trainYOLOv3ObjectDetector
Syntax
Description
detector = trainYOLOv3ObjectDetector(trainingData,detector,options)detector. The input detector can be
an untrained or pretrained YOLO v3 object detector. The options input
specifies training parameters for the detection network.
You can also use this syntax to fine-tune a pretrained YOLO v3 object detector.
detector = trainYOLOv3ObjectDetector(trainingData,checkpoint,options)
You can use this syntax to:
Add more training data and continue training.
Improve training accuracy by increasing the maximum number of iterations.
[___] = trainYOLOv3ObjectDetector(___,
specifies options using one or more name-value arguments in addition to any combination of
arguments from previous syntaxes. For example, Name=Value)ExperimentMonitor=[]
specifies not to track metrics with Experiment Manager.
Note
This functionality requires Deep Learning Toolbox™. To use the pretrained YOLO v3 deep learning networks trained on COCO dataset, you must install the Computer Vision Toolbox™ Model for YOLO v3 Object Detection from Add-On Explorer. For more information about installing add-ons, see Get and Manage Add-Ons.
Examples
Train a pretrained YOLO v3 object detector to detect vehicles in an image. The object detector uses a tiny YOLO v3 network, trained on the COCO data set as the base network.
Load a .mat file containing training data, and extract the training data into the workspace. The training data is a table in which the first column contains the training images and the remaining columns contain the corresponding labeled bounding boxes.
data = load("vehicleTrainingData.mat");
trainingData = data.vehicleTrainingData;Specify the directory that contains the training samples. Add the full paths to the filenames in the training data.
dataDir = fullfile(toolboxdir("vision"),"visiondata"); trainingData.imageFilename = fullfile(dataDir,trainingData.imageFilename);
Create an image datastore using the files from the table.
imds = imageDatastore(trainingData.imageFilename);
Create a box label datastore using the label columns from the table.
blds = boxLabelDatastore(trainingData(:,2:end));
Combine the image and box label datastores.
ds = combine(imds,blds);
Specify the anchor boxes to use for training the network. You must assign at least one anchor box to each output layer of the network. Because the tiny YOLO v3 network contains two output layers, specify the anchor boxes as a two-element cell array.
anchorBoxes = {[91 115; 82 106; 58 83];[41 58; 24 32;19 23]};Specify the names of the classes to detect.
classes = {'vehicle'};Create a pretrained YOLO v3 deep learning network configured to retrain on the new dataset by using the yolov3ObjectDetector function.
detector = yolov3ObjectDetector("tiny-yolov3-coco",classes,anchorBoxes);
detector.Networkans =
dlnetwork with properties:
Layers: [44×1 nnet.cnn.layer.Layer]
Connections: [45×2 table]
Learnables: [48×3 table]
State: [22×3 table]
InputNames: {'input'}
OutputNames: {'convOut1' 'convOut2'}
Initialized: 1
View summary with summary.
Specify the training options.
options = trainingOptions("adam", ... InitialLearnRate=0.001, ... MiniBatchSize=8, ... MaxEpochs=30, ... BatchNormalizationStatistics="moving", ... ResetInputNormalization=false, ... VerboseFrequency=30);
Retrain the pretrained YOLO v3 network on the new data set by using the trainYOLOv3ObjectDetector function.
