs); title("Denoised Speech (Convolutional Layers)") grid on
p = get(h,"Position"); set(h,"Position",[p(1) 65 p(3) 800]);
收听含噪语音。
sound(noisyAudio,fs)
收听经过具有全连接层的网络处理的去噪语音。
sound(denoisedAudioFullyConnected,fs)
收听经过具有卷积层的网络处理的去噪语音。
sound(denoisedAudioFullyConvolutional,fs)
收听干净的语音。
sound(cleanAudio,fs)
您可以通过调用 testDenoisingNets 来测试数据存储中的更多文件。该函数生成上面突出显示的时域绘图和频域绘图,同时返回干净、含噪和去噪的音频信号。
[cleanAudio,noisyAudio,denoisedAudioFullyConnected,denoisedAudioFullyConvolutional] = testDenoisingNets(adsTest,denoiseNetFullyConnected,denoiseNetFullyConvolutional,noisyMean,noisyStd,cleanMean,cleanStd);
实时应用
上一节中的过程将含噪信号的整个频谱传递给 predict。这不适用于要求低延迟的实时应用。
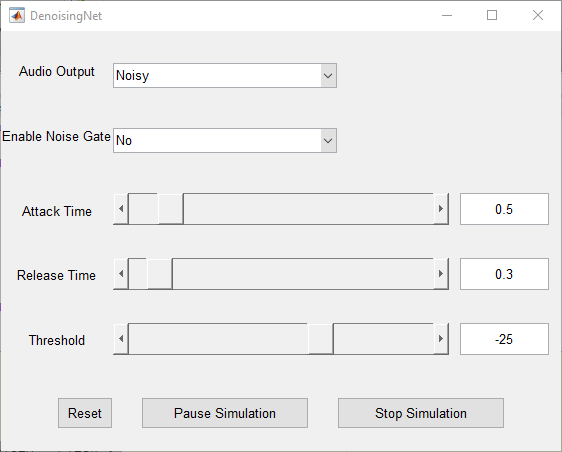
这里我们将运行 speechDenoisingRealtimeApp 以通过一个示例来了解如何仿真一个实时的流式去噪网络。该 App 使用具有全连接层的网络。音频帧长度等于 STFT 跳跃大小,即 0.25 * 256 = 64 个采样。
speechDenoisingRealtimeApp 会启动一个用于与仿真交互的用户界面 (UI)。该 UI 使您能够调整参数,结果会即时反映在仿真中。您还可以启用/禁用对去噪后的输出进行处理的噪声门,以进一步降低噪声,并调整噪声门的启动时间、释放时间和阈值。您可以从该 UI 收听含噪、干净或去噪的音频。
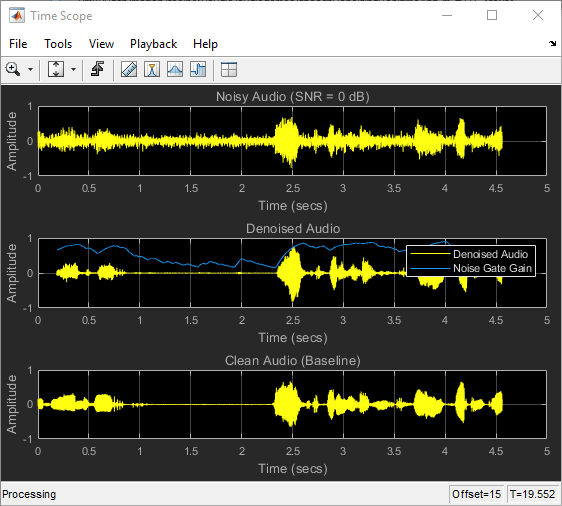
以下示波器绘制了干净、含噪和去噪的信号,以及噪声门的增益。
参考资料
[1] https://commonvoice.mozilla.org/
[2] "Experiments on Deep Learning for Speech Denoising", Ding Liu, Paris Smaragdis, Minje Kim, INTERSPEECH, 2014.
[3] "A Fully Convolutional Neural Network for Speech Enhancement", Se Rim Park, Jin Won Lee, INTERSPEECH, 2017.