稀疏矩阵运算
运算效率
计算复杂度
稀疏运算的计算复杂度与矩阵中的非零元素数 nnz 成比例。计算复杂度在线性上还与矩阵的行大小 m 和列大小 n 相关,但与积 m*n(零元素和非零元素总数)无关。
相当复杂的运算(例如对稀疏线性方程求解)的复杂度涉及如排序和填充之类的因素,已在上一部分中对这些因素进行了讨论。通常,稀疏矩阵运算所需的计算时间通常与非零元素数量中的算术运算数成比例。
算法详细信息
根据以下规则,稀疏矩阵通过计算传播:
接受矩阵并返回标量或等尺寸向量的函数始终都以满存储格式生成输出。例如,无论其输入是完全还是稀疏模式,
size函数始终都返回满向量。接受标量或向量并返回矩阵的函数始终都返回完全结果,例如
zeros、ones、rand和eye。该操作十分必要,可以避免意外引入稀疏。zeros(m,n)的稀疏模拟函数即是sparse(m,n)。rand和eye的稀疏模拟函数分别是sprand和speye。函数ones没有稀疏模拟。接受矩阵并返回矩阵或向量的一元函数保留存储类的操作数。如果
S是稀疏矩阵,则chol(S)也是稀疏矩阵,diag(S)是稀疏向量。如max和sum之类的列级函数也返回稀疏向量,即使这些向量完全为非零元素也是如此。该规则的重要例外是sparse和full函数。如果两个操作数都是稀疏元素,则二元运算符生成稀疏结果;如果两个操作数都是完全元素,则生成完全结果。对于混合操作数,除非运算保留稀疏性,否则生成完全结果。如果
S是稀疏矩阵,而F是满矩阵,则S+F、S*F和F\S是满矩阵,而S.*F和S&F是稀疏矩阵。在某些情况下,即使矩阵包含很少的零元素,也可能是稀疏结果。使用
cat函数或方括号串联矩阵会为混合操作数生成稀疏结果。
置换与重新排序
可以通过以下两种方式表示稀疏矩阵 S 的行和列置换:
置换矩阵
P对作为P*S的S有效,或对作为S*P'的列有效。置换向量
p是包含1:n置换的满向量。对作为S(p,:)的S行有效,或对作为S(:,p)的列有效。
例如:
p = [1 3 4 2 5] I = eye(5,5); P = I(p,:) e = ones(4,1); S = diag(11:11:55) + diag(e,1) + diag(e,-1)
p =
1 3 4 2 5
P =
1 0 0 0 0
0 0 1 0 0
0 0 0 1 0
0 1 0 0 0
0 0 0 0 1
S =
11 1 0 0 0
1 22 1 0 0
0 1 33 1 0
0 0 1 44 1
0 0 0 1 55现在,可以使用置换向量 p 和置换矩阵 P 尝试一些置换。例如,语句 S(p,:) 和 P*S 返回相同的矩阵。
S(p,:)
ans =
11 1 0 0 0
0 1 33 1 0
0 0 1 44 1
1 22 1 0 0
0 0 0 1 55P*S
ans =
11 1 0 0 0
0 1 33 1 0
0 0 1 44 1
1 22 1 0 0
0 0 0 1 55同样,S(:,p) 和 S*P' 都生成
S*P'
ans =
11 0 0 1 0
1 1 0 22 0
0 33 1 1 0
0 1 44 0 1
0 0 1 0 55如果 P 是稀疏矩阵,则两种表示都使用与 n 成比例的存储,可以在与 nnz(S) 成正比的时间向 S 应用任一种表示。向量表示略为简洁和有效,因此除了 LU(三角)分解中的主元置换返回与完全 LU 分解兼容的矩阵外,许多稀疏矩阵置换例程都返回满行向量。
要在两种置换表示之间转换:
n = 5; I = speye(n); Pr = I(p,:); Pc = I(:,p); pc = (1:n)*Pc
pc =
1 3 4 2 5pr = (Pr*(1:n)')'
pr =
1 3 4 2 5P 的逆为 R = P'。可以通过 r(p) = 1:n 计算 p 的逆。
r(p) = 1:5
r =
1 4 2 3 5重新排序以改变稀疏性
