resubMargin
Resubstitution classification margins for multiclass error-correcting output codes (ECOC) model
Description
m = resubMargin(Mdl)m) for the multiclass error-correcting output codes (ECOC) model
Mdl using the training data stored in Mdl.X and
the corresponding class labels stored in Mdl.Y.
m is returned as a numeric column vector with the same length as
Mdl.Y. The software estimates each entry of m
using the trained ECOC model Mdl, the corresponding row of
Mdl.X, and the true class label Mdl.Y.
m = resubMargin(Mdl,Name,Value)
Examples
Calculate the resubstitution classification margins for an ECOC model with SVM binary learners.
Load Fisher's iris data set. Specify the predictor data X and the response data Y.
load fisheriris
X = meas;
Y = species;Train an ECOC model using SVM binary classifiers. Standardize the predictors using an SVM template, and specify the class order.
t = templateSVM('Standardize',true);
classOrder = unique(Y)classOrder = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
Mdl = fitcecoc(X,Y,'Learners',t,'ClassNames',classOrder);
t is an SVM template object. During training, the software uses default values for empty properties in t. Mdl is a ClassificationECOC model.
Calculate the classification margins for the observations used to train Mdl. Display the distribution of the margins using a box plot.
m = resubMargin(Mdl);
boxplot(m)
title('In-Sample Margins')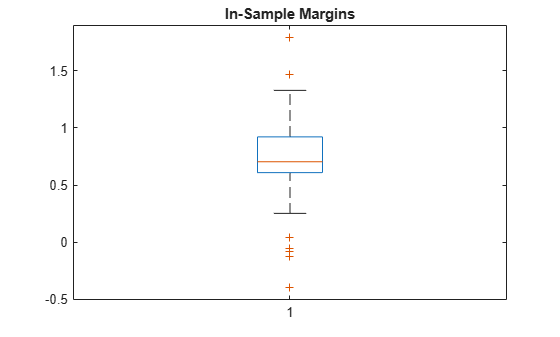
The classification margin of an observation is the positive-class negated loss minus the maximum negative-class negated loss. Choose classifiers that yield relatively large margins.
Perform feature selection by comparing training-sample margins from multiple models. Based solely on this comparison, the model with the greatest margins is the best model.
Load Fisher's iris data set. Define two data sets:
fullXcontains all four predictors.partXcontains the sepal measurements only.
load fisheriris
X = meas;
fullX = X;
partX = X(:,1:2);
Y = species;Train an ECOC model using SVM binary learners for each predictor set. Standardize the predictors using an SVM template, specify the class order, and compute posterior probabilities.
t = templateSVM('Standardize',true);
classOrder = unique(Y)classOrder = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
FullMdl = fitcecoc(fullX,Y,'Learners',t,'ClassNames',classOrder,... 'FitPosterior',true); PartMdl = fitcecoc(partX,Y,'Learners',t,'ClassNames',classOrder,... 'FitPosterior',true);
Compute the resubstitution margins for each classifier. For each model, display the distribution of the margins using a boxplot.
fullMargins = resubMargin(FullMdl); partMargins = resubMargin(PartMdl); boxplot([fullMargins partMargins],'Labels',{'All Predictors','Two Predictors'}) title('Training-Sample Margins')

The margin distribution of FullMdl is situated higher and has less variability than the margin distribution of PartMdl. This result suggests that the model trained with all the predictors fits the training data better.
Input Arguments
Name-Value Arguments
More About
Tips
To compare the margins or edges of several ECOC classifiers, use template objects to specify a common score transform function among the classifiers during training.
References
Extended Capabilities
Version History
Introduced in R2014b
See Also
ClassificationECOC | resubEdge | margin | predict | resubPredict | fitcecoc | resubLoss