smooth
平滑响应数据
语法
说明
示例
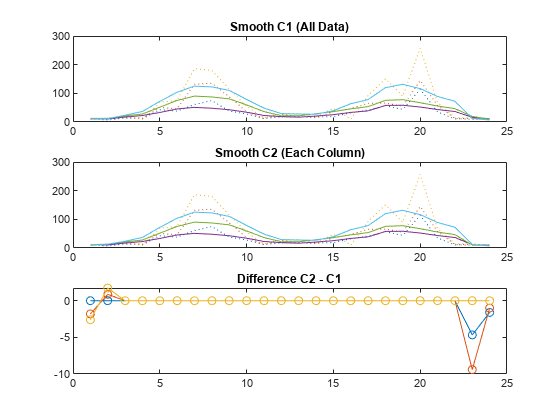
使用移动平均滤波器,分别按线性索引和每列平滑数据。绘制并比较结果。
将数据加载到 count.dat 中。24×3 数组 count 包含三个十字路口在一天中每个小时的流量统计。
load count.dat假设数据来自一个十字路口连续三天的流量统计。对所有数据一起进行平滑处理,就可以指示出通过十字路口的交通流量的整个周期。使用跨度为 5 小时的移动平均滤波器同时平滑处理所有数据(通过线性索引)。
c = smooth(count(:)); C1 = reshape(c,24,3);
然而,数据实际上来自三个不同十字路口。因此,按列平滑处理会给出一天中通过每个十字路口的更有意义的交通状况。使用相同的移动平均滤波器分别平滑处理每列数据。
C2 = zeros(24,3); for I = 1:3 C2(:,I) = smooth(count(:,I)); end
分别按线性索引和按每列绘制原始数据和平滑处理后的数据。然后,绘制两个经过平滑处理的数据集之间的差异。这两种方法在端点附近给出不同结果。
subplot(3,1,1) plot(count,':'); hold on plot(C1,'-'); title('Smooth C1 (All Data)') subplot(3,1,2) plot(count,':'); hold on plot(C2,'-'); title('Smooth C2 (Each Column)') subplot(3,1,3) plot(C2 - C1,'o-') title('Difference C2 - C1')
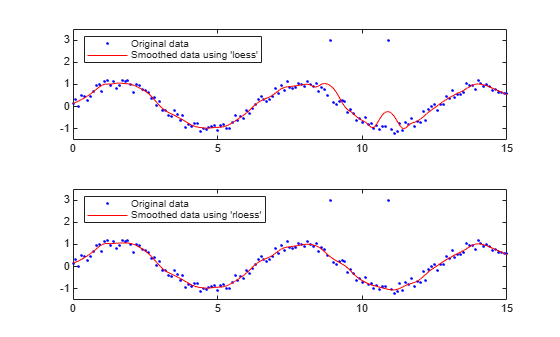
绘制并比较使用 loess 和 rloess 方法平滑处理的数据结果。然后确定哪种方法对离群值更不敏感。
创建具有两个离群值的含噪数据。
x = (0:0.1:15)'; y = sin(x) + 0.5*(rand(size(x))-0.5); y([90,110]) = 3;
使用 loess 和 rloess 方法平滑处理数据。使用数据点总数的 10% 作为跨度。
yy1 = smooth(x,y,0.1,'loess'); yy2 = smooth(x,y,0.1,'rloess');
绘制原始数据和经过平滑处理的数据。使用稳健方法 rloess 时离群值的影响较小。
subplot(2,1,1) plot(x,y,'b.',x,yy1,'r-') set(gca,'YLim',[-1.5 3.5]) legend('Original data','Smoothed data using ''loess''',... 'Location','NW') subplot(2,1,2) plot(x,y,'b.',x,yy2,'r-') set(gca,'YLim',[-1.5 3.5]) legend('Original data','Smoothed data using ''rloess''',... 'Location','NW')
输入参数
输出参量
提示
您可以使用平滑样条生成对数据的平滑拟合。有关详细信息,请参阅
fit。
替代功能
您也可以使用 MATLAB® smoothdata 函数来平滑数据。除了 GPU 数组支持之外,smoothdata 包括 smooth 函数的所有功能,还具有一些优势。与 smooth 不同,smoothdata 函数支持:
矩阵、表和时间表
移动中位数和高斯方法
用于指定如何处理
NaN值的选项用经过平滑处理的数据代换原始矩阵或将经过平滑处理的数据追加到原始矩阵的选项
tall 数组、C/C++ 代码生成和基于线程的环境
扩展功能
版本历史记录
在 R2006a 之前推出