对矩阵列重新排序通常可以使其 LU 或 QR 因子更加稀疏。对列和列重新排序通常可以使其乔列斯基因子更加稀疏。此类最简单的重新排序是按照非零元素计数为列排序。对于具有及其不规则结构的矩阵而言,这有时是一个不错的重新排序方法,尤其是行或列的非零元素计数出现重大变化时更是如此。
colperm 函数按每列中非零元素数量从小到大的顺序重排矩阵列,计算矩阵的置换。
重新排序以减少带宽
反向卡西尔-麦基排序用于减少矩阵的轮廓或带宽。该排序方法不能保证会找到尽可能最小的带宽,但通常都能找到。symrcm 函数实际上处理的是对称矩阵 A + A' 中的非零结构体。但对于非对称矩阵,该函数的结果也很有用。此种排序对源自一维问题或某种意义上细长的问题的矩阵很有用。
近似最小度排序
节点在图中的度是到该节点的连接数。这与邻接矩阵的相应行中的非对角非零元素数相同。近似最小度算法基于高斯消去法或乔列斯基分解期间这些度的更改来进行排序。该算法很复杂并且功能强大,通常会生成比大多数其他排序稀疏的因子,包含列计数和反向卡西尔-麦基。由于记录每个节点的度非常耗时,因此近似最小度算法使用近似度而不是精确度。
以下 MATLAB® 函数可以实现近似最小度算法:
请参阅稀疏矩阵的重新排序和分解以了解使用 symamd 的示例。
可以使用 spparms 函数更改与这些算法详细信息相关的不同参数。
嵌套剖分排序
dissect 函数所实现的嵌套剖分排序算法与近似最小度排序类似,即通过将矩阵视为图的邻接矩阵,对矩阵的行和列进行重新排序。该算法通过将图中的顶点对折叠在一起,大幅减小问题的规模。在对较小的图重新排序后,该算法随即通过应用投影和细化步骤,将图恢复至原始大小。
与其他重新排序方法相比,嵌套剖分算法可生成高质量的重新排序,尤其适用于有限元矩阵。有关嵌套剖分排序算法的详细信息,请参阅 [7]。
稀疏矩阵分解
LU 分解
如果 S 是稀疏矩阵,则以下命令返回三个稀疏矩阵:L、U 和 P,这样 P*S = L*U。
[L,U,P] = lu(S);
lu 使用高斯消去法和部分主元消去法获取因子。置换矩阵 P 仅有 n 个非零元素。和稠密矩阵一样,语句 [L,U] = lu(S) 返回置换的单位下三角矩阵和其积为 S 的上三角矩阵。lu(S) 本身在单个矩阵中返回 L 和 U,没有主元信息。
有三个输出的语法 [L,U,P] = lu(S) 通过数值部分主元消去法选择 P,但不执行主元消去法来改进 LU 因子中的稀疏性。另一方面,有四个输出的语法 [L,U,P,Q] = lu(S) 通过阈值部分主元消去法选择 P,并选择 P 和 Q 以改善 LU 因子中的稀疏性。
可以使用以下项控制稀疏矩阵中的主元
lu(S,thresh)
其中 thresh 是 [0,1] 中的主元阈值。列中对角线元素的模小于该列中任何子对角线元素模的 thresh 倍时会选主元。thresh = 0 强迫选择对角主元。thresh = 1 是默认值。(thresh 的默认值是四输出语法的 0.1)。
调用不超过三个输出的 lu 时,MATLAB 会在分解期间自动分配存储稀疏 L 和 U 因子所必需的内存。除了四个输出的语法外,MATLAB 不使用任何符号 LU 预分解确定内存要求和提前设置数据结构体。
稀疏矩阵的重新排序和分解
此示例说明重新排序与分解对稀疏矩阵的影响。
如果您求得可减少填充项的良好列置换矩阵 p(可能通过 symrcm 或 colamd 求得),则计算 lu(S(:,p)) 所需的时间和存储将少于计算 lu(S) 所需的时间和存储。
使用布基球示例创建稀疏矩阵。
B = bucky;
B 在每一个行和列都有恰好 3 个非零元素。
分别使用 symrcm 和 symamd 创建两个置换 r 和 m。
r = symrcm(B); m = symamd(B);
这两个置换是对称反向卡西尔-麦基排序和对称近似最小度排序。
创建稀疏模式图,显示具有以下三个不同数序的三个布基球图邻接矩阵。原始数序对应的局部五边形结构在其他结构中并不明显。
