isoutlier
查找数据中的离群值
语法
说明
TF = isoutlier(A)A 的元素中检测到离群值时,该数组中与之对应的元素为 true。
如果
A是矩阵,则isoutlier分别对A的每列进行运算。如果
A是多维数组,则isoutlier沿A的大小不等于 1 的第一个维度进行运算。如果
A是表或时间表,则isoutlier分别对A的每个变量进行运算。
默认情况下,离群值是指与中位数相差超过三倍经过换算的中位数绝对偏差 (MAD) 的值。
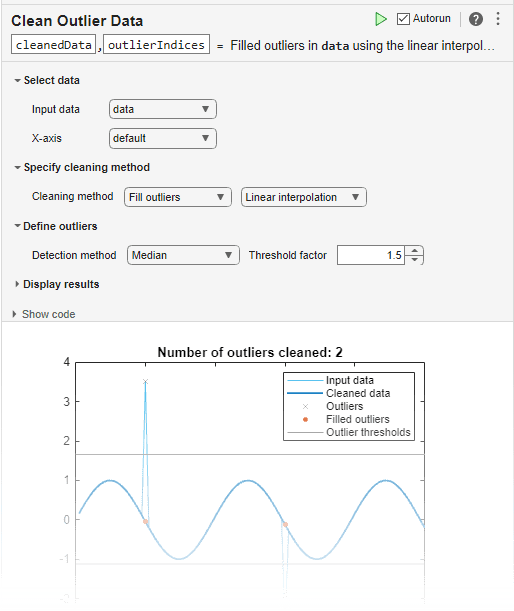
您可以通过将清洗离群数据任务添加到实时脚本中,以交互方式使用 isoutlier 功能。
TF = isoutlier(___,Name=Value)isoutlier(A,SamplePoints=t) 相对于时间向量 A 中的对应元素检测数组 t 中的离群值。
示例
查找数据向量中的离群值。输出中的逻辑值 1 表示离群值的位置。
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; TF = isoutlier(A)
TF = 1×15 logical array
0 0 0 1 0 0 0 0 1 0 0 0 0 0 0
将离群值定义为偏离均值三个标准差以上的点,并查找离群值在向量中的位置。
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57];
TF = isoutlier(A,"mean")TF = 1×15 logical array
0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
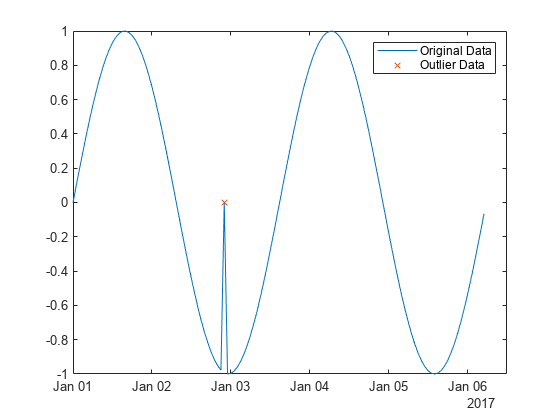
使用移动检测方法来检测对应于时间向量的正弦波中的局部离群值。
创建包含一个局部离群值的数据向量。
x = -2*pi:0.1:2*pi; A = sin(x); A(47) = 0;
创建与 A 中的数据对应的时间向量。
t = datetime(2017,1,1,0,0,0) + hours(0:length(x)-1);
将离群值定义为滑动窗内与局部中位数相差超过三倍局部换算 MAD 的点。查找离群值在 A 中的位置,相对于 t 中的点,窗口大小为 5 个小时。绘制数据和检测到的离群值的图。
TF = isoutlier(A,"movmedian",hours(5),SamplePoints=t); plot(t,A) hold on plot(t(TF),A(TF),"x") legend("Original Data","Outlier Data")
查找矩阵每一行的离群值。
创建一个数据矩阵,其对角线上包含离群值。
A = magic(5) + diag(200*ones(1,5))
A = 5×5
217 24 1 8 15
23 205 7 14 16
4 6 213 20 22
10 12 19 221 3
11 18 25 2 209
基于每行中的数据查找离群值的位置。
TF = isoutlier(A,2)
TF = 5×5 logical array
1 0 0 0 0
0 1 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1
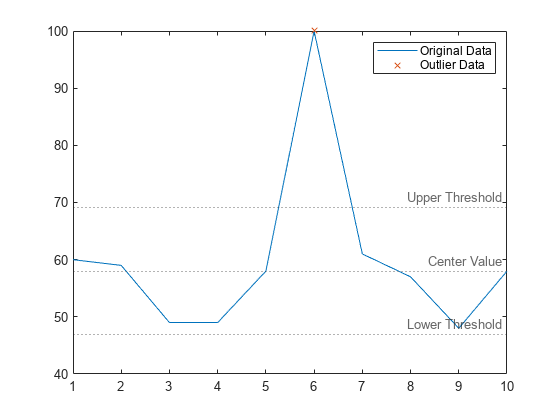
定位数据向量中的离群值,并可视化该离群值。
创建包含一个局部离群值的数据向量。
x = 1:10; A = [60 59 49 49 58 100 61 57 48 58];
使用默认检测方法 "median" 定位离群值。
[TF,L,U,C] = isoutlier(A);
绘制原始数据、离群值以及由检测方法确定的阈值和中心值。中心值是数据的中位数,上阈值和下阈值分别高于和低于中位数三倍换算 MAD。
plot(x,A) hold on plot(x(TF),A(TF),"x") yline([L U C],":",["Lower Threshold","Upper Threshold","Center Value"]) legend("Original Data","Outlier Data")
