使用卷积神经网络对文本数据进行分类
此示例说明如何使用卷积神经网络对文本数据进行分类。
要使用卷积对文本数据进行分类,请使用在输入的时间维度上进行卷积的一维卷积层。
此示例训练具有不同宽度的一维卷积滤波器的网络。每个滤波器的宽度对应于滤波器可以检测到的单词数(n 元分词长度)。网络有多个卷积层分支,因此它可以使用不同 n 元分词长度。
加载数据
根据 factoryReports.csv 中的数据创建一个表格文本数据存储,并查看前几个报告。
data = readtable("factoryReports.csv");
head(data) Description Category Urgency Resolution Cost
_______________________________________________________________________ ______________________ __________ ______________________ _____
{'Items are occasionally getting stuck in the scanner spools.' } {'Mechanical Failure'} {'Medium'} {'Readjust Machine' } 45
{'Loud rattling and banging sounds are coming from assembler pistons.'} {'Mechanical Failure'} {'Medium'} {'Readjust Machine' } 35
{'There are cuts to the power when starting the plant.' } {'Electronic Failure'} {'High' } {'Full Replacement' } 16200
{'Fried capacitors in the assembler.' } {'Electronic Failure'} {'High' } {'Replace Components'} 352
{'Mixer tripped the fuses.' } {'Electronic Failure'} {'Low' } {'Add to Watch List' } 55
{'Burst pipe in the constructing agent is spraying coolant.' } {'Leak' } {'High' } {'Replace Components'} 371
{'A fuse is blown in the mixer.' } {'Electronic Failure'} {'Low' } {'Replace Components'} 441
{'Things continue to tumble off of the belt.' } {'Mechanical Failure'} {'Low' } {'Readjust Machine' } 38
将数据划分为训练分区和验证分区。将 80% 的数据用于训练,其余的数据用于验证。
cvp = cvpartition(data.Category,Holdout=0.2); dataTrain = data(training(cvp),:); dataValidation = data(test(cvp),:);
预处理文本数据
从表的 "Description" 列中提取文本数据,并使用示例的预处理文本函数一节中列出的 preprocessText 函数对其进行预处理。
documentsTrain = preprocessText(dataTrain.Description);
从 "Category" 列中提取标签,并将其转换为分类。
TTrain = categorical(dataTrain.Category);
查看类名称和观测值数目。
classNames = unique(TTrain)
classNames = 4×1 categorical array
"Electronic Failure"
"Leak"
"Mechanical Failure"
"Software Failure"
numObservations = numel(TTrain)
numObservations = 384
使用相同的步骤提取和预处理验证数据。
documentsValidation = preprocessText(dataValidation.Description); TValidation = categorical(dataValidation.Category);
将文档转换为序列
要将文档输入到神经网络中,请使用单词编码将文档转换为数值索引序列。
从文档创建单词编码。
