n4sid
使用时域或频域数据子空间方法估计状态空间模型
语法
说明
估计状态空间模型
sys = n4sid(tt,nx)sys 中的所有输入和输出信号估计 nx 阶离散时间状态空间模型 tt。
sys 是以下形式的模型:
A、B、C、D 和 K 是状态空间矩阵。u (t) 是输入,y (t) 是输出,e (t) 是扰动,x (t) 是 nx 状态向量。
A、B、C 和 K 的所有条目默认都是可自由估计的参数。对于动态系统,D 默认固定为零,这意味着系统没有馈通。对于静态系统 (nx = 0),D 默认是一个可估计参数。
您可以将此语法用于 SISO 和 MISO 系统。该函数假定时间表中的最后一个变量是单个输出信号。如果 tt 包含代表唯一输出的单个变量,您也可以使用此语法来估计时间序列模型。
对于 MIMO 系统和包含比您计划用于估计的变量更多的变量的时间表,您还必须使用名称-值参量来指定所需的输入和输出通道的名称。有关详细信息,请参阅 tt。
要估计连续时间模型,请使用名称-值语法将 'Ts' 设置为 0。
指定附加选项
sys = n4sid(___,Name,Value)'Ts' 指定为 0。使用 'Form'、'Feedthrough' 和 'DisturbanceModel' 名称-值对组参量来修改 A、B、C、D 和 K 矩阵的默认行为。
此语法可与上述任一输入参量组合结合使用。
示例
估计状态空间模型并将其响应与测量的输出进行比较。
加载存储在时间表中的输入-输出数目据 tt1。
load sdata1.mat tt1
估计四阶状态空间模型。
nx = 4; sys = n4sid(tt1,nx)
sys =
Discrete-time identified state-space model:
x(t+Ts) = A x(t) + B u(t) + K e(t)
y(t) = C x(t) + D u(t) + e(t)
A =
x1 x2 x3 x4
x1 0.8392 0.3129 -0.02105 0.03743
x2 -0.4768 0.6671 0.1428 -0.003757
x3 0.01951 0.08374 -0.09761 -1.046
x4 -0.003885 0.02914 0.8796 -0.03171
B =
u
x1 0.02635
x2 0.03301
x3 -7.256e-05
x4 0.0005861
C =
x1 x2 x3 x4
y 69.08 -26.64 2.237 -0.5601
D =
u
y 0
K =
y
x1 0.003282
x2 -0.009339
x3 0.003232
x4 0.003809
Sample time: 0.1 seconds
Parameterization:
FREE form (all coefficients in A, B, C free).
Feedthrough: none
Disturbance component: estimate
Number of free coefficients: 28
Use "idssdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using N4SID on time domain data "tt1".
Fit to estimation data: 76.33% (prediction focus)
FPE: 1.21, MSE: 1.087
Model Properties
将仿真模型响应与测量的输出进行比较。
compare(tt1,sys)

该图显示仿真模型与估计数据的拟合度百分比大于 70%。
您可以通过探索 idss 属性 sys.Report 来查看有关估计的详细信息。
sys.Report
ans =
Status: 'Estimated using N4SID with prediction focus'
Method: 'N4SID'
InitialState: 'estimate'
N4Weight: 'CVA'
N4Horizon: [6 10 10]
Fit: [1×1 struct]
Parameters: [1×1 struct]
OptionsUsed: [1×1 idoptions.n4sid]
RandState: [1×1 struct]
DataUsed: [1×1 struct]
例如,找出有关估计的初始状态的详细信息。
sys.Report.Parameters.X0
ans = 4×1
-0.0085
-0.0052
0.0193
0.0282
加载输入/输出数目据 umat1 和 ymat1(它们是数值矩阵)以及采样时间 Ts。
load sdata1 umat1 ymat1 Ts
通过将参量 nx 指定为 1 到 10 的范围来确定最佳模型阶数。
nx = 1:10;
sys = n4sid(umat1,ymat1,nx,'Ts',Ts);自动生成的图显示了由 nx 指定的阶数的模型的 Hankel 奇异值。
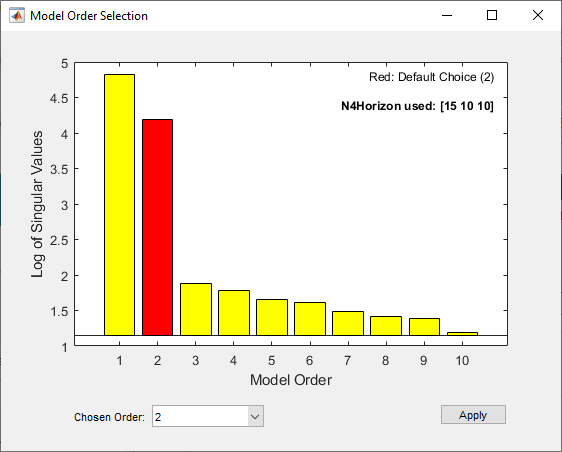
具有相对较小的 Hankel 奇异值的状态可以被安全地丢弃。建议的默认阶数选择是 2。
在 Chosen Order 列表中选择模型阶数,然后点击 Apply。
加载估计数据。
load iddata2 z2
指定估计选项。将加权方案 'N4Weight' 设置为 'SSARX',将估计状态显示选项 'Display' 设置为 'on'。
opt = n4sidOptions('N4Weight','SSARX','Display','on')
Option set for the n4sid command:
InitialState: 'estimate'
N4Weight: 'SSARX'
N4Horizon: 'auto'
Display: 'on'
InputOffset: []
OutputOffset: []
EstimateCovariance: 1
