使用类激活映射调查网络预测
此示例说明如何使用类激活映射 (CAM) 来调查和解释用于图像分类的深度卷积神经网络的预测。
深度学习网络通常被认为是“黑匣子”,人们无法搞清楚网络到底学到了什么或网络输入的哪一部分与网络预测有关。当这些模型失败并给出不正确的预测时,往往错得十分离谱,而且不会给出任何警告或解释。类激活映射 [1] 是一种可用于直观解释卷积神经网络预测的方法。不正确的、看似不合理的预测通常会有合理的解释。使用类激活映射,您可以检查输入图像的特定部分是否让网络产生“混淆”并导致它作出错误的预测。
您可以使用类激活映射来识别训练集中的偏置,并提高模型准确度。如果您发现网络基于错误的特征进行预测,则您可以通过收集更好的数据来使网络更加稳健。例如,假设您训练网络来区分猫和狗的图像。该网络在训练集上具有很高的准确度,但在现实世界的示例中表现不佳。通过对训练示例使用类激活映射,您发现网络不是基于图像中的猫和狗而是基于背景在进行预测。然后您意识到您的所有猫图片都有红色背景,您的所有狗图片都有绿色背景,这是网络在训练中学习到的背景颜色。然后您可以收集没有这种偏置的新数据。
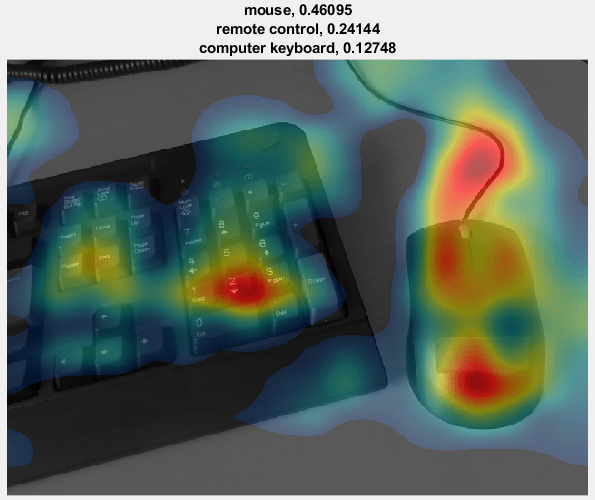
以下示例类激活映射显示输入图像的哪些区域对预测类 mouse 贡献最大。红色区域贡献最大。
加载预训练的网络和网络摄像头
加载预训练的卷积神经网络进行图像分类。SqueezeNet、GoogLeNet、ResNet-18 和 MobileNet-v2 是相对较快的网络。SqueezeNet 是最快的网络,它的类激活映射的分辨率是其他网络映射的四倍。您无法对网络末端有多个全连接层的网络(如 AlexNet、VGG-16 和 VGG-19)使用类激活映射。
netName =  "resnet18";
[net, classNames] = imagePretrainedNetwork(netName);
"resnet18";
[net, classNames] = imagePretrainedNetwork(netName);创建一个 webcam 对象并连接到您的网络摄像头。
camera = webcam;
提取图像输入大小。在本示例末尾定义的 activationLayerName 辅助函数返回从中提取激活的层的名称。该层是网络的最后一个卷积层后的 ReLU 层。
inputSize = net.Layers(1).InputSize(1:2); layerName = activationLayerName(netName);
显示类激活映射
创建一个图窗并以循环方式执行类激活映射。要终止循环的执行,请关闭图窗。
h = figure('Units','normalized','Position',[0.05 0.05 0.9 0.8],'Visible','on'); while ishandle(h)
使用网络摄像头拍摄快照。调整图像大小,使其最短边的长度(本例中为图像高度)等于网络的图像输入大小。在您调整大小时,保留图像的纵横比。您也可以将图像大小调整为更大或更小。放大图像会提高最终类激活映射的分辨率,但会导致整体预测不太准确。
计算网络最后一个卷积层后的 ReLU 层中调整大小后的图像的激活区域。
im = snapshot(camera);
imResized = imresize(im,[inputSize(1), NaN]);
imageActivations = predict(net,single(imResized),Outputs=layerName);特定类的类激活映射是最后一个卷积层之后的 ReLU 层的激活映射,由每个激活对该类的最终得分的贡献程度来加权。这些权重等于网络的最终全连接层对该类的权重。SqueezeNet 没有最终全连接层。最后一个卷积层后的 ReLU 层的输出已经是类激活映射。
您可以为任何输出类生成一个类激活映射。例如,如果网络分类不正确,您可以比较真实类和预测类的类激活映射。对于本示例,我们为得分最高的预测类生成类激活映射。
scores = squeeze(mean(imageActivations,[1 2]));
if netName ~= "squeezenet"
fcWeights = net.Layers(end-1).Weights;
fcBias = net.Layers(end-1).Bias;
scores = fcWeights*scores + fcBias;
[~,classIds] = maxk(scores,3);
weightVector = shiftdim(fcWeights(classIds(1),:),-1);
