识别、目标检测和语义分割
Computer Vision Toolbox™ 支持多种图像分类、目标检测、语义分割、实例分割和识别方法,包括:
深度学习和卷积神经网络 (CNN)
特征袋
模板匹配
斑点分析
Viola-Jones 算法
CNN 是一种常见的深度学习架构,它直接从图像数据中自动学习有用的特征表示。特征袋将图像特征编码成一种适合图像分类和图像检索的紧凑表示。模板匹配使用一个小图像或模板找到大图像中的匹配区域。斑点分析使用分割和斑点属性来识别感兴趣的目标。Viola-Jones 算法使用 Haar-like 特征和级联分类器来识别目标,包括脸部、鼻子和眼睛。您可以训练此分类器来识别其他目标。
类别
精选示例

Multiclass Object Detection Using YOLO v2 Deep Learning
Train a YOLO v2 multiclass object detector and evaluate object detector performance across selected classes and overlap thresholds.

使用深度学习进行语义分割
此示例说明如何使用语义分割网络来分割图像。

Perform Instance Segmentation Using Mask R-CNN
Segment individual instances of people and cars using a multiclass mask region-based convolutional neural network (R-CNN).
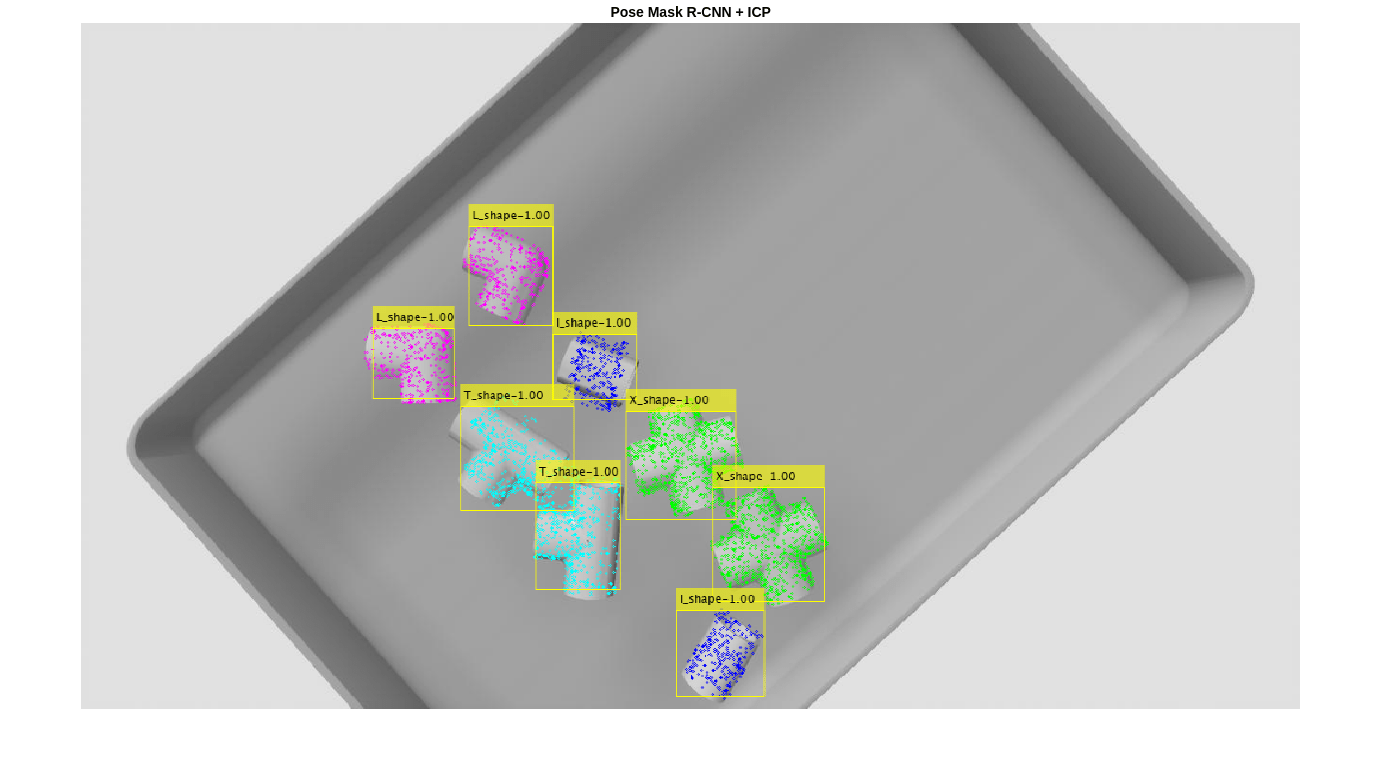
Perform 6-DoF Pose Estimation for Bin Picking Using Deep Learning
Perform six degrees-of-freedom (6-DoF) pose estimation by estimating the 3-D position and orientation of machine parts in a bin using RGB-D images and a deep learning network.
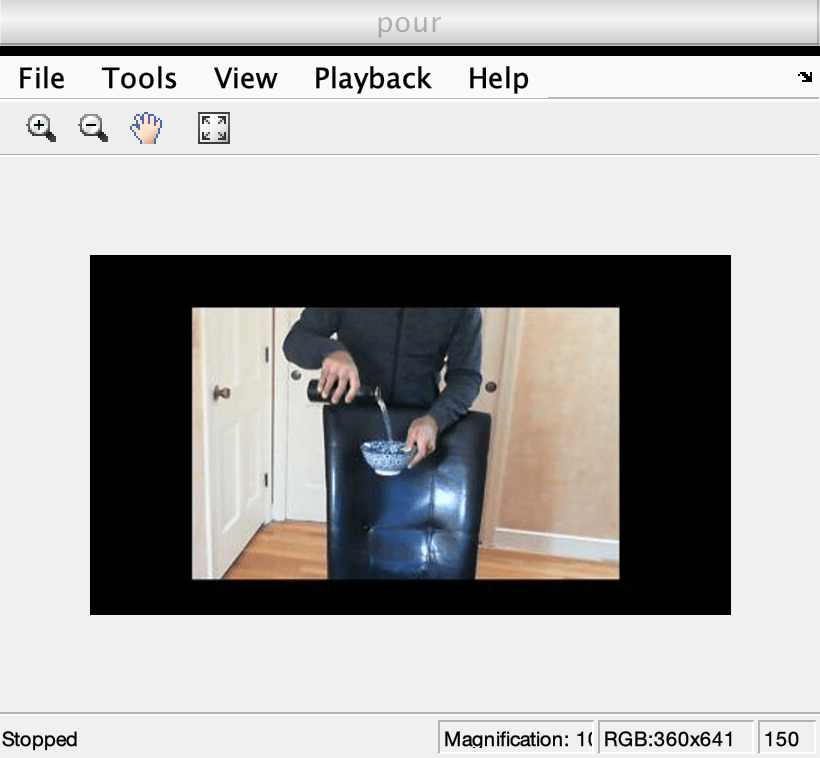
Activity Recognition from Video and Optical Flow Data Using Deep Learning
Train an inflated-3D (I3D) two-stream convolutional neural network for activity recognition using RGB and optical flow data from videos.

