dissect
嵌套剖分置换
说明
示例
用多种方法对稀疏矩阵重新排序,并比较重排矩阵的 LU 分解所产生的填充。
加载 west0479 矩阵,它是一个具有实数值的 479×479 稀疏矩阵,同时包含实共轭和复共轭特征值对。查看稀疏结构体。
load west0479.mat
A = west0479;
spy(A)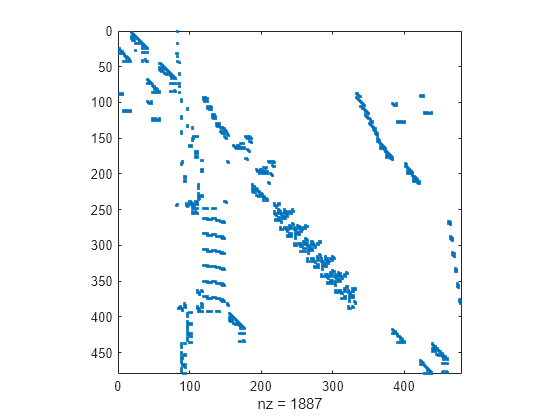
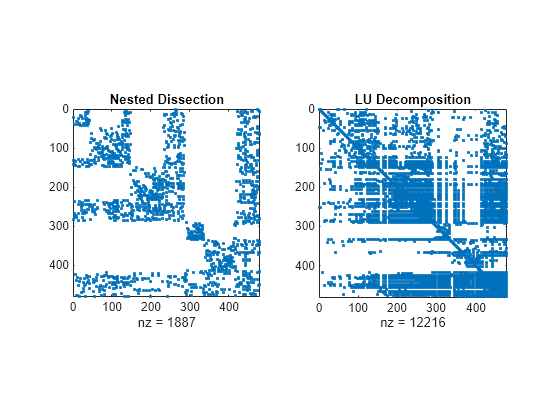
计算矩阵列的几种不同置换,包括嵌套剖分排序。
p1 = dissect(A); p2 = amd(A); p3 = symrcm(A);
使用不同的排序方法比较 A 的 LU 分解的稀疏结构。运行 dissect 函数产生的重新排序可使填充量最小。
subplot(1,2,1) spy(A) title('Original Matrix') subplot(1,2,2) spy(lu(A)) title('LU Decomposition')
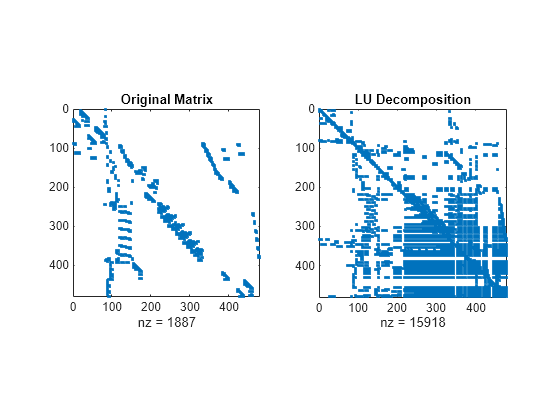
figure subplot(1,2,1) spy(A(p3,p3)) title('Reverse Cuthill-McKee') subplot(1,2,2) spy(lu(A(p3,p3))) title('LU Decomposition')
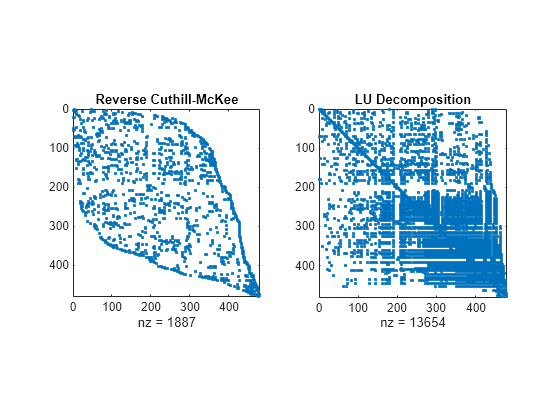
figure subplot(1,2,1) spy(A(p2,p2)) title('Approximate Minimum Degree') subplot(1,2,2) spy(lu(A(p2,p2))) title('LU Decomposition')
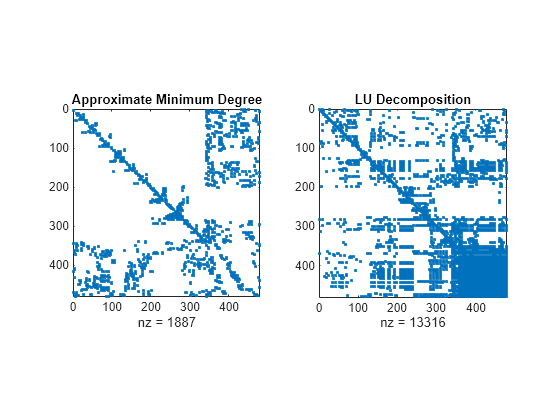
figure subplot(1,2,1) spy(A(p1,p1)) title('Nested Dissection') subplot(1,2,2) spy(lu(A(p1,p1))) title('LU Decomposition')
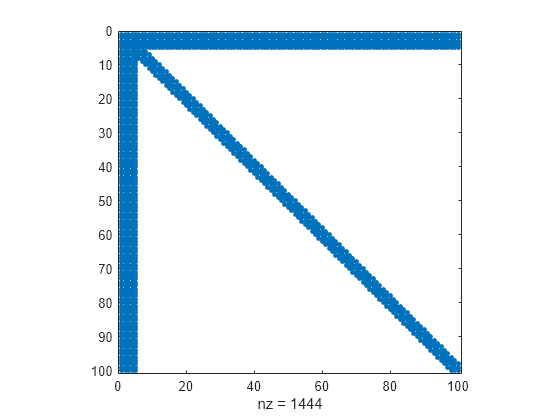
