copulafit
Fit copula to data
Syntax
Description
___ = copulafit(___, returns
any of the previous syntaxes, with additional options specified by
one or more Name,Value)Name,Value pair arguments. For example,
you can specify the confidence interval to compute, or specify control
parameters for the iterative parameter estimation algorithm using
a options structure.
Examples
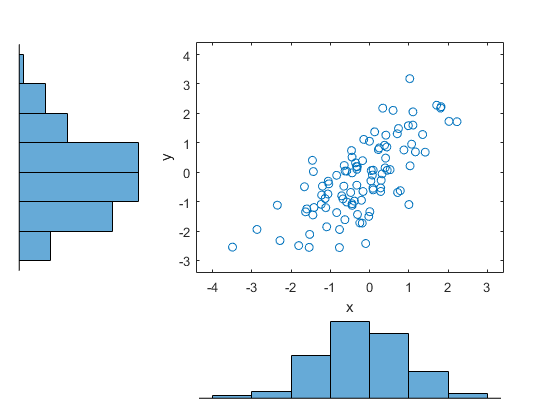
Load and plot simulated stock return data.
load stockreturns
x = stocks(:,1);
y = stocks(:,2);
figure;
scatterhist(x,y)
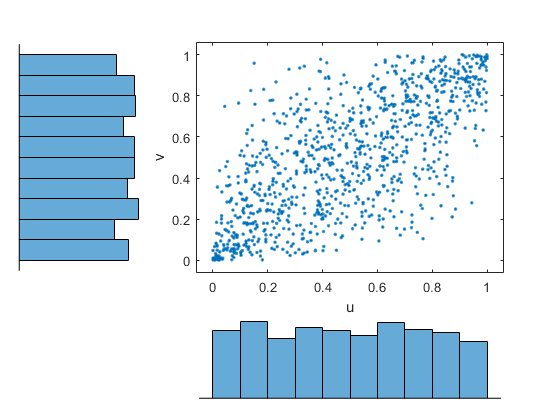
Transform the data to the copula scale (unit square) using a kernel estimator of the cumulative distribution function.
u = ksdensity(x,x,'function','cdf'); v = ksdensity(y,y,'function','cdf'); figure; scatterhist(u,v) xlabel('u') ylabel('v')

Fit a t copula to the data.
rng default % For reproducibility [Rho,nu] = copulafit('t',[u v],'Method','ApproximateML')
Rho =
1.0000 0.7220
0.7220 1.0000
nu =
2.7290e+06
Generate a random sample from the t copula.
r = copularnd('t',Rho,nu,1000); u1 = r(:,1); v1 = r(:,2); figure; scatterhist(u1,v1) xlabel('u') ylabel('v') set(get(gca,'children'),'marker','.')
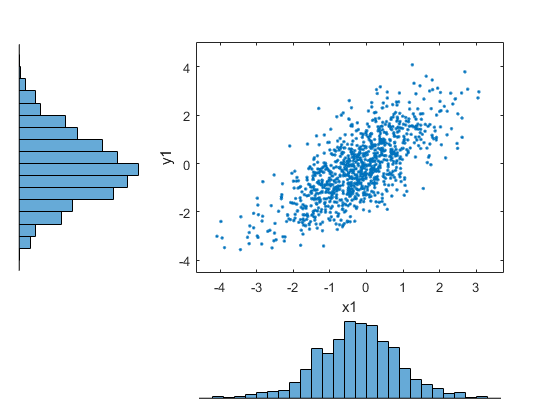
Transform the random sample back to the original scale of the data.
x1 = ksdensity(x,u1,'function','icdf'); y1 = ksdensity(y,v1,'function','icdf'); figure; scatterhist(x1,y1) set(get(gca,'children'),'marker','.')
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
By default, copulafit uses maximum likelihood
to fit a copula to u. When u contains
data transformed to the unit hypercube by parametric estimates of
their marginal cumulative distribution functions, this is known as
the Inference Functions for Margins (IFM) method.
When u contains data transformed by the empirical
cdf (see ecdf), this is known
as Canonical Maximum Likelihood (CML).
References
[1] Bouyé, E., V. Durrleman, A. Nikeghbali, G. Riboulet, and T. Roncalli. “Copulas for Finance: A Reading Guide and Some Applications.” Working Paper. Groupe de Recherche Opérationnelle, Crédit Lyonnais, Paris, 2000.
Version History
Introduced in R2007b