figure subplot(1,3,1) spy(B) title('Original') subplot(1,3,2) spy(B(r,r)) title('Reverse Cuthill-McKee') subplot(1,3,3) spy(B(m,m)) title('Min Degree')
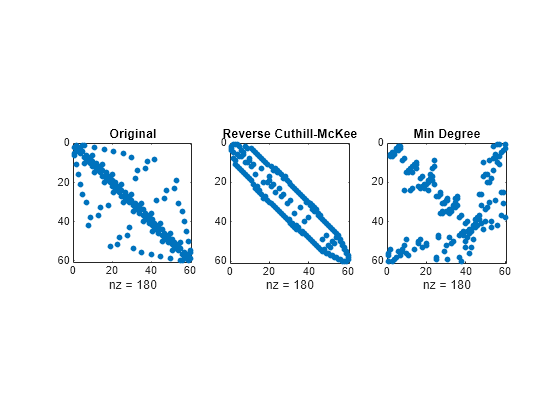
反向卡西尔-麦基排序 r 减小了带宽,并将所有非零元素集中在对角线附近。近似最小度排序 m 则生成了包含大块零的类分形结构。
要查看在布基球 LU 分解中生成的填充元素,请使用稀疏单位矩阵 speye 在 B 的对角线上插入 -3。
B = B - 3*speye(size(B));
由于每一行的和现在为零,因此新的 B 实际为奇异矩阵,但它仍有助于计算其 LU 分解。当仅使用一个输出参量调用时,lu 会在一个稀疏矩阵中返回两个三角矩阵 L 和 U。该矩阵中的非零元素数量是在解算涉及 B 的线性系统时所需的时间和存储测度。
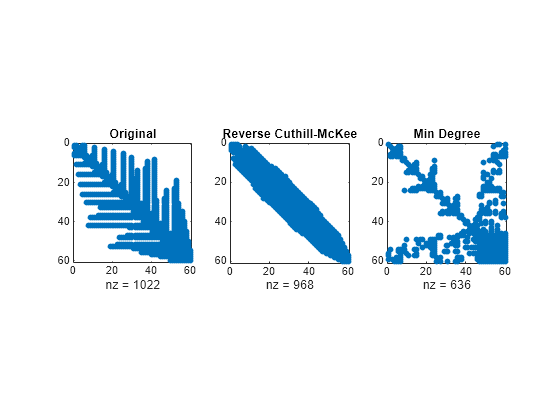
以下是当前考虑的三个置换的非零计数。
lu(B)(原始):1022lu(B(r,r))(反向卡西尔-麦基排序):968lu(B(m,m))(近似最小度):636
尽管这只是一个很小的示例,但结果却非常典型。原始数序方案产生的填充元素最多。反向卡西尔-麦基排序的填充元素集中在波段以内,但几乎与前两个排序一样广泛。对于近似最小度排序,在消元过程中保留了相对较大的零块,并且填充量远小于其他排序所生成的填充量。
以下 spy 绘图反映了每个重新排序的特征。
figure subplot(1,3,1) spy(lu(B)) title('Original') subplot(1,3,2) spy(lu(B(r,r))) title('Reverse Cuthill-McKee') subplot(1,3,3) spy(lu(B(m,m))) title('Min Degree')
乔列斯基分解
如果 S 是对称(或埃尔米特)的正定稀疏矩阵,下面的语句返回上三角稀疏矩阵 R,这样 R'*R = S。
R = chol(S)
chol 不会针对稀疏度自动选主元,但可以计算近似最小度和描述文件极限置换以用于 chol(S(p,p))。
由于乔列斯基算法不会针对稀疏度选主元,也不需要选主元以保持数值稳定性,chol 将快速计算所需的内存量并在分解开始时分配所有的内存。可以使用 symbfact 计算分配的内存量,该函数使用与 chol 相同的算法。
QR 分解
MATLAB 通过以下语句计算稀疏矩阵 S 的完整 QR 分解
[Q,R] = qr(S)
[Q,R,E] = qr(S)
但这通常不切实际。酉矩阵 Q 通常无法拥有大量的零元素。可以使用更为实际的替代方法,该方法有时也称为“Q-less QR 分解”。
通过一个稀疏输入参量和一个输出参量
R = qr(S)
仅返回 QR 分解的上三角部分。矩阵 R 为与标准方程相关的矩阵提供乔列斯基分解:
R'*R = S'*S
但是,避免在计算 S'*S 时丢失固有的数值信息。
通过两个具有相同行数的输入参量和两个输出参量,语句
[C,R] = qr(S,B)
对 B 应用正交变换,生成 C = Q'*B,但不计算 Q。
Q-less QR 分解允许解决稀疏最小二乘问题
通过两步
[c,R] = qr(A,b); x = R\c
如果 A 是稀疏矩阵但不是方阵,MATLAB 对线性方程求解反斜杠运算符使用这些步长。
x = A\b
您也可以自己进行分解,并检查 R 是否发生秩亏情况。
也可以通过不同的右端 b 对一个序列的最小二乘线性系统求解,计算 R = qr(A) 时该右端不必为已知。该方法使用以下代码对“半标准方程”R'*R*x = A'*b求解
x = R\(R'\(A'*b))
然后应用一步迭代细化以减少舍入误差:
r = b - A*x; e = R\(R'\(A'*r)); x = x + e
不完全分解
ilu 和 ichol 函数提供近似不完全分解,它们可用作稀疏迭代方法的预条件子。