OutputWeight: []
Focus: 'prediction'
WeightingFilter: []
EnforceStability: 0
Advanced: [1×1 struct]
Description of options
使用更新的选项集估计三阶状态空间模型。
nx = 3; sys = n4sid(z2,nx,opt);
修改 A、B 和 C 矩阵的标准形式,在 D 矩阵中包含一个馈通通项,并消除 K 矩阵中的扰动模型估计。
加载输入-输出数目据并使用 n4sid 默认选项估计四阶系统。
load sdata1 tt1 sys1 = n4sid(tt1,4);
指定模态形式并将 A 矩阵与默认的 A 矩阵进行比较。
sys2 = n4sid(tt1,4,'Form','modal'); A1 = sys1.A
A1 = 4×4
0.8392 0.3129 -0.0211 0.0374
-0.4768 0.6671 0.1428 -0.0038
0.0195 0.0837 -0.0976 -1.0462
-0.0039 0.0291 0.8796 -0.0317
A2 = sys2.A
A2 = 4×4
0.7554 0.3779 0 0
-0.3779 0.7554 0 0
0 0 -0.0669 0.9542
0 0 -0.9542 -0.0669
包括一个馈通通项并比较 D 矩阵。
sys3 = n4sid(tt1,4,'Feedthrough',1);
D1 = sys1.DD1 = 0
D3 = sys3.D
D3 = 0.0487
消除干扰建模并比较 K 矩阵。
sys4 = n4sid(tt1,4,'DisturbanceModel','none'); K1 = sys1.K
K1 = 4×1
0.0033
-0.0093
0.0032
0.0038
K4 = sys4.K
K4 = 4×1
0
0
0
0
估计连续时间标准形式模型。
加载估计数据。
load iddata1 z1
估计模型。将 Ts 设置为 0 以指定连续模型。
nx = 2; sys = n4sid(z1,nx,'Ts',0,'Form','canonical');
sys 是标准形式的二阶连续时间状态空间模型。
使用子空间算法 SSARX 从闭环数据估计状态空间模型。该算法比其他加权算法更能捕获反馈效应。
为受白噪声破坏的二阶系统生成闭环估计数据。
N = 1000; K = 0.5; rng('default'); w = randn(N,1); z = zeros(N,1); u = zeros(N,1); y = zeros(N,1); e = randn(N,1); v = filter([1 0.5],[1 1.5 0.7],e); for k = 3:N u(k-2) = -K*y(k-2) + w(k-2); u(k-1) = -K*y(k-1) + w(k-1); z(k) = 1.5*z(k-1) - 0.7*z(k-2) + u(k-1) + 0.5*u(k-2); y(k) = z(k) + 0.8*v(k); end dat = iddata(y, u, 1);
指定 N4SID 算法使用的加权方案 'N4weight'。创建两个选项集。对于一个选项集,将 'N4weight' 设置为 'CVA'。对于其他选项集,将 'N4weight' 设置为 'SSARX'。
optCVA = n4sidOptions('N4weight','CVA'); optSSARX = n4sidOptions('N4weight','SSARX');
使用选项集估计状态空间模型。
sysCVA = n4sid(dat,2,optCVA); sysSSARX = n4sid(dat,2,optSSARX);
将两个模型与估计数据的拟合度进行比较。
compare(dat,sysCVA,sysSSARX);
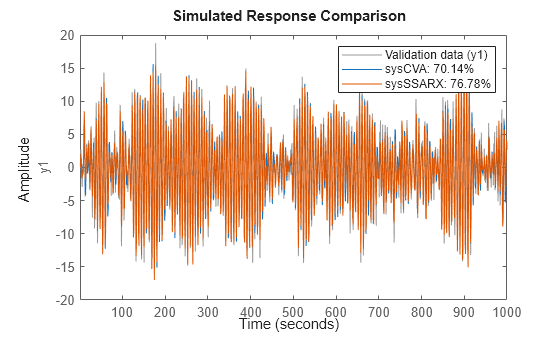
如图所示,使用 SSARX 算法估计的模型比使用 CVA 算法估计的模型拟合效果更好。
输入参数
名称-值参数
输出参量
参考
[1] Ljung, L. System Identification: Theory for the User, Appendix 4A, Second Edition, pp. 132–134. Upper Saddle River, NJ: Prentice Hall PTR, 1999.
[2] van Overschee, P., and B. De Moor. Subspace Identification of Linear Systems: Theory, Implementation, Applications. Springer Publishing: 1996.
[3] Verhaegen, M. "Identification of the deterministic part of MIMO state space models." Automatica, 1994, Vol. 30, pp. 61–74.
[4] Larimore, W.E. "Canonical variate analysis in identification, filtering and adaptive control." Proceedings of the 29th IEEE Conference on Decision and Control, 1990, pp. 596–604.
[5] McKelvey, T., H. Akcay, and L. Ljung. "Subspace-based multivariable system identification from frequency response data." IEEE Transactions on Automatic Control, 1996, Vol. 41, pp. 960–979.