svds
奇异值和向量的子集
语法
说明
s = svds(A,k,sigma,Name,Value)svds(A,k,sigma,'Tolerance',1e-3) 将调整算法的收敛容差。
示例
矩阵 A = delsq(numgrid('C',15)) 是一个对称正定矩阵,奇异值合理分布在区间 (0 8) 中。计算六个最大的奇异值。
A = delsq(numgrid('C',15));
s = svds(A)s = 6×1
7.8666
7.7324
7.6531
7.5213
7.4480
7.3517
指定第二个输入,以计算特定数量的最大奇异值。
s = svds(A,3)
s = 3×1
7.8666
7.7324
7.6531
矩阵 A = delsq(numgrid('C',15)) 是一个对称正定矩阵,奇异值合理分布在区间 (0 8) 中。计算五个最小的奇异值。
A = delsq(numgrid('C',15)); s = svds(A,5,'smallest')
s = 5×1
0.5520
0.4787
0.3469
0.2676
0.1334
创建一个 100×100 的稀疏纽曼矩阵。
C = gallery('neumann',100);计算十个最小的奇异值。
ss = svds(C,10,'smallest')ss = 10×1
0.9828
0.9049
0.5625
0.5625
0.4541
0.4506
0.2256
0.1139
0.1139
0
计算十个最小的非零奇异值。由于该矩阵有一个奇异值等于零,因此 'smallestnz' 选项将忽略它。
snz = svds(C,10,'smallestnz')snz = 10×1
0.9828
0.9828
0.9049
0.5625
0.5625
0.4541
0.4506
0.2256
0.1139
0.1139
创建两个矩阵,表示稀疏矩阵右上角和左下角的非零块。
n = 500; B = rand(500); C = rand(500);
将 Afun 保存到您的当前目录中,以便其可用于 svds。
function y = Afun(x,tflag,B,C,n) if strcmp(tflag,'notransp') y = [B*x(n+1:end); C*x(1:n)]; else y = [C'*x(n+1:end); B'*x(1:n)]; end
函数 Afun 使用 B 和 C 来计算 A*x 或 A'*x(具体取决于指定的标志),而不用真正建立整个稀疏矩阵 A = [zeros(n) B; C zeros(n)]。这种方法可以在计算 A*x 和 A'*x 时充分利用矩阵的稀疏模式来节省内存。
使用 Afun 计算 A 的 10 个最大的奇异值。将 B、C 和 n 作为额外输入传递给 Afun。
s = svds(@(x,tflag) Afun(x,tflag,B,C,n),[1000 1000],10)
s = 250.3248 249.9914 12.7627 12.7232 12.6988 12.6608 12.6166 12.5643 12.5419 12.4512
直接计算 A 的 10 个最大的奇异值以比较结果。
A = [zeros(n) B; C zeros(n)]; s = svds(A,10)
s = 250.3248 249.9914 12.7627 12.7232 12.6988 12.6608 12.6166 12.5643 12.5419 12.4512
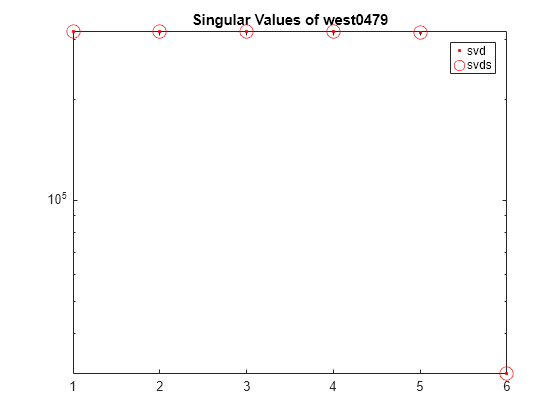
west0479 是一个 479×479 的实数值稀疏矩阵。该矩阵有几个较大的奇异值和许多较小的奇异值。
加载 west0479 并将其存储为 A。
load west0479
A = west0479;计算 A 的奇异值分解,返回六个最大的奇异值和对应的奇异向量。指定第四个输出参量,以检查奇异值的收敛。
[U,S,V,cflag] = svds(A); cflag
cflag = 0
cflag 表示所有奇异值已收敛。奇异值位于输出矩阵 S 的对角线上。
s = diag(S)
s = 6×1
105 ×
3.1895
3.1725
3.1695
3.1685
3.1669
0.3038
通过计算 A 的完整奇异值分解来检查结果。将 A 转换成满矩阵并使用 svd。
[U1,S1,V1] = svd(full(A));
使用对数刻度绘制由 svd 和 svds 计算的 A 的六个最大奇异值。
s2 = diag(S1); semilogy(s2(1:6),'r.') hold on semilogy(s,'ro','MarkerSize',10) title('Singular Values of west0479') legend('svd','svds')
创建一个稀疏对角矩阵并计算六个最大的奇异值。
A = diag(sparse([1e4*ones(1, 8) 1e4:-1:1])); s = svds(A)
Warning: Only 2 of the 6 requested singular values converged. Singular values that did not converge are NaN.