classActivationMap = sum(imageActivations.*weightVector,3);
else
[~,classIds] = maxk(scores,3);
classActivationMap = imageActivations(:,:,classIds(1));
end
计算顶层类标签和最终归一化类分数。
scores = exp(scores)/sum(exp(scores));
maxScores = scores(classIds);
labels = classNames(classIds);绘制类激活映射。在第一个子图中显示原始图像。在第二个子图中,使用在本示例末尾定义的 CAMshow 辅助函数,在原始图像的暗灰度版本之上显示类激活映射。显示前三个预测标签及其预测分数。
subplot(1,2,1)
imshow(im)
subplot(1,2,2)
CAMshow(im,classActivationMap)
title(string(labels) + ", " + string(maxScores));
drawnow
end清除网络摄像头对象。
clear camera映射示例
网络将下列图像中的物品正确识别为休闲鞋(一种鞋)。右侧图像中的类激活映射显示输入图像的每个区域对预测的类 Loafer 的贡献。红色区域贡献最大。网络基于整只鞋对其分类,但最强的输入来自红色区域 - 即鞋尖和鞋口。

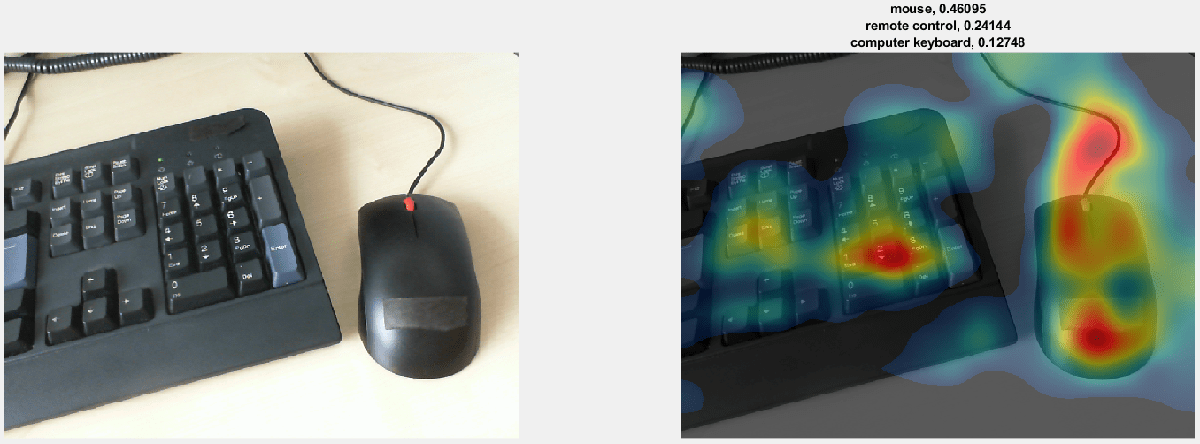
网络将下面图像分类为鼠标。正如类激活映射所示,预测不仅基于图像中的鼠标,还基于键盘。由于训练集可能包含许多鼠标与键盘一起出现的图像,网络预测包含键盘的图像更可能包含鼠标。
网络将下面的咖啡杯图像归类为扣环。如类激活映射所示,网络对图像进行了错误分类,因为图像包含太多容混淆物品。网络检测并重点关注手表腕带,而不是咖啡杯。

辅助函数
CAMshow(im,CAM) 在图像 im 的暗灰色版本上叠加类激活映射 CAM。该函数将类激活映射调整为 im 的大小,对其进行归一化,为其设置下限阈值,并使用 jet 颜色图将其可视化。
function CAMshow(im,CAM) imSize = size(im); CAM = imresize(CAM,imSize(1:2)); CAM = normalizeImage(CAM); CAM(CAM<0.2) = 0; cmap = jet(255).*linspace(0,1,255)'; CAM = ind2rgb(uint8(CAM*255),cmap)*255; combinedImage = double(rgb2gray(im))/2 + CAM; combinedImage = normalizeImage(combinedImage)*255; imshow(uint8(combinedImage)); end function N = normalizeImage(I) minimum = min(I(:)); maximum = max(I(:)); N = (I-minimum)/(maximum-minimum); end function layerName = activationLayerName(netName) if netName == "squeezenet" layerName = 'relu_conv10'; elseif netName == "googlenet" layerName = 'inception_5b-output'; elseif netName == "resnet18" layerName = 'res5b_relu'; elseif netName == "mobilenetv2" layerName = 'out_relu'; end end
参考
[1] Zhou, Bolei, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. "Learning deep features for discriminative localization." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2921-2929. 2016.
另请参阅
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | predict | forward | occlusionSensitivity | gradCAM | imageLIME