enc = wordEncoding(documentsTrain);
查看单词编码的词汇量。词汇量是单词编码中具有唯一行的单词的数量。
numWords = enc.NumWords
numWords = 438
使用 doc2sequence 函数将文档转换为整数序列。
XTrain = doc2sequence(enc,documentsTrain);
使用从训练数据创建的单词编码将验证文档转换为序列。
XValidation = doc2sequence(enc,documentsValidation);
定义网络架构
为分类任务定义网络架构。
以下步骤说明如何定义网络架构。
将输入大小指定为 1,它对应于整数序列输入的通道维度。
使用维度为 100 的单词嵌入来嵌入输入。
对于 n 元分词长度 2、3、4 和 5,创建包含卷积层、批量归一化层、ReLU 层、丢弃层和最大池化层的层模块。
对于每个模块,指定 200 个大小为 1×N 的卷积滤波器和一个全局最大池化层。
将输入层连接到每个模块,并使用串联层串联各模块的输出。
要对输出进行分类,请包括一个输出大小为 K 的全连接层和一个 softmax 层,其中 K 是类的数量。
指定网络超参数。
embeddingDimension = 100; ngramLengths = [2 3 4 5]; numFilters = 200;
首先,创建一个包含输入层和一个维度为 100 的单词嵌入层的 dlnetwork 对象。为了帮助将单词嵌入层连接到卷积层,请将单词嵌入层名称设置为 "emb"。要检查卷积层在训练期间不将序列卷积为零长度,请将 MinLength 选项设置为训练数据中最短序列的长度。
net = dlnetwork;
minLength = min(doclength(documentsTrain));
layers = [
sequenceInputLayer(1,MinLength=minLength)
wordEmbeddingLayer(embeddingDimension,numWords,Name="emb")];
net = addLayers(net,layers);对于每个 n 元分词长度,创建一个由一维卷积层、批量归一化层、ReLU 层、丢弃层和一维全局最大池化层构成的模块。将每个模块连接到单词嵌入层。
numBlocks = numel(ngramLengths); for j = 1:numBlocks N = ngramLengths(j); block = [ convolution1dLayer(N,numFilters,Name="conv"+N,Padding="same") batchNormalizationLayer(Name="bn"+N) reluLayer(Name="relu"+N) dropoutLayer(0.2,Name="drop"+N) globalMaxPooling1dLayer(Name="max"+N)]; net = addLayers(net,block); net = connectLayers(net,"emb","conv"+N); end
添加串联层、全连接层和 softmax 层。
numClasses = numel(classNames);
layers = [
concatenationLayer(1,numBlocks,Name="cat")
fullyConnectedLayer(numClasses,Name="fc")
softmaxLayer(Name="soft")];
net = addLayers(net,layers);将全局最大池化层连接到串联层,并在绘图中查看网络架构。
for j = 1:numBlocks N = ngramLengths(j); net = connectLayers(net,"max"+N,"cat/in"+j); end figure plot(net) title("Network Architecture")
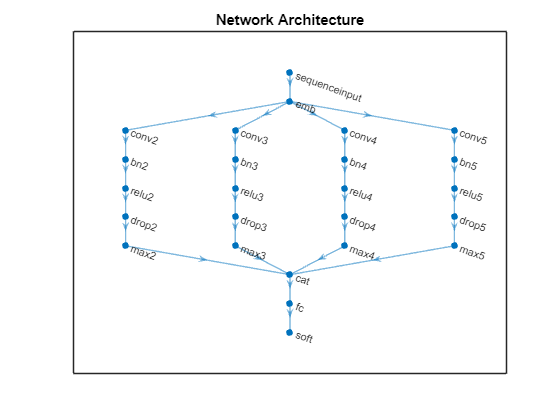
训练网络
指定训练选项:
使用小批量大小 128 进行训练。默认情况下,
trainnet函数使用 GPU(如果有)。在 GPU 上进行训练需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,trainnet函数使用 CPU。要指定执行环境,请使用ExecutionEnvironment训练选项。使用验证数据验证网络。
返回验证损失最低的网络。
在图中监控训练进度并监控准确度度量。
隐藏详细输出。
由于训练数据具有行和列分别对应于通道和时间步的序列,请指定输入数据格式
"CTB"(通道、时间、批量)。
