filloutliers
检测并替换数据中的离群值
语法
说明
B = filloutliers(A,fillmethod)A 中的离群值并根据 fillmethod 替换它们。例如,filloutliers(A,"previous") 将离群值替换为上一个非离群值元素。
如果
A是矩阵,则filloutliers分别对A的每列进行运算。如果
A是多维数组,则filloutliers沿A的大小不等于 1 的第一个维度进行运算。如果
A是表或时间表,则filloutliers分别对A的每个变量进行运算。
默认情况下,离群值是指与中位数相差超过三倍经过换算的中位数绝对偏差 (MAD) 的值。
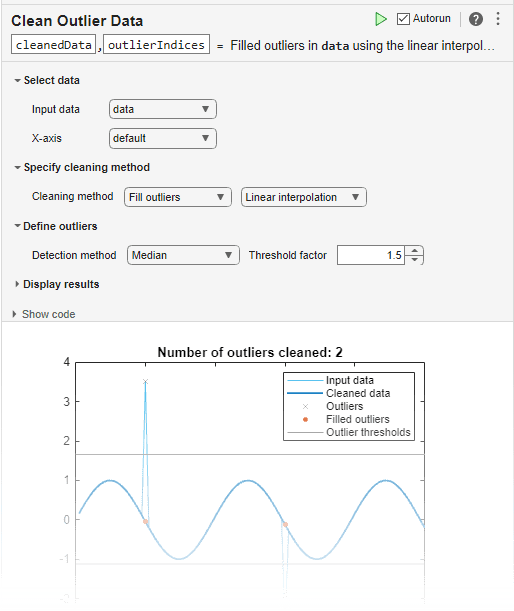
您可以通过将清洗离群数据任务添加到实时脚本中,以交互方式使用 filloutliers 功能。
B = filloutliers(A,fillmethod,findmethod)filloutliers(A,"previous","mean") 将 A 中与均值相差超过三个标准差的元素定义为离群值。
B = filloutliers(A,fillmethod,"percentiles",threshold)threshold 所指定的百分位数以外的点。threshold 参量是包含上下百分位数阈值的二元素行向量,例如 [10 90]。
B = filloutliers(A,fillmethod,movmethod,window)window 的移动窗均值或中位数来检测局部离群值。例如,filloutliers(A,"previous","movmean",5) 将包含五个元素的窗口中与局部均值相差超过三倍局部标准差的元素标识为离群值。
B = filloutliers(___,Name,Value)filloutliers(A,"previous","SamplePoints",t) 相对于时间向量 t 中的对应元素检测 A 中的离群值。
示例
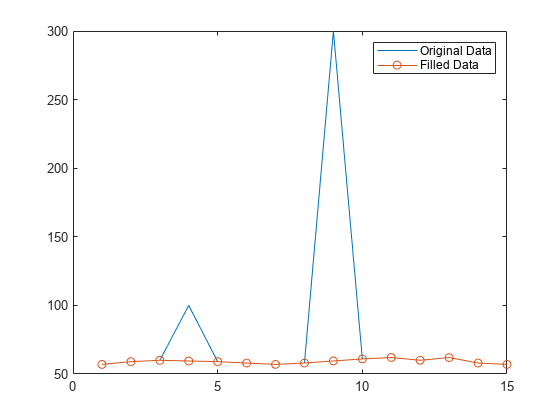
使用 "linear" 方法填充数据向量中的离群值,并可视化填充的数据。
创建一个包含两个离群值的数据向量。
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57];
使用线性插值替换离群值。
B = filloutliers(A,"linear");绘制原始数据和填充了离群值的数据。
plot(A) hold on plot(B,"o-") legend("Original Data","Filled Data")
识别数据表中的潜在离群值,使用 "nearest" 填充方法填充任何离群值,并可视化清洗后的数据。
创建一个数据时间表,并可视化数据以检测潜在的离群值。
T = hours(1:15); V = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; A = timetable(T',V'); plot(A.Time,A.Var1)
填充数据中的离群值,其中离群值定义为偏离均值超过三个标准差的值。将离群值替换为最接近的非离群值元素。
B = filloutliers(A,"nearest","mean")
B=15×1 timetable
Time Var1
_____ ____
1 hr 57
2 hr 59
3 hr 60
4 hr 100
5 hr 59
6 hr 58
7 hr 57
8 hr 58
9 hr 61
10 hr 61
11 hr 62
12 hr 60
13 hr 62
14 hr 58
15 hr 57
在同一个图中,绘制原始数据和填充了离群值的数据。
hold on plot(B.Time,B.Var1,"o-") legend("Original Data","Filled Data")

使用移动中位数,检测并填充与时间向量对应的正弦波内的局部离群值。
创建包含一个局部离群值的数据向量。
x = -2*pi:0.1:2*pi; A = sin(x); A(47) = 0;
创建与 A 中的数据对应的时间向量。
t = datetime(2017,1,1,0,0,0) + hours(0:length(x)-1);
将离群值定义为滑动窗内与局部中位数相差超过三倍局部换算 MAD 的点。在 A 中查找与 t 中的点对应的离群值的位置,窗口大小为 5 小时。使用 "clip" 方法,用计算的阈值填充离群值。
[B,TF,L,U,C] = filloutliers(A,"clip","movmedian",hours(5),"SamplePoints",t);