trainedDetector = trainYOLOv3ObjectDetector(ds,detector,options);
*************************************************************************
Training a YOLO v3 Object Detector for the following object classes:
* vehicle
Epoch Iteration TimeElapsed LearnRate TrainingLoss
_____ _________ ___________ _________ ____________
1 30 00:00:39 0.001 27.477
2 60 00:01:21 0.001 12.281
3 90 00:01:59 0.001 7.3423
4 120 00:02:36 0.001 5.5316
5 150 00:03:13 0.001 4.6442
5 180 00:03:50 0.001 3.532
6 210 00:04:27 0.001 5.46
7 240 00:05:04 0.001 3.7652
8 270 00:05:41 0.001 2.0736
9 300 00:06:18 0.001 2.8613
9 330 00:06:54 0.001 2.1912
10 360 00:07:31 0.001 1.7878
11 390 00:08:08 0.001 1.6713
12 420 00:08:44 0.001 1.0196
13 450 00:09:20 0.001 1.4047
13 480 00:09:57 0.001 1.2047
14 510 00:10:33 0.001 1.0924
15 540 00:11:10 0.001 1.0899
16 570 00:11:47 0.001 0.80751
17 600 00:12:23 0.001 0.77776
18 630 00:12:59 0.001 0.92279
18 660 00:13:36 0.001 0.6374
19 690 00:14:12 0.001 0.64517
20 720 00:14:49 0.001 0.52645
21 750 00:15:26 0.001 0.61458
22 780 00:16:03 0.001 0.65221
22 810 00:16:39 0.001 0.69775
23 840 00:17:16 0.001 0.51352
24 870 00:17:52 0.001 0.82176
25 900 00:18:29 0.001 0.86924
26 930 00:19:05 0.001 0.887
26 960 00:19:42 0.001 0.57564
27 990 00:20:18 0.001 0.40471
28 1020 00:20:55 0.001 0.37672
29 1050 00:21:31 0.001 0.28895
30 1080 00:22:07 0.001 0.54886
30 1110 00:22:44 0.001 0.4914
*************************************************************************
Detector training complete.
*************************************************************************
Read a test image. Use the trained YOLO v3 object detector to detect vehicles and display the detection results.
I = imread('highway.png');
[bboxes, scores, labels] = detect(trainedDetector,I,Threshold=0.05);
results = table(bboxes,labels,scores)results=2×3 table
131 73 107 83 vehicle 0.1546
93 84 44 73 vehicle 0.1259
detectedImg = insertObjectAnnotation(I,"Rectangle",bboxes,labels,LineWidth=3,AnnotationColor="cyan"); figure imshow(detectedImg)

Perform transfer learning to fine-tune a pretrained YOLO v3 object detector by freezing its backbone. The detector has been trained for detecting stop signs and the front views and rear views of cars in an image. The detector uses a DarkNet-53 network, trained on the COCO data set, as the base network.
Load a .mat file containing training data, and extract the training data into the workspace. The training data is a table in which the first column contains the training images and the remaining columns contain the corresponding labeled bounding boxes.
data = load("stopSignsAndCars.mat");
trainingData = data.stopSignsAndCars;Specify the directory that contains the training samples. Add the full paths to the filenames in the training data.
dataDir = fullfile(toolboxdir("vision"),"visiondata"); trainingData.imageFilename = fullfile(dataDir,trainingData.imageFilename);
Create an image datastore using the files from the table.
imds = imageDatastore(trainingData.imageFilename);
Create a box label datastore using the label columns from the table.
blds = boxLabelDatastore(trainingData(:,2:end));
Combine the image and box label datastores.
ds = combine(imds,blds);
Specify the input size to use for resizing the training images. You must also resize the bounding boxes based on the specified input size.
inputSize = [224 224 3];
Resize and rescale the training images and bounding boxes by using the preprocessData helper function. Convert the preprocessed data to a datastore object by using the transform function.
trainingDataForEstimation = transform(ds,@(data)preprocessData(data,inputSize));
Specify the anchor boxes to use for training the network. You must assign at least one anchor box to each output layer of the network. Because the darknet53-coco YOLO v3 network contains three output layers, specify the anchor boxes as a three-element cell array.
numAnchors = 9; [anchors,meanIoU] = estimateAnchorBoxes(trainingDataForEstimation,numAnchors);
Use larger anchor boxes at lower scale and smaller anchor boxes at higher scale output layers. To do so, sort anchors by area, in descending order, and assign the first three to the first output layer, the next three to the second output layer, and the last three to the third output layer of the network.