options = trainingOptions("adam", ... MiniBatchSize=128, ... ValidationData={XValidation,TValidation}, ... OutputNetwork="best-validation", ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false, ... InputDataFormats='CTB');
使用 trainnet 函数训练网络。
net = trainnet(XTrain,TTrain,net,"crossentropy",options);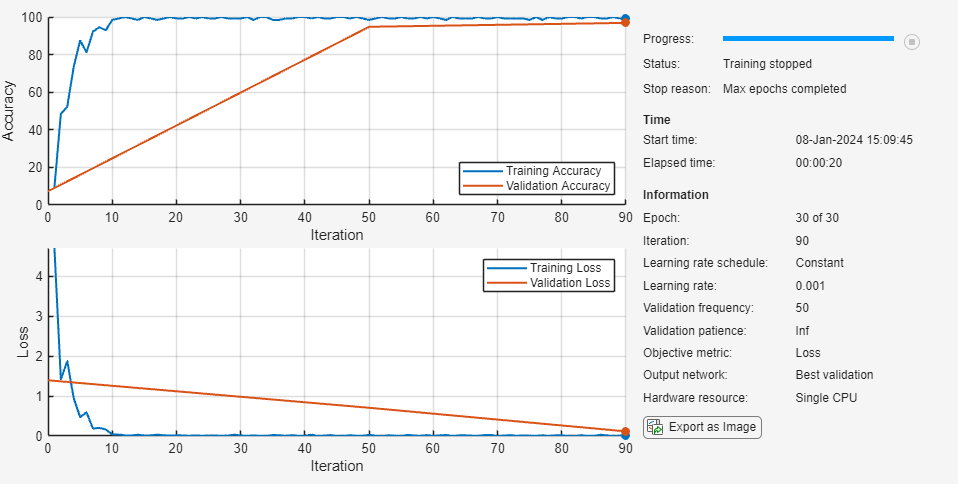
测试网络
使用神经网络进行预测。要使用多个观测值进行预测,请使用 minibatchpredict 函数。要将预测分数转换为标签,请使用 scores2label 函数。minibatchpredict 函数自动使用 GPU(如果有)。使用 GPU 需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,该函数使用 CPU。
由于数据具有行和列分别对应于通道和时间步的序列,请指定输入数据格式 "CTB"(通道、时间、批量)。
scores = minibatchpredict(net,XValidation,InputDataFormats="CTB");
YValidation = scores2label(scores,classNames);在混淆图中可视化预测。
figure confusionchart(TValidation,YValidation)
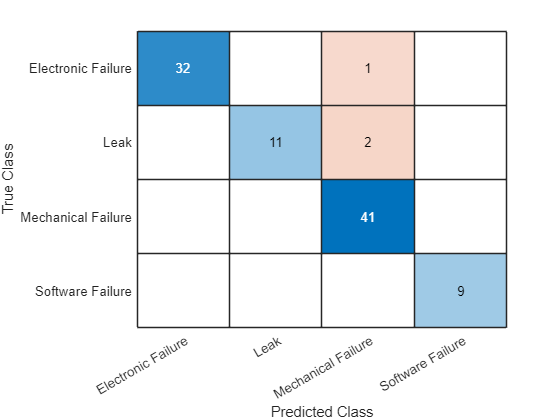
计算分类准确度。准确度是预测正确的标签的比例。
accuracy = mean(TValidation == YValidation)
accuracy = 0.9688
使用新数据进行预测
对三个新报告的事件类型进行分类。创建包含新报告的字符串数组。
reportsNew = [
"Coolant is pooling underneath sorter."
"Sorter blows fuses at start up."
"There are some very loud rattling sounds coming from the assembler."];使用与预处理训练和验证文档相同的步骤来预处理文本数据。
documentsNew = preprocessText(reportsNew); XNew = doc2sequence(enc,documentsNew);
使用经过训练的网络对新序列进行分类。
scores = minibatchpredict(net,XNew,InputDataFormats="CTB");
YNew = scores2label(scores,classNames)YNew = 3×1 categorical array
"Leak"
"Electronic Failure"
"Mechanical Failure"
预处理文本函数
preprocessTextData 函数接受文本数据作为输入并执行以下步骤:
对文本进行分词。
将文本转换为小写。
function documents = preprocessText(textData) documents = tokenizedDocument(textData); documents = lower(documents); end
另请参阅
trainnet | trainingOptions | dlnetwork | convolution2dLayer | batchNormalizationLayer | doc2sequence (Text Analytics Toolbox) | tokenizedDocument (Text Analytics Toolbox)
主题
- Classify Text Data Using Deep Learning (Text Analytics Toolbox)
- Create Simple Text Model for Classification (Text Analytics Toolbox)
- Analyze Text Data Using Topic Models (Text Analytics Toolbox)
- Analyze Text Data Using Multiword Phrases (Text Analytics Toolbox)
- Train a Sentiment Classifier (Text Analytics Toolbox)
- 使用深度学习进行序列分类
- Datastores for Deep Learning
- 在 MATLAB 中进行深度学习