semanticseg
Semantic image segmentation using deep learning
Syntax
Description
pxds = semanticseg(ds,network)ds, a datastore object.
The function supports parallel computing using multiple MATLAB® workers. You can enable parallel computing using the Computer Vision Toolbox Preferences dialog.
[___] = semanticseg(___,
specifies options using one or more name-value arguments in addition to any
combination of arguments from previous syntaxes. For example,
Name=Value)ExecutionEnvironment="gpu" sets the hardware resource for
processing images to gpu.
Examples
Perform semantic segmentation of a test image and display the results.
Load a pretrained network.
load("triangleSegmentationNetwork")List the network layers.
net.Layers
ans =
9×1 Layer array with layers:
1 'imageinput' Image Input 32×32×1 images with 'zerocenter' normalization
2 'conv_1' 2-D Convolution 64 3×3×1 convolutions with stride [1 1] and padding [1 1 1 1]
3 'relu_1' ReLU ReLU
4 'maxpool' 2-D Max Pooling 2×2 max pooling with stride [2 2] and padding [0 0 0 0]
5 'conv_2' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1]
6 'relu_2' ReLU ReLU
7 'transposed-conv' 2-D Transposed Convolution 64 4×4×64 transposed convolutions with stride [2 2] and cropping [1 1 1 1]
8 'conv_3' 2-D Convolution 2 1×1×64 convolutions with stride [1 1] and padding [0 0 0 0]
9 'softmax' Softmax Softmax
Read and display the test image.
I = imread("triangleTest.jpg");
imshow(I)
Define the two classes on which the network was trained, then perform semantic image segmentation.
classNames = ["triangle" "background"]; [C,scores] = semanticseg(I,net,Classes=classNames,MiniBatchSize=32);
Overlay segmentation results on the image and display the results.
B = labeloverlay(I,C); imshow(B)

Display the classification confidence scores.
imagesc(scores)
axis square
colorbar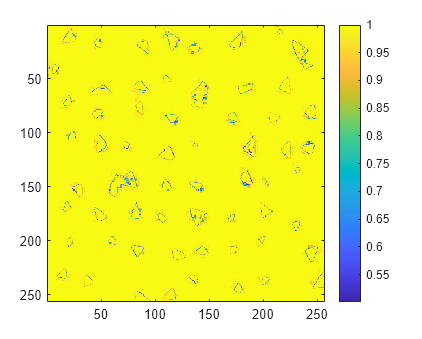
Create a binary mask with only the triangles.
BW = C=="triangle";
imshow(BW)
Run semantic segmentation on a test set of images and compare the results against ground truth data.
Load a pretrained network.
data = load("triangleSegmentationNetwork");
net = data.net;Load test images using imageDatastore.
dataDir = fullfile(toolboxdir("vision"),"visiondata","triangleImages"); testImageDir = fullfile(dataDir,"testImages"); imds = imageDatastore(testImageDir)
imds =
ImageDatastore with properties:
Files: {
' .../toolbox/vision/visiondata/triangleImages/testImages/image_001.jpg';
' .../toolbox/vision/visiondata/triangleImages/testImages/image_002.jpg';
' .../toolbox/vision/visiondata/triangleImages/testImages/image_003.jpg'
... and 97 more
}
Folders: {
' .../runnable/matlab/toolbox/vision/visiondata/triangleImages/testImages'
}
AlternateFileSystemRoots: {}
ReadSize: 1
Labels: {}
SupportedOutputFormats: ["png" "jpg" "jpeg" "tif" "tiff"]
DefaultOutputFormat: "png"
ReadFcn: @readDatastoreImage
Load ground truth test labels.
testLabelDir = fullfile(dataDir,"testLabels"); classNames = ["triangle" "background"]; pixelLabelID = [255 0]; pxdsTruth = pixelLabelDatastore(testLabelDir,classNames,pixelLabelID);
Run semantic segmentation on all of the test images with a batch size of 4. You can increase the batch size to increase throughput based on your systems memory resources.
pxdsResults = semanticseg(imds,net,Classes=classNames, ...
MiniBatchSize=4,WriteLocation=tempdir);Running semantic segmentation network ------------------------------------- * Processed 100 images.
Compare the results against the ground truth.
metrics = evaluateSemanticSegmentation(pxdsResults,pxdsTruth)
Evaluating semantic segmentation results
----------------------------------------
* Selected metrics: global accuracy, class accuracy, IoU, weighted IoU, BF score.
* Processed 100 images.
* Finalizing... Done.
