taylorPrunableNetwork
Description
Add-On Required: This feature requires the Deep Learning Toolbox Model Compression Library add-on.
A TaylorPrunableNetwork object enables support for compression
of neural networks using Taylor pruning.
Tip
Since R2026a, if you can train your network using the trainnet
function, then prune your network by using the compressNetworkUsingTaylorPruning function. If you cannot train your network
using the trainnet
function, then create a custom pruning loop by using a
taylorPrunableNetwork object instead.
Pruning a neural network means removing the least important parameters to reduce the size of the network while preserving the quality of its predictions as much as possible.
Find the least important parameters in a pretrained network by iterating over these steps:
Determine the importance score of the prunable parameters and remove the least important parameters.
Retrain the updated network for several iterations.
Removing the least important parameters in each iteration of the pruning loop is
computationally expensive. Use a TaylorPrunableNetwork object to simulate
pruning by applying a pruning mask. Then, use the object functions to update the mask during
the pruning loop. Finally, update the network architecture by converting the network back to a
dlnetwork object.
For an example of the full pruning workflow, see Prune Image Classification Network Using Taylor Scores.
Creation
Description
Input Arguments
Properties
Object Functions
forward | Compute deep learning network output for training |
predict | Compute deep learning network output for inference |
updatePrunables | Remove filters from prunable layers based on importance scores |
updateScore | Compute and accumulate Taylor-based importance scores for pruning |
dlnetwork | Deep learning neural network |
Examples
Load a pretrained SqueezeNet neural network.
net = imagePretrainedNetwork;
Convert the network into a TaylorPrunableNetwork object.
prunableNet = taylorPrunableNetwork(net)
prunableNet =
TaylorPrunableNetwork with properties:
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob_flatten'}
NumPrunables: 2368
Load a trained and pruned TaylorPrunableNetwork object.
load("prunedDigitsCustom.mat");Analyze the network. The analyzeNetwork function displays an interactive plot of the network architecture and a table containing information about the network layers. The table shows the number of pruned convolutional filters. The table also shows the percentage decrease in the number of learnables for each layer. The effects of pruning include the learnables reduction in the three convolutional layers, but also downstream effects in other layers that do not have pruned filters.
info = analyzeNetwork(prunableNet);
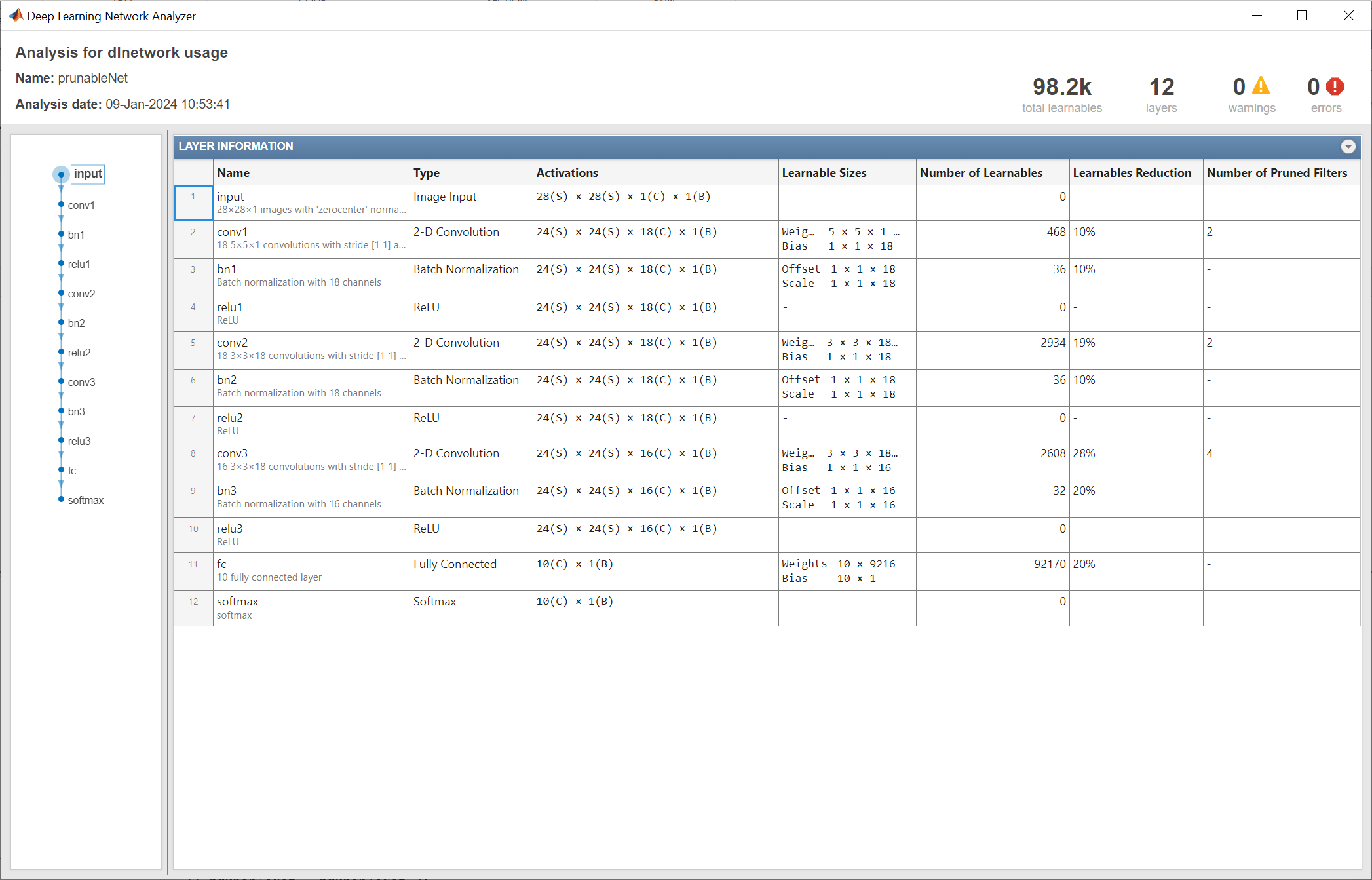
Programmatically view the layer information table.