绘制原始数据和填充了离群值的数据。
plot(t,A) hold on plot(t,B,"o-") legend("Original Data","Filled Data")

创建一个数据矩阵,其对角线上包含离群值。
A = randn(5,5) + diag(1000*ones(1,5))
A = 5×5
103 ×
1.0005 -0.0013 -0.0013 -0.0002 0.0007
0.0018 0.9996 0.0030 -0.0001 -0.0012
-0.0023 0.0003 1.0007 0.0015 0.0007
0.0009 0.0036 -0.0001 1.0014 0.0016
0.0003 0.0028 0.0007 0.0014 1.0005
基于每一行中的数据用零填充替换离群值,然后显示新值。
[B,TF] = filloutliers(A,0,2); B
B = 5×5
0 -1.3077 -1.3499 -0.2050 0.6715
1.8339 0 3.0349 -0.1241 -1.2075
-2.2588 0.3426 0 1.4897 0.7172
0.8622 3.5784 -0.0631 0 1.6302
0.3188 2.7694 0.7147 1.4172 0
您可以使用 TF 作为索引向量,访问检测到的离群值及其填充的值。
[A(TF) B(TF)]
ans = 5×2
103 ×
1.0005 0
0.9996 0
1.0007 0
1.0014 0
1.0005 0
创建一个包含两个离群值的向量,并检测这些离群值的位置。
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; detect = isoutlier(A)
detect = 1×15 logical array
0 0 0 1 0 0 0 0 1 0 0 0 0 0 0
使用 "nearest" 方法填充离群值。不使用检测方法,而是提供由 isoutlier 检测到的离群值位置。
B = filloutliers(A,"nearest","OutlierLocations",detect)
B = 1×15
57 59 60 59 59 58 57 58 61 61 62 60 62 58 57
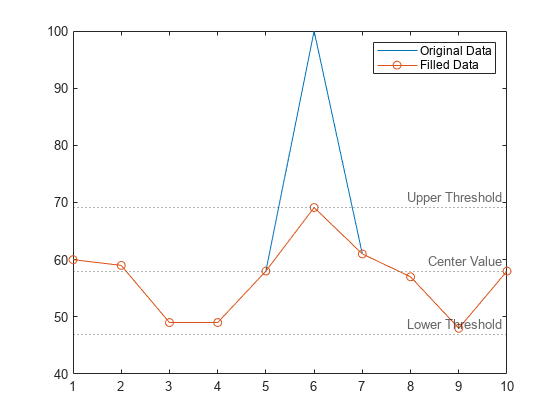
使用 "clip" 填充方法替换数据向量中的离群值。
创建一个包含一个离群值的数据向量。
A = [60 59 49 49 58 100 61 57 48 58];
使用默认方法 "median" 检测离群值,使用 "clip" 填充方法用上阈值替换该离群值。
[B,TF,L,U,C] = filloutliers(A,"clip");绘制原始数据、填充了离群值的数据以及由离群值检测方法确定的阈值和中心值。中心值是数据的中位数,上阈值和下阈值分别高于和低于中位数三倍换算 MAD。
plot(A) hold on plot(B,"o-") yline([L U C],":",["Lower Threshold","Upper Threshold","Center Value"]) legend("Original Data","Filled Data")
自 R2024a 起
创建一个表并填充离群值,离群值定义为大于 10 的值。创建一个逻辑变量表 loc,该表指示要填充的离群值的位置。然后,使用 OutlierLocations 名称-值参量指定 filloutliers 的已知离群值位置。
A = [1; 4; 9; 12; 3]; B = [9; 0; 6; 2; 1]; C = [14; 4; 2; 3; 8]; T = table(A,B,C)
T=5×3 table
A B C
__ _ __
1 9 14
4 0 4
9 6 2
12 2 3
3 1 8
loc = T>10
loc=5×3 table
A B C
_____ _____ _____
false false true
false false false
false false false
true false false
false false false
T = filloutliers(T,10,OutlierLocations=loc)
T=5×3 table
A B C
__ _ __
1 9 10
4 0 4
9 6 2
10 2 3
3 1 8
输入参数
输入数据,指定为向量、矩阵、多维数组、表或时间表。
如果
