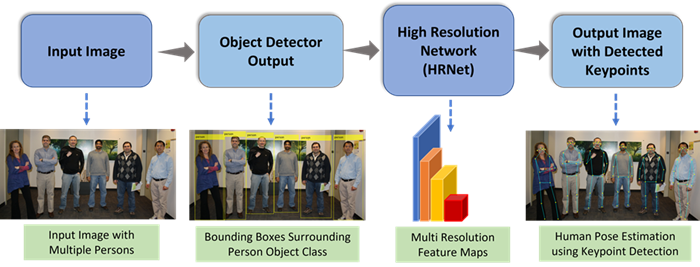
Getting Started with HRNet
The high-resolution network (HRNet) is a convolutional neural network that trains on high resolution representations of input data to perform recognition tasks. High-resolution representations lead to stronger position sensitivity in the output feature representations. Traditional convolutional networks often rapidly downsample the input image to lower resolution, which can lead to significant information loss. HRNet minimizes this loss by maintaining high resolution throughout the network, rather than recovering high-resolution information from low-resolution representations.
HRNet is suitable for applications that require highly localized information for accurate detection. For example, human body pose estimation requires accurate localization of keypoints such as the head as well as neck, elbow, and knee joints. The high-resolution information of HRNet preserves localization information throughout the network, which is essential for accurate keypoint localization.
The structure of HRNet is unique in its approach to maintaining high-resolution representations throughout the entire network. The key characteristics of HRNet are:
Parallel multi-resolution subnetworks
Multi-scale feature fusion using exchange units
High resolution output
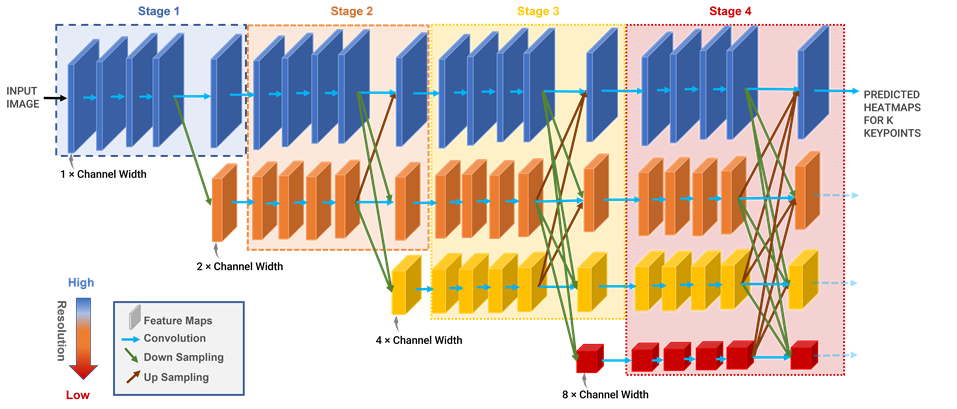
The HRNet architecture consists of four stages, Stage 1 to Stage 4.
The network starts with a high-resolution subnetwork in Stage 1, which consists of a stem block with a set of convolutional and batch normalization layers that process the input image. The output of the stem block is fed into a series of convolutional layers that operate at a high resolution.
Starting from Stage 2 to Stage 4, the network branches out into multiple parallel subnetworks, each operating at a different resolution. The first subnetwork continues the high-resolution path from Stage 1, while additional subnetworks process the features at progressively lower resolutions.
Parallel multi-resolution subnetworks
A subnetwork branch of each resolution has 4 residual units. Each unit performs two 3×3 convolutions in the respective resolution.
Stage 1 contains only the highest resolution feature maps, at the default channel width (the number of channels). Each stage after the Stage 1 contains the feature maps from all previous stages, as well as feature maps at half the resolution and twice the channel width of the lowest resolution in the previous stage.
This figure below illustrates the high level HRNet architecture. The horizontal and vertical directions correspond to the depth of the network and the scale of the feature maps, respectively. The progression from each stage of the network to the next stage maintains high resolution representations throughout the whole feature learning process. This leads to a spatially precise heatmap estimation that preserves spatial localization information and decreases time complexity.
