Datastores for Deep Learning
You can use datastore objects to access and modify your deep learning data sets. If you are already familiar with datastores and just want to select the right datastore for your application, see Select Datastore. To learn how to speed up deep learning tasks that use datastores, see Optimize Datastores for Deep Learning Performance.
What Is a Datastore?
A datastore is an object for reading a single file or a collection of files or data. The properties of a datastore describe the data and specify how to read the data from the datastore.
The advantages of using datastores to work with deep learning data sets include:
Reduced memory usage — Creating a datastore does not load your data into memory. Because the software only loads the data into memory when it needs it, you can use larger data sets without running out of memory.
Convenient batching — Datastores make it easy to iterate over your data in mini-batches.
Reduced amount of code to write — Instead of writing code that loads, transforms, partitions, and combines your data sets, you can use built-in datastore convenience functions.
Directly loading your data into MATLAB® might be appropriate when working with a very small data set, but for larger data sets and more complex networks such as networks with multiple inputs or outputs, use a datastore.
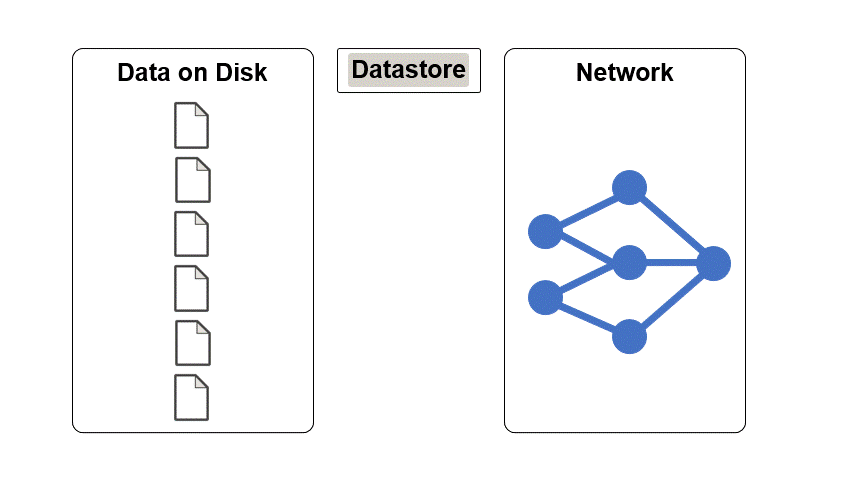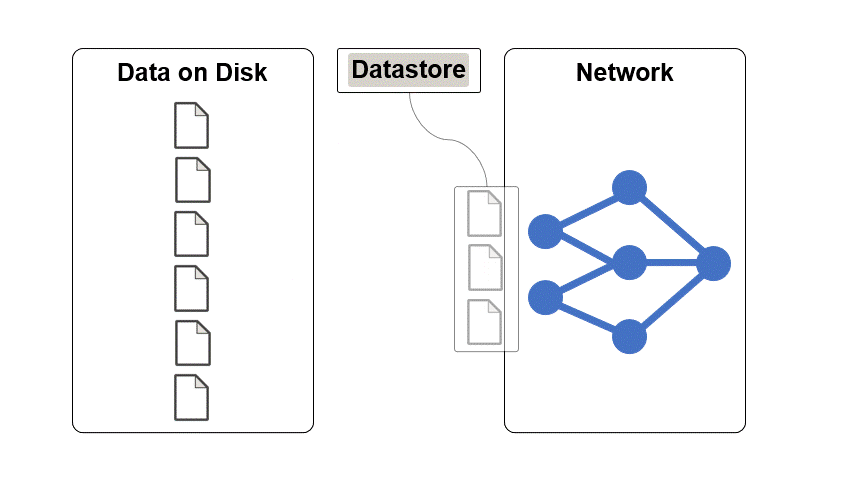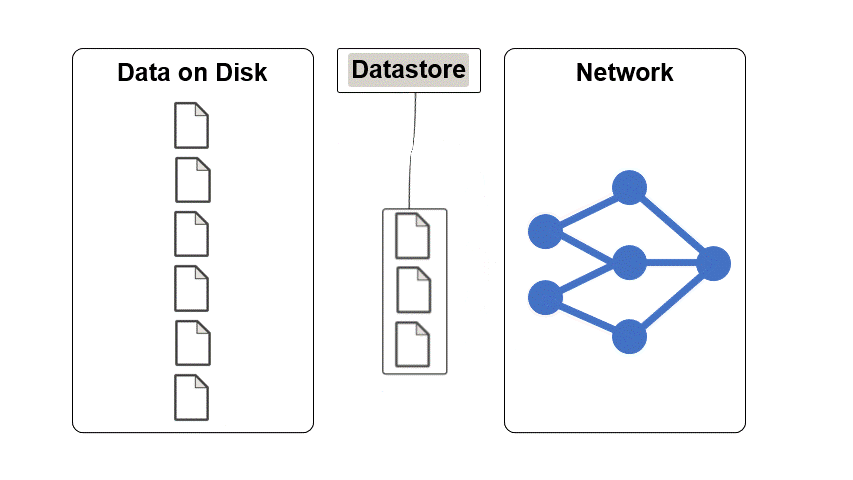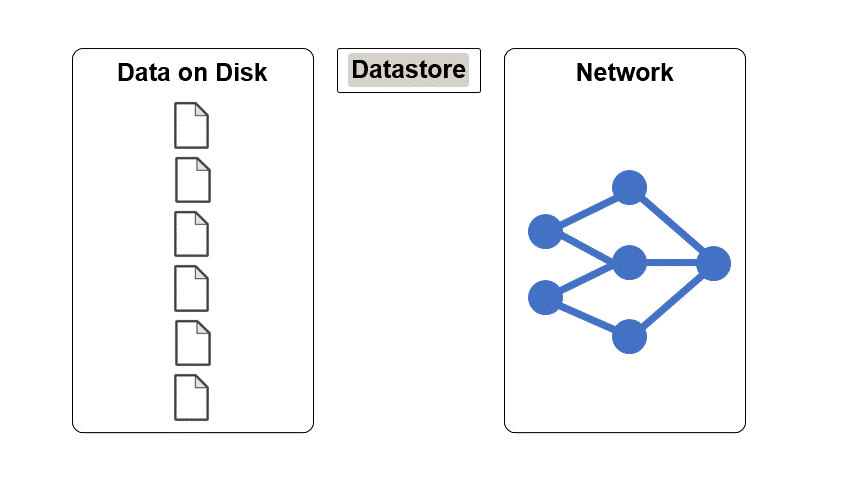
How to Create and Read from Datastores
Choose the data that you want to use for deep learning. This code downloads the Omniglot training data set, which contains images showing handwritten characters from 50 alphabets [1].
downloadFolder = tempdir; url = "https://github.com/brendenlake/omniglot/raw/master/python/images_background.zip"; filename = fullfile(downloadFolder,"images.zip"); dataFolder = fullfile(downloadFolder,"images_background"); if ~exist(dataFolder,"dir") fprintf("Downloading Omniglot training data set (4.5 MB)... ") websave(filename,url) unzip(filename,downloadFolder) fprintf("Done.\n") end
Create an imageDatastore object that includes all
files and subfolders within dataFolder. If you have another type of
data, choose another built-in datastore. For more information, see Select Datastore.
imds = imageDatastore(dataFolder,IncludeSubfolders=true);
To verify that the datastore can access the images, read an image from the datastore
using the read function, and display it.
I = read(imds); imshow(I)
Subsequent calls to read continue reading from the endpoint of
the previous call. To reset the datastore to the state where no data has been read from
it, use the reset function.
reset(imds)
Use Datastores for Training, Validation, and Inference
Datastores are valid inputs for training, validation, and inference.