* Data set metrics:
GlobalAccuracy MeanAccuracy MeanIoU WeightedIoU MeanBFScore
______________ ____________ _______ ___________ ___________
0.99074 0.99183 0.91118 0.98299 0.80563
metrics =
semanticSegmentationMetrics with properties:
ConfusionMatrix: [2×2 table]
NormalizedConfusionMatrix: [2×2 table]
DataSetMetrics: [1×5 table]
ClassMetrics: [2×3 table]
ImageMetrics: [100×5 table]
This example shows how to train a semantic segmentation network using dilated convolutions.
A semantic segmentation network classifies every pixel in an image, resulting in an image that is segmented by class. Applications for semantic segmentation include road segmentation for autonomous driving and cancer cell segmentation for medical diagnosis. To learn more, see Get Started with Semantic Segmentation Using Deep Learning.
Semantic segmentation networks like Deeplab v3+ [1] make extensive use of dilated convolutions (also known as atrous convolutions) because they can increase the receptive field of the layer (the area of the input which the layers can see) without increasing the number of parameters or computations.
Load Training Data
The example uses a simple dataset of 32-by-32 triangle images for illustration purposes. The dataset includes accompanying pixel label ground truth data. Load the training data using an imageDatastore and a pixelLabelDatastore.
dataFolder = fullfile(toolboxdir("vision"),"visiondata","triangleImages"); imageFolderTrain = fullfile(dataFolder,"trainingImages"); labelFolderTrain = fullfile(dataFolder,"trainingLabels");
Create an imageDatastore for the images.
imdsTrain = imageDatastore(imageFolderTrain);
Create a pixelLabelDatastore for the ground truth pixel labels.
classNames = ["triangle" "background"]; labels = [255 0]; pxdsTrain = pixelLabelDatastore(labelFolderTrain,classNames,labels)
pxdsTrain =
PixelLabelDatastore with properties:
Files: {200×1 cell}
ClassNames: {2×1 cell}
ReadSize: 1
ReadFcn: @readDatastoreImage
AlternateFileSystemRoots: {}
Create Semantic Segmentation Network
This example uses a simple semantic segmentation network based on dilated convolutions.
Create a data source for training data and get the pixel counts for each label.
ds = combine(imdsTrain,pxdsTrain); tbl = countEachLabel(pxdsTrain)
tbl=2×3 table
'triangle' 10326 204800
'background' 194474 204800
The majority of pixel labels are for background. This class imbalance biases the learning process in favor of the dominant class. To fix this, use class weighting to balance the classes. You can use several methods to compute class weights. One common method is inverse frequency weighting where the class weights are the inverse of the class frequencies. This method increases the weight given to under represented classes. Calculate the class weights using inverse frequency weighting.
numberPixels = sum(tbl.PixelCount);
frequency = tbl.PixelCount / numberPixels;
classWeights = dlarray(1 ./ frequency,"C");Create a network for pixel classification by using an image input layer with an input size corresponding to the size of the input images. Next, specify three blocks of convolution, batch normalization, and ReLU layers. For each convolutional layer, specify 32 3-by-3 filters with increasing dilation factors and pad the inputs so they are the same size as the outputs by setting the Padding name-value argument as "same". To classify the pixels, include a convolutional layer with K 1-by-1 convolutions, where K is the number of classes, followed by a softmax layer. The classification of pixels is done with a custom model loss within the built-in trainer, trainnet.
inputSize = [32 32 1];
filterSize = 3;
numFilters = 32;
numClasses = numel(classNames);
layers = [
imageInputLayer(inputSize)
convolution2dLayer(filterSize,numFilters,DilationFactor=1,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(filterSize,numFilters,DilationFactor=2,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(filterSize,numFilters,DilationFactor=4,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(1,numClasses)
softmaxLayer];Model Loss Function
The semantic segmentation network can be trained using different loss functions. The built-in trainer trainnet (Deep Learning Toolbox) supports custom loss functions as well as some standard loss functions such as "crossentropy" and "mse". A custom loss function manually computes the loss for each batch of training data by comparing the network's predictions to the actual ground truth or target values. Custom loss functions use a function handle with the function syntax loss = f(Y1,...,Yn,T1,...,Tm), where Y1,...,Yn are dlarray objects that correspond to the n network predictions and T1,...,Tm are dlarray objects that correspond to the m targets.
This example enables you to select from two different loss functions that account for the class imbalance seen in the data. These loss functions are:
Weighted cross-entropy loss, which uses the
crossentropy(Deep Learning Toolbox) function. Weighted cross-entropy loss gives stronger favor to the underrepresented class by scaling the error of that class during training.A custom loss function called
tverskyLossthat calculates the Tversky loss [2]. Tversky loss is more specialized loss for class imbalance.