箭尖矩阵是包含若干密集列的稀疏矩阵。可以使用 'MaxDegreeThreshold' 名称-值对组将密集列过滤出来,放在重排矩阵的末尾。
创建一个箭尖稀疏矩阵并查看稀疏模式。
A = speye(100) + diag(ones(1,99),1) + diag(ones(1,98),2); A(1:5,:) = ones(5,100); A = A + A'; spy(A)
计算嵌套剖分排序,并过滤出具有 10 个以上非零元素的列。
p = dissect(A,'MaxDegreeThreshold',10);查看重排矩阵的稀疏模式。dissect 将密集列放在重排矩阵的末尾。
spy(A(p,p))

输入参数
名称-值参数
输出参量
算法
[1] 中介绍的嵌套剖分排序算法是一种多级图形分区算法,用于对稀疏矩阵进行减少填充量的排序。输入矩阵被视为图形的邻接矩阵。该算法通过折叠顶点和边来粗化图形,重排较小的图形,然后通过细化步骤对较小图形去粗,得到重排的原始图形。
dissect 的名称-值对组使您能够控制算法的各个阶段:
粗化
在此阶段,算法将相邻的顶点对组折叠,从原始图生成连续的更小的图。您可以借助
'MaxDegreeThreshold',最后再对高度连接的图顶点(矩阵中的密集列)进行排序,以将它们过滤出来。分区
在图形粗化后,算法对更小的图形彻底重新排序。在每个分区步骤中,算法尝试将图形分成相等的部分:
'NumSeparators'指定将图形分成多少部分,'VertexWeights'为顶点分配权重(可选),而'MaxImbalance'指定不同分区之间权重差的阈值。细化
在对最小的图形重新排序后,算法展开之前合并的顶点进行投影,将图形放大到原始大小。在每个投影步骤后,执行细化步骤,移除分区之间的顶点,以提高解的质量。
'NumIterations'控制该去粗阶段使用的细化步骤的数量。
参考
[1] Karypis, George and Vipin Kumar. "A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs." SIAM Journal on Scientific Computing. Vol. 20, Number 1, 1999, pp. 359–392.
扩展功能
版本历史记录
在 R2017b 中推出