s = 6×1
104 ×
1.0000
0.9999
NaN
NaN
NaN
NaN
由于已执行完最大迭代次数,但仍然无法满足容差要求,所以 svds 算法生成一条警告消息。
解决收敛问题的最有效方法是使用更大的 'SubspaceDimension' 值,以增加计算中使用的克雷洛夫子空间的最大大小。此操作可通过传入值为 60 的名称-值对组 'SubspaceDimension' 来完成。
s = svds(A,6,'largest','SubspaceDimension',60)
s = 6×1
104 ×
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
计算接近奇异矩阵的 10 个最小的奇异值。
rng default format shortg B = spdiags([repelem([1; 1e-7], [198, 2]) ones(200, 1)], [0 1], 200, 200); s1 = svds(B,10,'smallest')
Warning: Large residual norm detected. This is likely due to bad condition of the input matrix (condition number 1.0008e+16).
s1 = 10×1
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
0.25927
7.0888e-16
警告表明 svds 无法计算正确的奇异值。svds 失败的原因在于最小奇异值和次小奇异值之间存在间隔。svds(...,'smallest') 需要求 B 的逆矩阵,这会产生较大的数值误差。
要进行比较,请使用 svd 计算精确的奇异值。
s = svd(full(B)); s = s(end-9:end)
s = 10×1
0.14196
0.12621
0.11045
0.094686
0.078914
0.063137
0.047356
0.031572
0.015787
7.0888e-16
要使用 svds 再现此计算,请执行 B 的 QR 分解。三角矩阵 R 的奇异值与 B 的相同。
[Q,R,p] = qr(B,0);
绘制 R 的每行的范数。
rownormR = sqrt(diag(R*R')); semilogy(rownormR) hold on; semilogy(size(R, 1), rownormR(end), 'ro')
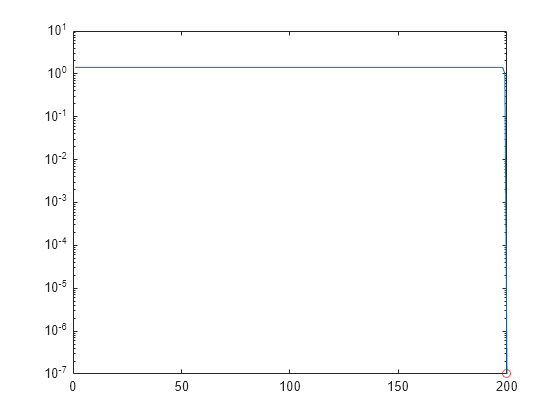
R 中的最后一项接近于零,这导致解不稳定。
通过将 R 的最后一行精确设置为零,可以防止此项破坏解的正确部分。
R(end,:) = 0;
使用 svds 求出 R 的 10 个最小的奇异值。结果与通过 svd 获得的值类似。
sr = svds(R,10,'smallest')sr = 10×1
0.14196
0.12621
0.11045
0.094686
0.078914
0.063137
0.047356
0.031572
0.015787
0
要使用此方法计算 B 的奇异向量,请使用 Q 和置换向量 p 转换左奇异向量和右奇异向量。
[U,S,V] = svds(R,20,'s');
U = Q*U;
V(p,:) = V;输入参数
名称-值参数
输出参量
提示
如果您事先不知道用
svds指定什么秩但知道 SVD 的逼近应满足什么容差,则svdsketch很有用。svds使用专用的随机数流生成默认起始向量,以确保在不同运行之间的可再现性。调用svds之前使用rng设置随机数生成器状态不会影响输出。要求出小型稠密矩阵的几个奇异值,使用
svds并不是最有效的方式。对于这些问题,使用svd(full(A))可能会更快。例如,求 500×500 矩阵中的三个奇异值相对容易,使用svd即可轻松完成。对于给定矩阵,如果
svds无法收敛,可以通过增大'SubspaceDimension'值来增加克雷洛夫子空间的大小。作为备用方案,调整最大迭代次数 ('MaxIterations') 和收敛容差 ('Tolerance') 也有助于改善收敛行为。增大
k有时可以提高性能,特别是当矩阵包含重复的奇异值时。
参考
[1] Baglama, J. and L. Reichel, “Augmented Implicitly Restarted Lanczos Bidiagonalization Methods.” SIAM Journal on Scientific Computing. Vol. 27, 2005, pp. 19–42.
[2] Larsen, R. M. “Lanczos Bidiagonalization with partial reorthogonalization.” Dept. of Computer Science, Aarhus University. DAIMI PB-357, 1998.