The Tversky loss is based on the Tversky index for measuring overlap between two segmented images. The Tversky index between one image and the corresponding ground truth is given by
corresponds to the class and corresponds to not being in class .
is the number of elements along the first two dimensions of .
and are weighting factors that control the contribution that false positives and false negatives for each class make to the loss.
The loss over the number of classes is given by
Select the loss function to use during training.
lossFunction =  "tverskyLoss"
"tverskyLoss"lossFunction = "tverskyLoss"
if strcmp(lossFunction,"tverskyLoss") % Declare Tversky loss weighting coefficients for false positives and % false negatives. These coefficients are set and passed to the % training loss function using trainnet. alpha = 0.7; beta = 0.3; lossFcn = @(Y,T) tverskyLoss(Y,T,alpha,beta); else % Use weighted cross-entropy loss during training. lossFcn = @(Y,T) crossentropy(Y,T,classWeights,NormalizationFactor="all-elements"); end
Train Network
Specify the training options.
options = trainingOptions("sgdm",... MaxEpochs=100,... MiniBatchSize= 64,... InitialLearnRate=1e-2,... Verbose=false);
Train the network using trainnet (Deep Learning Toolbox). Specify the loss as the loss function lossFcn.
net = trainnet(ds,layers,lossFcn,options);
Test Network
Load the test data. Create an imageDatastore for the images. Create a pixelLabelDatastore for the ground truth pixel labels.
imageFolderTest = fullfile(dataFolder,"testImages"); imdsTest = imageDatastore(imageFolderTest); labelFolderTest = fullfile(dataFolder,"testLabels"); pxdsTest = pixelLabelDatastore(labelFolderTest,classNames,labels);
Make predictions using the test data and trained network.
pxdsPred = semanticseg(imdsTest,net,... Classes=classNames,... MiniBatchSize=32,... WriteLocation=tempdir);
Running semantic segmentation network ------------------------------------- * Processed 100 images.
Evaluate the prediction accuracy using evaluateSemanticSegmentation.
metrics = evaluateSemanticSegmentation(pxdsPred,pxdsTest);
Evaluating semantic segmentation results
----------------------------------------
* Selected metrics: global accuracy, class accuracy, IoU, weighted IoU, BF score.
* Processed 100 images.
* Finalizing... Done.
* Data set metrics:
GlobalAccuracy MeanAccuracy MeanIoU WeightedIoU MeanBFScore
______________ ____________ _______ ___________ ___________
0.99674 0.98562 0.96447 0.99362 0.92831
Segment New Image
Read the test image triangleTest.jpg and segment the test image using semanticseg. Display the results using labeloverlay.
imgTest = imread("triangleTest.jpg");
[C,scores] = semanticseg(imgTest,net,classes=classNames);
B = labeloverlay(imgTest,C);
montage({imgTest,B})
Supporting Functions
function loss = tverskyLoss(Y,T,alpha,beta) % loss = tverskyLoss(Y,T,alpha,beta) returns the Tversky loss % between the predictions Y and the training targets T. Pcnot = 1-Y; Gcnot = 1-T; TP = sum(sum(Y.*T,1),2); FP = sum(sum(Y.*Gcnot,1),2); FN = sum(sum(Pcnot.*T,1),2); epsilon = 1e-8; numer = TP + epsilon; denom = TP + alpha*FP + beta*FN + epsilon; % Compute tversky index. lossTIc = 1 - numer./denom; lossTI = sum(lossTIc,3); % Return average Tversky index loss. N = size(Y,4); loss = sum(lossTI)/N; end
References
[1] Chen, Liang-Chieh et al. “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.” ECCV (2018).
[2] Salehi, Seyed Sadegh Mohseni, Deniz Erdogmus, and Ali Gholipour. "Tversky loss function for image segmentation using 3D fully convolutional deep networks." International Workshop on Machine Learning in Medical Imaging. Springer, Cham, 2017.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Extended Capabilities
Version History
Introduced in R2017bSee Also
Apps
Functions
trainnet(Deep Learning Toolbox) |labeloverlay|evaluateSemanticSegmentation
Objects
ImageDatastore|pixelLabelDatastore|dlnetwork(Deep Learning Toolbox)
Topics
- Get Started with Semantic Segmentation Using Deep Learning
- Deep Learning in MATLAB (Deep Learning Toolbox)
- Datastores for Deep Learning (Deep Learning Toolbox)