eigs
特征值和特征向量的子集
语法
说明
d = eigs(A,k,sigma,Name,Value)eigs(A,k,sigma,'Tolerance',1e-3) 将调整算法的收敛容差。
示例
矩阵 A = delsq(numgrid('C',15)) 是一个对称正定矩阵,特征值合理分布在区间 (0 8) 中。计算模最大的六个特征值。
A = delsq(numgrid('C',15));
d = eigs(A)d = 6×1
7.8666
7.7324
7.6531
7.5213
7.4480
7.3517
指定第二个输入,以计算特定数量的最大特征值。
d = eigs(A,3)
d = 3×1
7.8666
7.7324
7.6531
矩阵 A = delsq(numgrid('C',15)) 是一个对称正定矩阵,特征值合理分布在区间 (0 8) 中。计算五个最小的特征值。
A = delsq(numgrid('C',15)); d = eigs(A,5,'smallestabs')
d = 5×1
0.1334
0.2676
0.3469
0.4787
0.5520
创建一个随机的 1500×1500 稀疏矩阵,非零元素的密度接近 25%。
n = 1500; A = sprand(n,n,0.25);
求矩阵的 LU 分解,将返回满足 A(p,:) = L*U 的置换向量 p。
[L,U,p] = lu(A,'vector');创建函数句柄 Afun,它接受向量输入 x 并使用 LU 分解结果实际返回 A\x。
Afun = @(x) U\(L\(x(p)));
使用带有函数句柄 Afun 的 eigs 计算六个模最小的特征值。第二个输入为 A 的大小。
d = eigs(Afun,1500,6,'smallestabs')d = 6×1 complex
0.1423 + 0.0000i
0.4859 + 0.0000i
-0.3323 - 0.3881i
-0.3323 + 0.3881i
0.1019 - 0.5381i
0.1019 + 0.5381i
west0479 是一个带有实特征值和成对复共轭特征值的 479×479 实数值稀疏矩阵。
加载 west0479 矩阵,然后使用 eig 计算并绘制所有特征值。由于特征值为复数,plot 将自动使用实部作为 x 轴坐标,使用虚部作为 y 轴坐标。
load west0479 A = west0479; d = eig(full(A)); plot(d,'+')
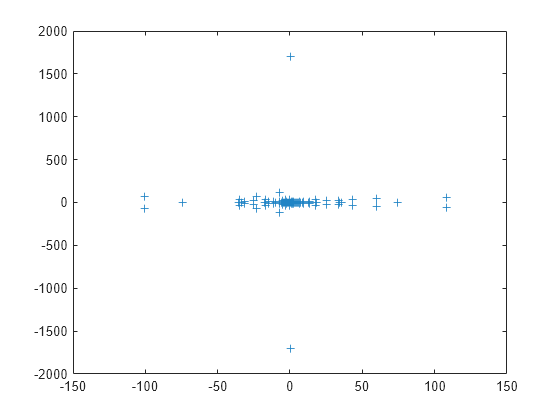
特征值沿实线(x 轴)形成集群,距离原点特别近。
eigs 有多个适用于 sigma 的选项,可以挑选不同类型的最大或最小特征值。为 sigma 的每个可用选项计算并绘制一些特征值。
figure plot(d, '+') hold on la = eigs(A,6,'largestabs'); plot(la,'ro') sa = eigs(A,6,'smallestabs'); plot(sa,'go') hold off legend('All eigenvalues','Largest magnitude','Smallest magnitude') xlabel('Real axis') ylabel('Imaginary axis')

figure plot(d, '+') hold on ber = eigs(A,4,'bothendsreal'); plot(ber,'r^') bei = eigs(A,4,'bothendsimag'); plot(bei,'g^') hold off legend('All eigenvalues','Both ends real','Both ends imaginary') xlabel('Real axis') ylabel('Imaginary axis')

figure plot(d, '+') hold on lr = eigs(A,3,'largestreal'); plot(lr,'ro') sr = eigs(A,3,'smallestreal'); plot(sr,'go') li = eigs(A,3,'largestimag','SubspaceDimension',45); plot(li,'m^') si = eigs(A,3,'smallestimag','SubspaceDimension',45); plot(si,'c^') hold off legend('All eigenvalues','Largest real','Smallest real','Largest imaginary','Smallest imaginary') xlabel('Real axis') ylabel('Imaginary axis')