A是一个表,则其变量的类型必须为double或single,您也可以使用DataVariables参量显式列出double或single变量。当您使用的表中包含double和single数据类型之外的变量时,指定变量很有用。如果
A是一个时间表,则filloutliers仅对表元素进行运算。如果行时间用作采样点,则它们必须唯一,并按升序排列。
数据类型: double | single | table | timetable
替换离群值的填充方法,指定为以下值之一。
| 填充方法 | 描述 |
|---|---|
| 数值标量 | 指定的标量值 |
"center" | 由 findmethod 确定的中心值 |
"clip" | 对于比 findmethod 确定的下阈值还小的元素,指定为下阈值;对于比 findmethod 确定的上阈值还大的元素,指定为上阈值 |
"previous" | 上一个非离群值 |
"next" | 下一个非离群值 |
"nearest" | 最邻近的非离群值 |
"linear" | 基于相邻的非离群值进行线性插值 |
"spline" | 分段三次样条插值 |
"pchip" | 保形分段三次样条插值 |
"makima" | 修正 Akima 三次 Hermite 插值(仅限数值、duration 和 datetime 数据类型) |
数据类型: double | single | char | string
检测离群值的方法,指定为以下值之一。
| 方法 | 描述 |
|---|---|
"median" | 离群值定义为与中位数相差超过三倍换算 MAD 的元素。换算 MAD 定义为 c*median(abs(A-median(A))),其中 c=-1/(sqrt(2)*erfcinv(3/2))。 |
"mean" | 离群值定义为与均值相差超过三个标准差的元素。此方法比 "median" 快,但没有它可靠。 |
"quartiles" | 离群值定义为比上四分位数 (75%) 大 1.5 个四分位差以上或比下四分位数 (25%) 小 1.5 个四分位差以上的元素。当 A 中的数据不是正态分布时,此方法很有用。 |
"grubbs" | 使用格拉布斯检验检测离群值,并基于假设检验每次迭代删除一个离群值。此方法假设 A 中的数据呈正态分布。 |
"gesd" | 使用广义极端 Student 化偏差检验检测离群值。此迭代方法与 "grubbs" 类似,但当多个离群值互相遮盖时,此方法的执行效果更好。 |
百分位数阈值,指定为元素在区间 [0,100] 内的二元素行向量。第一个元素表示下百分位数阈值,第二个元素表示上百分位数阈值。threshold 的第一个元素必须小于第二个元素。
例如,[10 90] 阈值将离群值定义为低于第 10 个百分位数或高于第 90 个百分位数的点。
用来检测离群值的移窗法,指定为下列方法之一。
| 方法 | 描述 |
|---|---|
"movmedian" | 离群值定义为在 window 指定的窗口长度内,与局部中位数相差超过三倍局部换算 MAD 的元素。此方法也称为 汉佩尔滤波器。 |
"movmean" | 离群值定义为在 window 指定的窗口长度内,与局部均值相差超过三倍局部标准差的元素。 |
窗长度,指定为正整数标量、由正整数组成的二元素向量、正持续时间标量或由正持续时间组成的二元素向量。
如果 window 是正整数标量,则窗口以当前元素为中心并且包含 window-1 个相邻元素。如果 window 是偶数,则窗口以当前元素和上一个元素为中心。
如果 window 是由正整数组成的二元素向量 [b f],则窗口包含当前元素、其之前的 b 个元素和之后的 f 个元素。
当 A 是时间表或者 SamplePoints 被指定为 datetime 或 duration 向量时,window 的类型必须是 duration,而且将会基于样本点来计算窗口。
运算维度,指定为正整数标量。如果未指定值,则默认值是大小不等于 1 的第一个数组维度。
以一个 m×n 输入矩阵 A 为例:
filloutliers(A,fillmethod,1)根据A的每列中的数据填充离群值,并返回一个m×n矩阵。
filloutliers(A,fillmethod,2)根据A的每行中的数据填充离群值,并返回一个m×n矩阵。
对于表或时间表输入数据,不支持 dim,并且分别对每个表或时间表变量进行运算。
名称-值参数
输出参量
详细信息
替代功能
参考
[1] NIST/SEMATECH e-Handbook of Statistical Methods, https://www.itl.nist.gov/div898/handbook/, 2013.