pearscdf
Syntax
Description
Examples
Define the variables mu, sigma, skew, and kurtosis, which contain values for the mean, standard deviation, skewness, and kurtosis of a Pearson distribution, respectively.
mu = 0; sigma = 2; skew = 0; kurtosis = 3;
A Pearson distribution with a skewness of 0 and kurtosis of 3 is equivalent to the normal distribution.
Create a vector X of points from –7 to 7 using the linspace function. Evaluate the cdf for the Pearson distribution given by mu, sigma, skew, and kurtosis at the points in X. Plot the result together with the cdf for the standard normal distribution.
X = linspace(-7,7,1000); Fp = pearscdf(X,mu,sigma,skew,kurtosis); Fn = normcdf(X,mu,sigma); figure hold on plot(X,Fp) plot(X,Fn) legend(["Pearson CDF" "Normal CDF"])
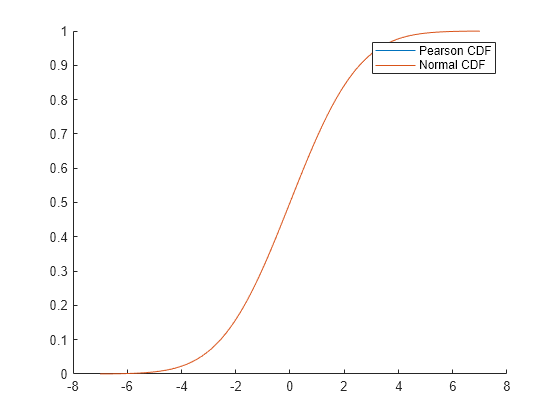
The plot shows that the blue curve for the Pearson distribution cdf is completely hidden by the red curve for the normal distribution cdf. This result indicates that the Pearson cdf is identical to the normal distribution cdf.
Define the variables mu, sigma, skew, and kurtosis, which contain values for the mean, standard deviation, skewness, and kurtosis of a Pearson distribution, respectively.
mu = 2; sigma = 1; skew = 2; kurtosis = 10;
To calculate the probability of sampling a number greater than 150 from the distribution, calculate the probability of sampling a number less than or equal to 150 and subtract it from 1.
p1 = 1 - pearscdf(150,mu,sigma,skew,kurtosis)
p1 = 0
This result shows that the probability of sampling a number less than or equal to 150 is so close to 1 that subtracting it from 1 gives 0.
To approximate the extreme upper-tail probability with greater precision, compute the complement of the Pearson cdf directly.
p2 = pearscdf(150,mu,sigma,skew,kurtosis,"upper")p2 = 1.0375e-18
The output indicates a small probability of sampling a number greater than 150.
Define the variables mu, sigma, skew, and kurtosis, which contain values for the mean, standard deviation, skewness, and kurtosis of a Pearson distribution, respectively.
mu = 2; sigma = 1; skew = 2; kurtosis = 10;
Create a vector X of points from 0 to 8 using the linspace function. Evaluate the cdf for the Pearson distribution given by mu, sigma, skew, and kurtosis at the points in X, and return the Pearson distribution type.
X = linspace(0,8,1000); [f,type] = pearscdf(X,mu,sigma,skew,kurtosis); type
type = 6
The Pearson distribution defined by mu, sigma, skew, and kurtosis is of type 6. A type 6 Pearson distribution corresponds to the F location scale distribution. In this case, the location is mu and the scale is sigma. For more information, see Pearson Distribution.
Plot the cdf for the type 6 Pearson distribution at the points in X.
plot(X,f)

The plot shows that the cdf evaluates to zero at values less than 0.8. For values greater than 0.8, the cdf increases and then follows the horizontal asymptote corresponding to a probability of 1.
Input Arguments
Output Arguments
More About
Alternative Functionality
pearscdf is a function specific to the Pearson distribution.
Statistics and Machine Learning Toolbox™ also offers the generic function cdf, which supports various probability distributions. To use
cdf, specify the probability distribution name and its
parameters.
References
[1] Johnson, Norman Lloyd, et al. "Continuous Univariate Distributions." 2nd ed, vol. 1, Wiley, 1994.
[2] Willink, R. "A Closed-Form Expression for the Pearson Type IV Distribution Function." Australian & New Zealand Journal of Statistics, vol. 50, no. 2, June 2008, pp. 199–205. https://onlinelibrary.wiley.com/doi/10.1111/j.1467-842X.2008.00508.x.
Extended Capabilities
Version History
Introduced in R2023b