cluster
Construct clusters from Gaussian mixture distribution
Syntax
Description
Examples
Generate random variates that follow a mixture of two bivariate Gaussian distributions by using the mvnrnd function. Fit a Gaussian mixture model (GMM) to the generated data by using the fitgmdist function. Then, use the cluster function to partition the data into two clusters determined by the fitted GMM components.
Define the distribution parameters (means and covariances) of two bivariate Gaussian mixture components.
mu1 = [2 2]; % Mean of the 1st component sigma1 = [2 0; 0 1]; % Covariance of the 1st component mu2 = [-2 -1]; % Mean of the 2nd component sigma2 = [1 0; 0 1]; % Covariance of the 2nd component
Generate an equal number of random variates from each component, and combine the two sets of random variates.
rng('default') % For reproducibility r1 = mvnrnd(mu1,sigma1,1000); r2 = mvnrnd(mu2,sigma2,1000); X = [r1; r2];
The combined data set X contains random variates following a mixture of two bivariate Gaussian distribution.
Fit a two-component GMM to X.
gm = fitgmdist(X,2);
Plot X by using scatter. Visualize the fitted model gm by using pdf and fcontour.
figure scatter(X(:,1),X(:,2),10,'.') % Scatter plot with points of size 10 hold on gmPDF = @(x,y) arrayfun(@(x0,y0) pdf(gm,[x0 y0]),x,y); fcontour(gmPDF,[-6 8 -4 6])

Partition the data into clusters by passing the fitted GMM and the data to cluster.
idx = cluster(gm,X);
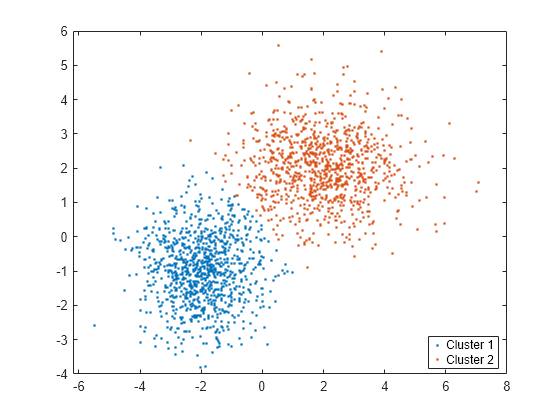
Use gscatter to create a scatter plot grouped by idx.
figure; gscatter(X(:,1),X(:,2),idx); legend('Cluster 1','Cluster 2','Location','best');
Input Arguments
Output Arguments
Version History
Introduced in R2007b