colamd
列近似最小度排列
说明
示例
由稀疏矩阵组成的 Harwell-Boeing 集合和 MATLAB® demos 目录包含测试矩阵 west0479。它是一个 479 阶的矩阵,产生于八个阶段的化工精馏塔的 Westerberg 模型。spy 图显示了八个阶段的证据。colamd 排序使此结构体变得混乱。
load west0479 A = west0479; p = colamd(A); figure() subplot(1,2,1), spy(A,4), title('A') subplot(1,2,2), spy(A(:,p),4), title('A(:,p)')

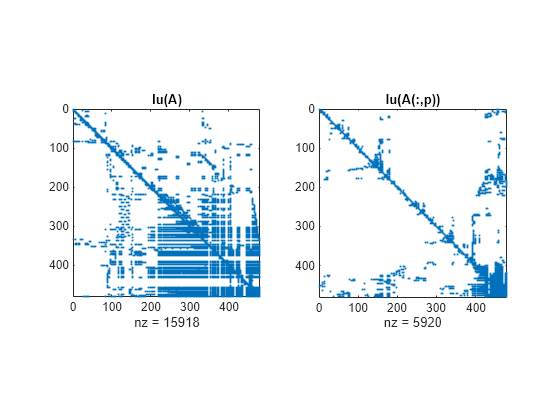
将原始矩阵的 LU 分解的 spy 图与重新排序后的矩阵的 spy 图进行比较,结果表明最小度比因子为 2.8 时降低了时间和存储要求。非零计数分别为 15918 和 5920。
figure() subplot(1,2,1), spy(lu(A),4), title('lu(A)') subplot(1,2,2), spy(lu(A(:,p)),4), title('lu(A(:,p))')
输入参数
输出参量
参考
[1] Davis, Timothy A., John R. Gilbert, Stefan I. Larimore, and Esmond G. Ng. “Algorithm 836: COLAMD, a Column Approximate Minimum Degree Ordering Algorithm.” ACM Transactions on Mathematical Software 30, no. 3 (September 2004): 377–380. https://doi.org/10.1145/1024074.1024080.