area = anchors(:,1).*anchors(:,2);
[~,idx] = sort(area,"descend");
anchors = anchors(idx,:);
anchorBoxes = {anchors(1:3,:); anchors(4:6,:); anchors(7:9,:)};Specify the names of the classes to detect.
classes = {'stopSign','carRear','carFront'};Create a pretrained YOLO v3 deep learning network configured to retrain on the new dataset by using the yolov3ObjectDetector function.
detector = yolov3ObjectDetector("darknet53-coco",classes,anchorBoxes,InputSize=inputSize);
detector.Networkans =
dlnetwork with properties:
Layers: [247×1 nnet.cnn.layer.Layer]
Connections: [273×2 table]
Learnables: [294×3 table]
State: [144×3 table]
InputNames: {'input'}
OutputNames: {'convOut1' 'convOut2' 'convOut3'}
Initialized: 1
View summary with summary.
Specify the training options.
options = trainingOptions("sgdm", ... InitialLearnRate=0.0001, ... MiniBatchSize=4, ... MaxEpochs=30, ... BatchNormalizationStatistics="moving", ... ResetInputNormalization=false, ... VerboseFrequency=30);
Retrain the pretrained YOLO v3 network on the new data set by using the trainYOLOv3ObjectDetector function. To freeze the backbone of the pretrained YOLO v3 network during training, specify the FreezeSubNetwork name-value argument to "backbone". The weights of the frozen backbone layers do not change during training, which increases training speed and reduces GPU memory consumption.
trainedDetector = trainYOLOv3ObjectDetector(ds,detector,options,FreezeSubNetwork="backbone");*************************************************************************
Training a YOLO v3 Object Detector for the following object classes:
* stopSign
* carRear
* carFront
Epoch Iteration TimeElapsed LearnRate TrainingLoss
_____ _________ ___________ _________ ____________
3 30 00:00:30 0.0001 35.9
6 60 00:00:58 0.0001 4.8118
9 90 00:01:26 0.0001 2.5195
11 120 00:01:54 0.0001 2.5046
14 150 00:02:22 0.0001 2.4547
17 180 00:02:50 0.0001 2.8295
20 210 00:03:19 0.0001 4.031
22 240 00:03:47 0.0001 0.76425
25 270 00:04:16 0.0001 0.86645
28 300 00:04:44 0.0001 1.7476
30 330 00:05:13 0.0001 0.7068
*************************************************************************
Detector training complete.
*************************************************************************
Read a test image. Use the fine-tuned YOLO v3 object detector to detect the stop signs and the front views and rear views of cars, and display the detection results.
I = imread("Test_Image.jpg"); [bboxes,scores,labels] = detect(trainedDetector,I,Threshold=0.2); detectedImg = insertObjectAnnotation(I,"Rectangle",bboxes,labels,LineWidth=3,AnnotationColor="cyan"); results = table(bboxes,labels,scores)
results=3×3 table
88 388 124 65 carFront 0.3984
430 366 102 87 carRear 0.7215
795 293 65 58 stopSign 0.9798
figure imshow(detectedImg)

Supporting Function
function data = preprocessData(data,targetSize) for num = 1:size(data,1) I = data{num,1}; imgSize = size(I); bboxes = data{num,2}; I = im2single(imresize(I,targetSize(1:2))); scale = targetSize(1:2)./imgSize(1:2); bboxes = bboxresize(bboxes,scale); data(num,1:2) = {I bboxes}; end end
Input Arguments
Labeled ground truth images, specified as a datastore. Data must be set up so that
calling the datastore with the read and readall functions returns a cell array or
table with three columns in the format {data
boxes
labels}.
The first column, data, must contain the image data, stored as a cell array. The second column, boxes, must contain the bounding boxes, stored as a matrix with dimensions determined by the type of bounding box. The third column, labels, must be a cell array in which each cell contains an M-by-1 categorical vector of object class names, where M is the number of bounding boxes. All the categorical data returned by the datastore must use the same categories.