输入参数
输入数据,指定为向量、矩阵、多维数组或具有数值变量的表或时间表。
如果
A是一个表,则其变量的类型必须为double或single,您也可以使用DataVariables参量显式列出double或single变量。当您使用的表中包含double和single数据类型之外的变量时,指定变量很有用。如果
A是一个时间表,则isoutlier仅对表元素进行运算。如果行时间用作采样点,则它们必须唯一,并按升序排列。
数据类型: double | single | table | timetable
检测离群值的方法,指定为以下值之一。
| 方法 | 描述 |
|---|---|
"median" | 离群值定义为与中位数相差超过三倍换算 MAD 的元素。换算 MAD 定义为 c*median(abs(A-median(A))),其中 c=-1/(sqrt(2)*erfcinv(3/2))。 |
"mean" | 离群值定义为与均值相差超过三个标准差的元素。此方法比 "median" 快,但没有它可靠。 |
"quartiles" | 离群值定义为比上四分位数 (75%) 大 1.5 个四分位差以上或比下四分位数 (25%) 小 1.5 个四分位差以上的元素。当 A 中的数据不是正态分布时,此方法很有用。 |
"grubbs" | 使用针对离群值的格拉布斯检验检测离群值,即基于假设检验每次迭代删除一个离群值。此方法假设 A 中的数据呈正态分布。 |
"gesd" | 使用广义极端 Student 化偏差检验检测离群值。此迭代方法与 "grubbs" 类似,但当有多个离群值互相遮盖时,此方法的执行效果更好。MaxNumOutliers 指定的最大离群值计数取决于 A 中的元素数量。 |
在使用此处描述的方法名称时,输入数据中的 NaN 值会自动被忽略。
要使用指定范围检测离群值,请使用 isbetween 函数。
百分位数阈值,指定为元素在区间 [0, 100] 内的二元素行向量。第一个元素表示下百分位数阈值,第二个元素表示上百分位数阈值。threshold 的第一个元素必须小于第二个元素。
例如,[10 90] 阈值将离群值定义为低于第 10 个百分位数或高于第 90 个百分位数的点。
用来检测离群值的移窗法,指定为下列方法之一。
| 方法 | 描述 |
|---|---|
"movmedian" | 离群值定义为在 window 指定的窗口长度内,与局部中位数相差超过三倍局部换算 MAD 的元素。此方法也称为 汉佩尔滤波器。 |
"movmean" | 离群值定义为在 window 指定的窗口长度内,与局部均值相差超过三倍局部标准差的元素。 |
移窗法的窗长度,指定为正整数标量、由正整数组成的二元素向量、正持续时间标量或由正持续时间组成的二元素向量。
如果 window 是正整数标量,则窗口以当前元素为中心并且包含 window-1 个相邻元素。如果 window 是偶数,则窗口以当前元素和上一个元素为中心。
如果 window 是由正整数组成的二元素向量 [b f],则窗口包含当前元素、其之前的 b 个元素和之后的 f 个元素。
当 A 是时间表或者 SamplePoints 被指定为 datetime 或 duration 向量时,window 的类型必须是 duration,而且将会基于样本点来计算窗口。
沿其运算的数组维度,指定为正整数标量。如果未指定值,则默认值是大小不等于 1 的第一个数组维度。
以一个 m×n 输入矩阵 A 为例:
isoutlier(A,1)基于A的每列中的数据检测离群值,并返回一个m×n矩阵。
isoutlier(A,2)基于A的每行中的数据检测离群值,并返回一个m×n矩阵。
对于表或时间表输入数据,不支持 dim,并且分别对每个表或时间表变量进行运算。
名称-值参数
输出参量
详细信息
替代功能
参考
[1] NIST/SEMATECH e-Handbook of Statistical Methods, https://www.itl.nist.gov/div898/handbook/, 2013.
扩展功能
版本历史记录
在 R2017a 中推出另请参阅
函数
rmoutliers|isbetween|ischange|islocalmax|islocalmin|filloutliers|ismissing