Training and Validation
You can use a datastore as a source of training data when training using the
trainnet function. To use a datastore for validation, specify the
ValidationDatatrainingOptions function.
For a datastore to be a valid input for training or validation, the read function of the datastore must
return data as either a cell array or a table (with the exception of
ImageDatastore objects, which can output numeric arrays, and
custom mini-batch datastores, which must output tables).
For networks with a single input, the table or cell array returned by the
datastore must have two columns. The first column of data represents inputs to the
network (predictors) and the second column of data represents the training targets.
Each row of data represents a separate observation. For
ImageDatastore only, trainnet and
trainingOptions support data returned as integer arrays and
single-column cell arrays of integer arrays.
data = read(ds)
data =
4×2 cell array
{224×224×3 double} {[2]}
{224×224×3 double} {[7]}
{224×224×3 double} {[9]}
{224×224×3 double} {[9]}Most built-in datastores output data in the layout that the network expects. If
you are training your network using the trainnet function and
your data is in a different layout than what the network expects, then indicate that
your data has a different layout by using the InputDataFormats
and TargetDataFormats arguments of the trainingOptions function. Adjusting these options is usually easier
than preprocessing the input and target data.
For example, if you have sequence data with rows and columns corresponding to
channels and time steps, respectively, specify the input data format as
"CTB" (channel, time, batch).
trainingOptions("adam", ... InputDataFormats="CTB");
For more information about the data layouts required by the
trainnet function, see Datastore Customization.
Prediction
For inference using the minibatchpredict function, the datastore is valid as long as the read
function of the datastore returns columns corresponding to the predictors. The
minibatchpredict function uses the first
numInputs columns and ignores the subsequent columns, where
numInputs is the number of network input layers.
Transform Datastores
A transformed datastore applies a particular data transformation to an underlying
datastore when reading data. To create a transformed datastore, use the transform
function, and specify the underlying datastore and the transformation.
For simple transformations that you can express in one line of code, you can specify a
handle to an anonymous function as the @fcn
argument of transform. For more information, see Anonymous Functions. For example, you can use the
transform function to create a transformed datastore that
applies the imresize
function to resize images when you read them from the datastore.
imageSize = [244 244]; tds = transform(imds,@(I) imresize(I,imageSize))
For more complex transformations involving several preprocessing operations, define
the complete set of transformations in your own function. Then, specify a handle to your
function as the @fcn
argument of transform. For an example showing how to apply a custom
preprocessing function using the transform function, see Prepare Datastore for Image-to-Image Regression.
The function handle provided to transform must accept input data in
the same format as returned by the read function of the underlying
datastore.
Combine Datastores
The combine
function associates multiple datastores with each other. Calling the
read function of a combined datastore reads one batch of data
from all of the N underlying datastores, which must return the same
number of observations. Reading from a combined datastore returns the horizontally
concatenated results in an N-column cell array that is suitable for
training and validation.
For example, if you are training an image-to-image regression network, then you can
create the training data set by combining two image datastores. This sample code
demonstrates combining two image datastores named imdsX and
imdsY. The combined datastore imdsTrain
returns data as a two-column cell array.
imdsTrain = combine(imdsX,imdsY); images = read(imdsTrain)
images =
1×2 cell array
{105×105 logical} {105×105 logical}For an example showing how to combine datastores using the
combine function, see Train Network Using Out-of-Memory Sequence Data.
Train Networks with Multiple Inputs or Outputs Using Datastores
To train a network with multiple input layers or multiple outputs, use the
combine and transform functions to create a
datastore that outputs a cell array with (numInputs +
numOutputs) columns, where numInputs is the number
of network inputs and numOutputs is the number of network outputs. The
first numInputs columns specify the predictors for each input, and the
last numOutputs columns specify the responses. The
InputNames and OutputNames properties of the
neural network determine the order of the inputs and outputs, respectively.
