modelDiscriminationPlot
Plot ROC curve
Syntax
Description
modelDiscriminationPlot(___,
specifies options using one or more name-value pair arguments in addition to the
input arguments in the previous syntax.Name,Value)
h = modelDiscriminationPlot(ax,___,Name,Value)h.
Examples
This example shows how to use modelDiscriminationPlot to plot the ROC curve.
Load Data
Load the credit portfolio data.
load RetailCreditPanelData.mat
disp(head(data)) ID ScoreGroup YOB Default Year
__ __________ ___ _______ ____
1 Low Risk 1 0 1997
1 Low Risk 2 0 1998
1 Low Risk 3 0 1999
1 Low Risk 4 0 2000
1 Low Risk 5 0 2001
1 Low Risk 6 0 2002
1 Low Risk 7 0 2003
1 Low Risk 8 0 2004
disp(head(dataMacro))
Year GDP Market
____ _____ ______
1997 2.72 7.61
1998 3.57 26.24
1999 2.86 18.1
2000 2.43 3.19
2001 1.26 -10.51
2002 -0.59 -22.95
2003 0.63 2.78
2004 1.85 9.48
Join the two data components into a single data set.
data = join(data,dataMacro); disp(head(data))
ID ScoreGroup YOB Default Year GDP Market
__ __________ ___ _______ ____ _____ ______
1 Low Risk 1 0 1997 2.72 7.61
1 Low Risk 2 0 1998 3.57 26.24
1 Low Risk 3 0 1999 2.86 18.1
1 Low Risk 4 0 2000 2.43 3.19
1 Low Risk 5 0 2001 1.26 -10.51
1 Low Risk 6 0 2002 -0.59 -22.95
1 Low Risk 7 0 2003 0.63 2.78
1 Low Risk 8 0 2004 1.85 9.48
Partition Data
Separate the data into training and test partitions.
nIDs = max(data.ID); uniqueIDs = unique(data.ID); rng('default'); % For reproducibility c = cvpartition(nIDs,'HoldOut',0.4); TrainIDInd = training(c); TestIDInd = test(c); TrainDataInd = ismember(data.ID,uniqueIDs(TrainIDInd)); TestDataInd = ismember(data.ID,uniqueIDs(TestIDInd));
Create Logistic Lifetime PD Model
Use fitLifetimePDModel to create a Logistic model using the training data.
pdModel = fitLifetimePDModel(data(TrainDataInd,:),'logistic',... 'ModelID','Example',... 'Description','Lifetime PD model using RetailCreditPanelData.',... 'IDVar','ID',... 'AgeVar','YOB',... 'LoanVars','ScoreGroup',... 'MacroVars',{'GDP' 'Market'},... 'ResponseVar','Default'); disp(pdModel)
Logistic with properties:
ModelID: "Example"
Description: "Lifetime PD model using RetailCreditPanelData."
UnderlyingModel: [1×1 classreg.regr.CompactGeneralizedLinearModel]
IDVar: "ID"
AgeVar: "YOB"
LoanVars: "ScoreGroup"
MacroVars: ["GDP" "Market"]
ResponseVar: "Default"
WeightsVar: ""
TimeInterval: 1
disp(pdModel.UnderlyingModel)
Compact generalized linear regression model:
logit(Default) ~ 1 + ScoreGroup + YOB + GDP + Market
Distribution = Binomial
Estimated Coefficients:
Estimate SE tStat pValue
__________ _________ _______ ___________
(Intercept) -2.7422 0.10136 -27.054 3.408e-161
ScoreGroup_Medium Risk -0.68968 0.037286 -18.497 2.1894e-76
ScoreGroup_Low Risk -1.2587 0.045451 -27.693 8.4736e-169
YOB -0.30894 0.013587 -22.738 1.8738e-114
GDP -0.11111 0.039673 -2.8006 0.0051008
Market -0.0083659 0.0028358 -2.9502 0.0031761
388097 observations, 388091 error degrees of freedom
Dispersion: 1
Chi^2-statistic vs. constant model: 1.85e+03, p-value = 0
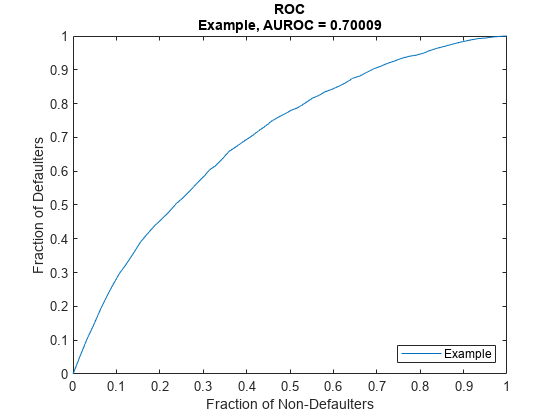
Visualize Model Discrimination
Use modelDiscriminationPlot to plot the ROC for the test data.
modelDiscriminationPlot(pdModel,data(TestDataInd,:))
Input Arguments
Name-Value Arguments
Output Arguments
More About
References
[1] Baesens, Bart, Daniel Roesch, and Harald Scheule. Credit Risk Analytics: Measurement Techniques, Applications, and Examples in SAS. Wiley, 2016.
[2] Bellini, Tiziano. IFRS 9 and CECL Credit Risk Modelling and Validation: A Practical Guide with Examples Worked in R and SAS. San Diego, CA: Elsevier, 2019.
[3] Breeden, Joseph. Living with CECL: The Modeling Dictionary. Santa Fe, NM: Prescient Models LLC, 2018.
[4] Roesch, Daniel and Harald Scheule. Deep Credit Risk: Machine Learning with Python. Independently published, 2020.
Version History
Introduced in R2021aSee Also
predictLifetime | predict | modelDiscrimination | modelCalibration | modelCalibrationPlot | fitLifetimePDModel | Logistic | Probit | Cox | customLifetimePDModel
Topics
- Basic Lifetime PD Model Validation
- Compare Logistic Model for Lifetime PD to Champion Model
- Compare Lifetime PD Models Using Cross-Validation
- Expected Credit Loss Computation
- Compare Model Discrimination and Model Calibration to Validate of Probability of Default
- Compare Probability of Default Using Through-the-Cycle and Point-in-Time Models
- Overview of Lifetime Probability of Default Models