Training Data for Object Detection and Semantic Segmentation
You can use a labeling app and Computer Vision Toolbox™ objects and functions to train algorithms from ground truth data. Use the labeling app to interactively label ground truth data in a video, image sequence, image collection, or custom data source. Then, use the labeled data to create training data to train an object detector or to train a semantic segmentation network.
This workflow applies to the Image Labeler and
Video Labeler apps
only. To create training data for the Ground Truth Labeler (Automated Driving Toolbox) app in Automated Driving Toolbox™, use the gatherLabelData (Automated Driving Toolbox) function.
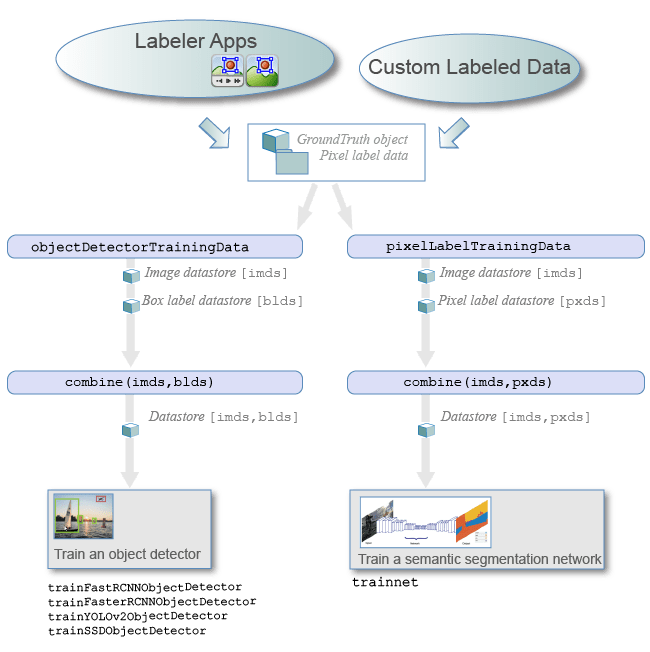
Load data for labeling
Image Labeler — Load an image collection from a file or
ImageDatastoreobject into the app.Video Labeler — Load a video, image sequence, or a custom data source into the app.
Label data and select an automation algorithm: Create ROI and scene labels within the app. For more details, see:
Image Labeler — Get Started with the Image Labeler
Video Labeler — Get Started with the Video Labeler
You can choose from one of the built-in algorithms or create your own custom algorithm to label objects in your data. To learn how to create your own automation algorithm, see Create Custom Automation Algorithm for Labeling.
Export labels: After labeling your data, you can export the labels. Use the steps outlined depending on whether you are working on a team-based or individual project:
Team-based project — To export labeled images when you are working as part of a team-based project, follow the directions outlined in Combine Reviewed Images and Export.
Individual project — You can export the labels to the workspace or save them to a file. The labels are exported as a
groundTruthobject. If your data source consists of multiple image collections, label the entire set of image collections to obtain an array ofgroundTruthobjects. For details about sharinggroundTruthobjects, see Share and Store Labeled Ground Truth Data.
Create training data: To create training data from the
groundTruthobject, use one of these functions:Training data for object detectors — Use the
objectDetectorTrainingDatafunction.Training data for semantic segmentation networks — Use the
pixelLabelTrainingDatafunction.
For objects created using a video file or custom data source, the
objectDetectorTrainingDataandpixelLabelTrainingDatafunctions write images to disk forgroundTruth. Sample the ground truth data by specifying a sampling factor. Sampling mitigates overtraining an object detector on similar samples.Train algorithm:
Object detectors — Use one of several Computer Vision Toolbox object detectors. For a list of detectors, see Object Detection. For object detectors specific to automated driving, see the Automated Driving Toolbox object detectors listed in Object and Lane Detection (Automated Driving Toolbox).
Semantic segmentation network — For details on training a semantic segmentation network, see Get Started with Semantic Segmentation Using Deep Learning.
See Also
Apps
Functions
semanticseg|objectDetectorTrainingData|trainACFObjectDetector|pixelLabelTrainingData|trainYOLOv2ObjectDetector|trainYOLOv3ObjectDetector|trainYOLOv4ObjectDetector|trainSSDObjectDetector
Objects
Topics
- Get Started with the Image Labeler
- Get Started with the Video Labeler
- Create Custom Automation Algorithm for Labeling
- Get Started with Object Detection Using Deep Learning
- Get Started with Semantic Segmentation Using Deep Learning
- Getting Started with Point Clouds Using Deep Learning
- Anchor Boxes for Object Detection