Automatically Detect and Recognize Text Using Pretrained CRAFT Network and OCR
Perform text recognition by using a deep learning based text detector and OCR.
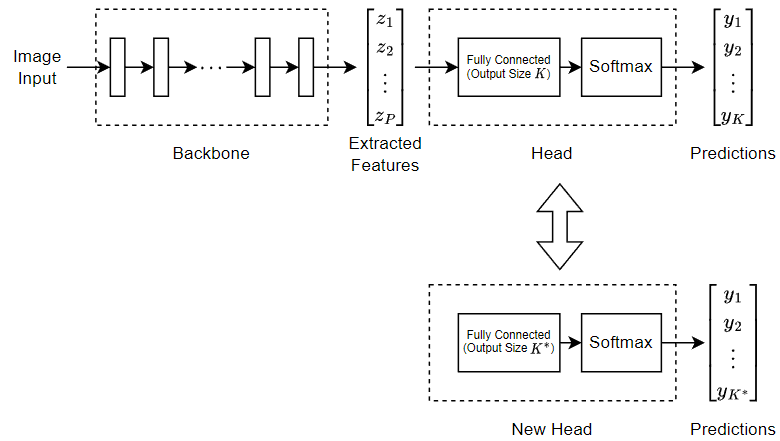
Train Vision Transformer Network for Image Classification
Fine-tune a pretrained vision transformer (ViT) neural network to perform classification on a new collection of images.

Detect Small Objects Using Tiled Training of YOLOX Network
Detect small objects in full-resolution images using tiled training of a you only look once version X (YOLOX) deep learning network.