ilu 函数生成三个不完全的下-上 (ILU) 分解:零填充 ILU (ILU(0))、Crout 版本的 ILU (ILUC(tau)),以及具有阈值调降和主元的 ILU (ILUTP(tau))。ILU(0) 从不选主元,并且生成因子仅在输入矩阵具有非零元素的位置包含非零元素。但是,ILUC(tau) 和 ILUTP(tau) 通过用户定义的调降容差 tau 执行基于阈值的调降。
例如:
A = gallery('neumann',1600) + speye(1600);
nnz(A)ans =
7840nnz(lu(A))
ans =
126478显示 A 包含 7840 个非零元素,其完全 LU 分解包含 126478 个非零元素。另一方面,以下代码显示不同的 ILU 输出:
[L,U] = ilu(A); nnz(L)+nnz(U)-size(A,1)
ans =
7840norm(A-(L*U).*spones(A),'fro')./norm(A,'fro')
ans = 4.8874e-17
opts.type = 'ilutp';
opts.droptol = 1e-4;
[L,U,P] = ilu(A, opts);
nnz(L)+nnz(U)-size(A,1)ans =
31147norm(P*A - L*U,'fro')./norm(A,'fro')
ans = 9.9224e-05
opts.type = 'crout';
[L,U,P] = ilu(A, opts);
nnz(L)+nnz(U)-size(A,1)ans =
31083norm(P*A-L*U,'fro')./norm(A,'fro')
ans = 9.7344e-05
这些计算显示零填充因子包含 7840 个非零元素,ILUTP(1e-4) 因子包含 31147 个非零元素,ILUC(1e-4) 因子包含 31083 个非零元素。另外,零填充因子积的相对误差在 A 的模式中实质上为零。最后,通过阈值调降生成的分解中的相对误差类似于调降容差,虽然不能保证一定会发生此情况。请参阅 ilu 参考页以了解更多选项和详细信息。
ichol 函数提供对称正定稀疏矩阵的零填充不完全乔列斯基分解 (IC(0)) 以及基于阈值的调降不完全乔列斯基分解 (ICT(tau))。这些分解是上述不完全 LU 分解的模拟,具有许多相同特点。例如:
A = delsq(numgrid('S',200));
nnz(A)ans =
195228nnz(chol(A,'lower'))ans =
7762589A 包含 195228 个非零元素,其没有重新排序的完全乔列斯基分解包含 7762589 个非零元素。相比之下:L = ichol(A); nnz(L)
ans =
117216norm(A-(L*L').*spones(A),'fro')./norm(A,'fro')
ans = 3.5805e-17
opts.type = 'ict';
opts.droptol = 1e-4;
L = ichol(A,opts);
nnz(L)ans =
1166754norm(A-L*L','fro')./norm(A,'fro')
ans = 2.3997e-04
IC(0) 仅在 A 的下三角模式以及 A 的匹配因子积模式中拥有非零模式。另外,ICT(1e-4) 因子远远比完全乔列斯基分解稀疏,并且 A 与 L*L' 之间的相对误差类似于调降容差。值得注意的是,与 chol 提供的因子不同,ichol 提供的默认因子是下三角。有关详细信息,请参阅 ichol 参考页。
特征值和奇异值
可以使用两个函数计算一些指定的特征值或奇异值。svds 基于 eigs。
这些函数最常用于稀疏矩阵,但它们可以用于满矩阵,甚至是 MATLAB 代码中定义的线性运算函数。
语句
[V,lambda] = eigs(A,k,sigma)