This table shows example outputs of calling the read function for
a datastore, ds.
| Neural Network Architecture | Datastore Output | Example Cell Array Output | Example Table Output |
|---|---|---|---|
| Single input layer and single output | Table or cell array with two columns. The first and second columns specify the predictors and targets, respectively. Table elements must be scalars, row vectors, or 1-by-1 cell arrays containing a numeric array. Custom mini-batch datastores must output tables. | Cell array for neural network with one input and one output: data = read(ds) data =
4×2 cell array
{224×224×3 double} {[2]}
{224×224×3 double} {[7]}
{224×224×3 double} {[9]}
{224×224×3 double} {[9]} | Table for neural network with one input and one output: data = read(ds) data =
4×2 table
Predictors Response
__________________ ________
{224×224×3 double} 2
{224×224×3 double} 7
{224×224×3 double} 9
{224×224×3 double} 9
|
| Multiple input layers or multiple outputs | Cell array with ( The first The order of inputs and outputs are
given by the | Cell array for neural network with two inputs and two outputs. data = read(ds) data =
4×4 cell array
{224×224×3 double} {128×128×3 double} {[2]} {[-42]}
{224×224×3 double} {128×128×3 double} {[2]} {[-15]}
{224×224×3 double} {128×128×3 double} {[9]} {[-24]}
{224×224×3 double} {128×128×3 double} {[9]} {[-44]} | Not supported |
For an example showing how to train a network with multiple inputs using a combined datastore, see Train Network on Image and Feature Data. For more information about networks with multiple inputs and outputs, see Multiple-Input and Multiple-Output Networks.
Select Datastore
For many applications, the easiest approach is to start with a built-in datastore. For more information about the available built-in datastores, see Select Datastore for File Format or Application. However, you can use only some types of built-in datastores as direct input for network training, validation, and inference.
| Datastore | Description | Examples |
|---|---|---|
ImageDatastore | Datastore for image data | |
augmentedImageDatastore | Datastore for resizing and augmenting training images Datastore is nondeterministic | |
PixelLabelDatastore (Computer Vision Toolbox) | Datastore for pixel label data | |
boxLabelDatastore (Computer Vision Toolbox) | Datastore for bounding box label data |
|
randomPatchExtractionDatastore (Image Processing Toolbox) | Datastore for extracting random patches from image-based data Datastore is nondeterministic |
|
blockedImageDatastore (Image Processing Toolbox) | Datastore for blockwise reading and processing of image data, including large images that do not fit in memory |
|
blockedPointCloudDatastore (Lidar Toolbox) | Datastore for blockwise reading and processing of point cloud data, including large point clouds that do not fit in memory | |
denoisingImageDatastore (Image Processing Toolbox) | Datastore to train an image denoising deep neural network Datastore is nondeterministic |
|
audioDatastore (Audio Toolbox) | Datastore for audio data | |
signalDatastore (Signal Processing Toolbox) | Datastore for signal data |
|
You can use other built-in datastores as input for deep learning, but
you must preprocess the data read from these datastores into a format required by a deep
learning network. With the built-in datastores and the transform
and combine functions, you can use datastores for the majority of
your deep learning training and prediction tasks. For more information on the required
format of read data, see Datastore Customization, and for more
information on how to preprocess data read from datastores, see Transform Datastores and Combine Datastores.
For some applications, there may not be a built-in datastore type that fits your data
well. In these cases, you can create a custom datastore. For more information, see Develop Custom Datastore. All custom datastores are valid inputs to deep
learning interfaces as long as the read function of the custom
datastore returns data in the required form.
Quantization supports many of the built-in datastores. For more information, see Prepare Data for Quantizing Networks.
References
[1] Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. “Human-Level Concept Learning through Probabilistic Program Induction.” Science 350, no. 6266 (December 11, 2015): 1332–38. https://doi.org/10.1126/science.aab3050.
See Also
transform | combine | read | trainnet | trainingOptions | dlnetwork