info.LayerInfo
ans=12×9 table
Name Type ActivationSizes ActivationFormats LearnableSizes NumLearnables StateSizes LearnablesReduction NumPrunedFilters
_________ _____________________ _______________ _________________ ______________________________________________ _____________ ______________________________________________ ___________________ ________________
"input" "Image Input" {[ 28 28 1 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with no entries]} 0 {[dictionary (string ⟼ cell) with no entries]} 0 0
"conv1" "2-D Convolution" {[24 24 18 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with 2 entries ]} 468 {[dictionary (string ⟼ cell) with no entries]} 0.1 2
"bn1" "Batch Normalization" {[24 24 18 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with 2 entries ]} 36 {[dictionary (string ⟼ cell) with 2 entries ]} 0.1 0
"relu1" "ReLU" {[24 24 18 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with no entries]} 0 {[dictionary (string ⟼ cell) with no entries]} 0 0
"conv2" "2-D Convolution" {[24 24 18 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with 2 entries ]} 2934 {[dictionary (string ⟼ cell) with no entries]} 0.1895 2
"bn2" "Batch Normalization" {[24 24 18 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with 2 entries ]} 36 {[dictionary (string ⟼ cell) with 2 entries ]} 0.1 0
"relu2" "ReLU" {[24 24 18 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with no entries]} 0 {[dictionary (string ⟼ cell) with no entries]} 0 0
"conv3" "2-D Convolution" {[24 24 16 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with 2 entries ]} 2608 {[dictionary (string ⟼ cell) with no entries]} 0.27956 4
"bn3" "Batch Normalization" {[24 24 16 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with 2 entries ]} 32 {[dictionary (string ⟼ cell) with 2 entries ]} 0.2 0
"relu3" "ReLU" {[24 24 16 1]} {["SSCB"]} {[dictionary (string ⟼ cell) with no entries]} 0 {[dictionary (string ⟼ cell) with no entries]} 0 0
"fc" "Fully Connected" {[ 10 1]} {["CB" ]} {[dictionary (string ⟼ cell) with 2 entries ]} 92170 {[dictionary (string ⟼ cell) with no entries]} 0.19998 0
"softmax" "Softmax" {[ 10 1]} {["CB" ]} {[dictionary (string ⟼ cell) with no entries]} 0 {[dictionary (string ⟼ cell) with no entries]} 0 0
Algorithms
Pruning a neural network means removing the least important parameters to reduce the size of the network while preserving the quality of its predictions.
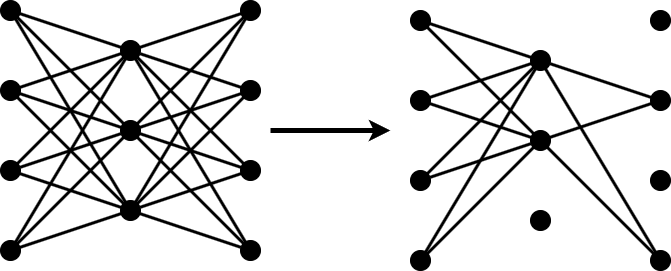
You can measure the importance of a set of parameters by the change in loss after you remove the parameters from the network. If the loss changes significantly, then the parameters are important. If the loss does not change significantly, then the parameters are not important and can be pruned.
Neural networks typically contain too many parameters for you to calculate the change in loss for all possible combinations of parameters. In that case, follow these steps to apply an iterative workflow instead.
Use an approximation to find and remove the least important parameter or a specified number of the least important parameters. For example, if you approximate the parameters to be independent, then you can measure the change in loss after removing each parameter by itself.
Fine-tune the new, smaller network by retraining it for several iterations.
Repeat steps 1 and 2 until you reach your compression goal.
To perform the approximation in step 1, calculate the Taylor expansion of the loss as a function of the individual network parameters. This method is called Taylor pruning.
For some types of layers, including convolutional layers, removing a parameter is equivalent to setting it to zero. In this case, the change in loss resulting from pruning a parameter θ can be expressed as
X is the training data of your network.
Calculate the Taylor expansion of the loss as a function of the parameter θ to first order using
Then, you can express the change of loss as a function of the gradient of the loss with respect to the parameter θ using
References
[1] Molchanov, Pavlo, Stephen Tyree, Tero Karras, Timo Aila, and Jan Kautz. "Pruning Convolutional Neural Networks for Resource Efficient Inference." arXiv, June 8, 2017. https://arxiv.org/abs/1611.06440.
Version History
Introduced in R2022aSee Also
predict | forward | updatePrunables | updateScore | dlnetwork