查找矩阵 A 最靠近“shift”sigma 的 k 特征值及相应的特征向量。如果忽略 sigma,会找到模最大的特征值。如果 sigma 为零,会找到模最小的特征值。可以包含第二个矩阵 B 以避免广义特征值问题:Aυ = λBυ。
语句
[U,S,V] = svds(A,k)
查找 A 的 k 个最大奇异值,而
[U,S,V] = svds(A,k,'smallest')
查找 k 个最小奇异值。
eigs 和 svds 中使用的数值方法在 [6] 中进行了介绍。
稀疏矩阵的最小特征值
此示例说明如何求稀疏矩阵的最小特征值和特征向量。
在 L 形二维域中的 65×65 网格中设置五点拉普拉斯差分算子。
L = numgrid('L',65);
A = delsq(L);确定非零元素的阶数和数量。
size(A)
ans = 1×2
2945 2945
nnz(A)
ans = 14473
A 是阶数为 2945 且包含 14,473 个非零元素的矩阵。
计算最小特征值和特征向量。
[v,d] = eigs(A,1,'smallestabs');在相应的网格点上分布特征向量的分量,并生成结果的等高线图。
L(L>0) = full(v(L(L>0)));
x = -1:1/32:1;
contour(x,x,L,15)
axis square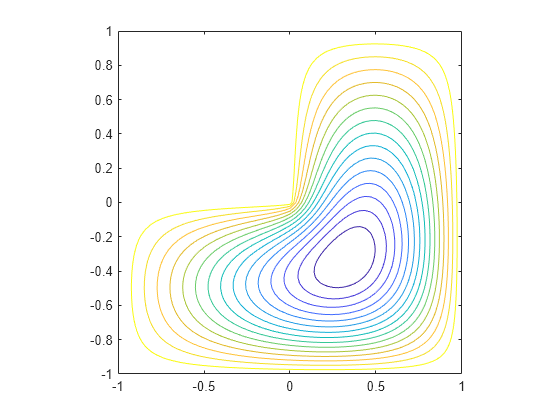
参考
[1] Amestoy, P. R., T. A. Davis, and I. S. Duff, “An Approximate Minimum Degree Ordering Algorithm,” SIAM Journal on Matrix Analysis and Applications, Vol. 17, No. 4, Oct. 1996, pp. 886-905.
[2] Barrett, R., M. Berry, T. F. Chan, et al., Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods, SIAM, Philadelphia, 1994.
[3] Davis, T.A., Gilbert, J. R., Larimore, S.I., Ng, E., Peyton, B., “A Column Approximate Minimum Degree Ordering Algorithm,” Proc. SIAM Conference on Applied Linear Algebra, Oct. 1997, p. 29.
[4] Gilbert, John R., Cleve Moler, and Robert Schreiber, “Sparse Matrices in MATLAB: Design and Implementation,” SIAM J. Matrix Anal. Appl., Vol. 13, No. 1, January 1992, pp. 333-356.
[5] Larimore, S. I., An Approximate Minimum Degree Column Ordering Algorithm, MS Thesis, Dept. of Computer and Information Science and Engineering, University of Florida, Gainesville, FL, 1998.
[6] Saad, Yousef, Iterative Methods for Sparse Linear Equations. PWS Publishing Company, 1996.
[7] Karypis, George and Vipin Kumar. "A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs." SIAM Journal on Scientific Computing. Vol. 20, Number 1, 1999, pp. 359–392.