This table describes the format of each element of the bounding boxes column.
| Bounding Box | Description |
|---|---|
Axis-aligned rectangle |
Defined in spatial coordinates as an M-by-4 numeric matrix with rows of the form [x y w h], where:
|
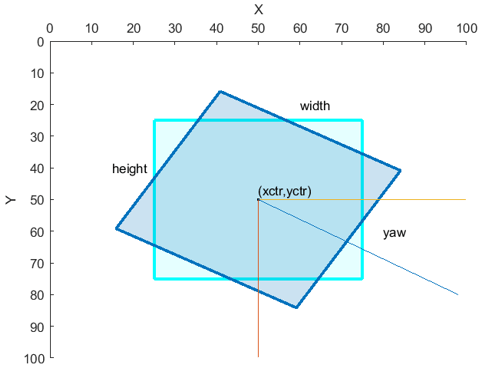
Rotated rectangle |
Defined in spatial coordinates as an M-by-5 numeric matrix with rows of the form [xctr yctr w h yaw], where:
|
For more information, see Datastores for Deep Learning (Deep Learning Toolbox).
Note
You can convert a pretrained, axis-aligned network to a rotated rectangle
network by providing rotated rectangle training data. When you provide the rotated
rectangle training data, the trainYOLOv3ObjectDetector function
fine-tunes the network, enabling the rotated rectangle detections.
Pretrained or untrained YOLO v3 object detector, specified as a yolov3ObjectDetector object.
Training options, specified as a TrainingOptionsSGDM,
TrainingOptionsRMSProp, or TrainingOptionsADAM
object returned by the trainingOptions (Deep Learning Toolbox) function. To specify the
solver name and other options for network training, use the
trainingOptions function. You must set the
BatchNormalizationStatistics property of the object to
"moving".
Saved detector checkpoint, specified as a yolov3ObjectDetector object. To periodically save a detector checkpoint
during training as a MAT file, specify a location for the file using the
CheckpointPath property of the training options object
options. To control how frequently the detector saves
checkpoints, use the CheckPointFrequency and
CheckPointFrequencyUnit properties of the training options
object.
To load a checkpoint for a previously trained detector, load the MAT file from the
checkpoint path. For example, this code loads the checkpoint MAT file of a detector from
the "checkpath" folder in the current working directory to which the
detector saves checkpoints during training.
data = load("checkpath/net_checkpoint__6__2023_11_17__16_03_08.mat");
checkpoint = data.net;The name of each MAT file includes the iteration number and timestamp at which the
detector saves the checkpoint. The file stores the detector in the
net variable. To continue training the network, specify the
detector extracted from the file to the trainYOLOv3ObjectDetector
function:
yoloDetector = trainYOLOv3ObjectDetector(trainingData,checkpoint,options);
Name-Value Arguments
Output Arguments
Tips
To generate the ground truth, use the Image Labeler or Video Labeler app. To create a table of training data from the generated ground truth, use the
objectDetectorTrainingDatafunction.Use these processes to improve prediction accuracy:
Increase the number of images you use to train the network. You can expand the training data set through data augmentation. For information on how to apply data augmentation for preprocessing, see Preprocess Images for Deep Learning (Deep Learning Toolbox).
Choose anchor boxes appropriate to the training dataset. You can use the
estimateAnchorBoxesfunction to compute anchor boxes directly from the training data.
When you train a rotated rectangle bounding box detector, use a learning rate approximately one order of magnitude below that of its axis-aligned counterpart.
When you perform transfer learning using a YOLO v3 object detector, consider freezing the subnetworks using the
FreezeSubNetworkname-value argument to increase training speed and reduce GPU memory consumption.
Extended Capabilities
Version History
Introduced in R2024aSee Also
Apps
Functions
trainingOptions(Deep Learning Toolbox) |objectDetectorTrainingData|trainYOLOv2ObjectDetector|trainYOLOv4ObjectDetector