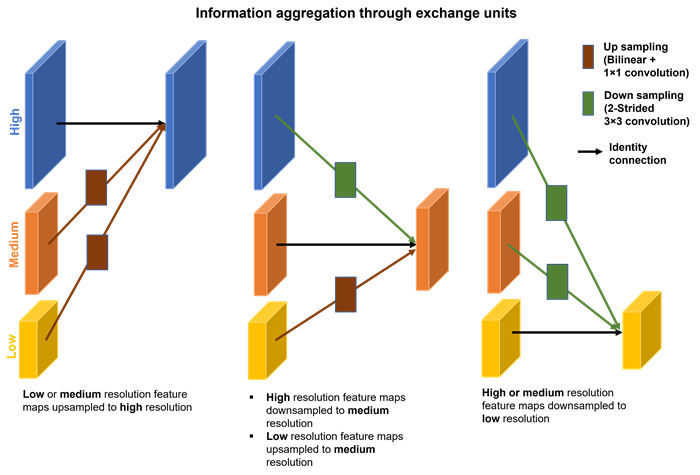
Exchange units
HRNet aggregates multiresolution representations repeatedly at every stage conjunction. The network establishes this multiscale feature fusion through multiresolution group convolution by using exchange units.
Repeated multiscale feature fusion across parallel branches strengthens the high-resolution representations with the help of low-resolution representations of the same depth and level, and low-resolution representations with the help of the corresponding high-resolution representations. The high-resolution subnetwork receives contextual information from lower resolutions, while the low-resolution subnetwork receives fine-grained spatial information from the high-resolution subnetwork making the predicted feature map highly accurate.
The network uses the heatmap output from the high-resolution representations of the last exchange unit in Stage 4 for keypoint localization. For instance, to detect K keypoints in an object, HRNet generates K heatmap predictions. The network trains by minimizing the mean squared error (MSE) loss between the K predicted and groundtruth heatmaps. To generate the groundtruth heatmaps, the network applies a 2-D Gaussian filter centered around the keypoint groundtruth with a standard deviation of one pixel.
Create HRNet Object Keypoint Detection Network
To programmatically create a HRNet deep learning network, use the hrnetObjectKeypointDetector object. You can create an hrnetObjectKeypointDetector object, to detect object keypoints in an
image, using the pretrained HRNet deep learning networks HRNet-W32 and HRNet-W48. These
networks have been trained on the COCO keypoint detection data set. In HRNet-W32 and
HRNet-W48, the channel widths of the highest resolution subnetworks in the last three
stages are 32 and 48 channels, respectively. The widths of the other three parallel
subnetworks are thus 64, 128, and 256 channels for HRNet-W32, and 96, 192, and 384 for
HRNet-W48. HRNet-W48 has a higher capacity of feature extraction compared to HRNet-W32,
but at a cost of higher computational complexity and training time. To download the
pretrained HRNets, you must install the Computer Vision Toolbox™ Model for Object Keypoint Detection support package.
Detect Object Keypoints Using HRNet
To detect keypoints on the object, you must first localize the objects in the image
using any pretrained object detector like yolov2ObjectDetector, yolov3ObjectDetector, yolov4ObjectDetector, or maskrcnn.
You must then specify the bounding boxes of the detected objects as an input to the
detect
function of the hrnetObjectKeypointDetector object to detect the keypoints from the
localized objects in the image.
To learn how to create a pretrained HRNet object detector for keypoint detection in humans, see the Create Pretrained HRNet Object Keypoint Detector example.
Train HRNet Object Keypoint Detector
You can perform transfer learning using a pretrained HRNet deep learning network as
the base network. Configure the pretrained HRNet for training on a new dataset by
specifying the new object keypoint classes. Use the hrnetObjectKeypointDetector object to create a custom HRNet object
keypoint detector. Then, train the keypoint detection network using the trainHRNetObjectKeypointDetector function.
To learn how to create a custom HRNet object detector by using an HRNet deep learning network as the base network and train for object keypoint detection, see the Hand Pose Estimation Using HRNet Deep Learning example.
Visualize Object Keypoints
To render and visualize the detected object keypoints on the image, use the insertObjectKeypoints function. For applications like human pose
estimation, you can also render the keypoints as a skeleton by specifying the keypoint
connections.
References
[1] Wang, Jingdong, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, et al. "Deep High-Resolution Representation Learning for Visual Recognition." IEEE Transactions on Pattern Analysis and Machine Intelligence 43, no. 10 (October 1, 2021): 3349–64. https://doi.org/10.1109/TPAMI.2020.2983686.
[2] Sun, Ke, Bin Xiao, Dong Liu, and Jingdong Wang. "Deep High-Resolution Representation Learning for Human Pose Estimation." In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5686–96. Long Beach, CA, USA: IEEE, 2019. https://doi.org/10.1109/CVPR.2019.00584.
See Also
Apps
- Image Labeler | Ground Truth Labeler (Automated Driving Toolbox) | Video Labeler | Deep Network Designer (Deep Learning Toolbox)