创建一个对称正定稀疏矩阵。
A = delsq(numgrid('C', 150));使用 'smallestreal' 计算六个最小的实数特征值,它采用了使用 A 的克雷洛夫方法。
tic
d = eigs(A, 6, 'smallestreal')d = 6×1
0.0013
0.0025
0.0033
0.0045
0.0052
0.0063
toc
Elapsed time is 0.897648 seconds.
使用 'smallestabs' 计算同样的特征值,它采用了使用 A 的倒数的克雷洛夫方法。
tic
dsm = eigs(A, 6, 'smallestabs')dsm = 6×1
0.0013
0.0025
0.0033
0.0045
0.0052
0.0063
toc
Elapsed time is 0.190163 seconds.
特征值聚集在零附近。'smallestreal' 计算很难使用 A 进行收敛,因为特征值之间的差距非常小。相反,'smallestabs' 选项使用 A 的倒数,也就是 A 的特征值的倒数,它们的差距大得多,所以更容易计算。这种性能改进以分解 A 为代价,使用 'smallestreal' 则不需要进行分解。
计算几乎等于特征值的 sigma 数值附近的特征值。
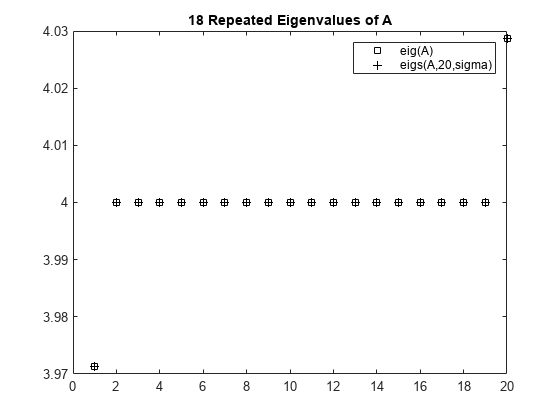
矩阵 A = delsq(numgrid('C',30)) 是一个大小为 632 的对称正定矩阵,特征值合理分布在区间 (0 8) 中,但是在 4.0 处有 18 个重复的特征值。要计算 4.0 附近的一些特征值,尝试函数调用 eigs(A,20,4.0) 是合理的。然而,此调用计算 A - 4.0*I 的逆矩阵的最大特征值,其中 I 是单位矩阵。由于 4.0 是 A 的特征值,此矩阵为奇异矩阵,因此没有逆矩阵。eigs 失败并生成错误消息。sigma 的数值不能精确等于特征值。必须使用接近但不等于 4.0 的 sigma 值来求这些特征值。
使用 eig 计算所有特征值,使用 eigs 计算 20 个最接近 4 - 1e-6 的特征值,然后比较结果。绘制按照每一种方法计算的特征值。
A = delsq(numgrid('C',30));
sigma = 4 - 1e-6;
d = eig(A);
D = sort(eigs(A,20,sigma));plot(d(307:326),'ks') hold on plot(D,'k+') hold off legend('eig(A)','eigs(A,20,sigma)') title('18 Repeated Eigenvalues of A')
创建稀疏随机矩阵 A 和 B,它们都具有低密度非零元素。
B = sprandn(1e3,1e3,0.001) + speye(1e3); B = B'*B; A = sprandn(1e3,1e3,0.005); A = A+A';
求矩阵 B 的乔列斯基分解,使用三个输出以返回置换向量 s 并测试值 p。
[R,p,s] = chol(B,'vector');
pp = 0
由于 p 为零,因此 B 是满足 B(s,s) = R'*R 的对称正定矩阵。
计算涉及 A 和 R 的广义特征值问题的六个模最大的特征值和特征向量。由于 R 是 B 的乔列斯基因子,请将 'IsCholesky' 指定为 true。此外,由于 B(s,s) = R'*R,因此 R = chol(B(s,s)),所以应使用置换向量 s 作为 'CholeskyPermutation' 的值。
[V,D,flag] = eigs(A,R,6,'largestabs','IsCholesky',true,'CholeskyPermutation',s); flag
flag = 0
由于 flag 为零,所有特征值均已收敛。
输入参数
名称-值参数
输出参量
提示
eigs使用专用的随机数流生成默认起始向量,以确保在不同运行之间的可再现性。调用eigs之前使用rng设置随机数生成器状态不会影响输出。要求出小型稠密矩阵的几个特征值,使用
eigs并不是最有效的方式。对于这些问题,使用eig(full(A))求解可能会更快。例如,求 500×500 矩阵的三个特征值相对容易,使用eig即可轻松完成。对于某个给定矩阵,如果
eigs无法收敛,可以通过增大'SubspaceDimension'值来增加兰佐斯基向量的数量。作为备用方案,调整最大迭代次数'MaxIterations'和收敛容差'Tolerance'也有助于改善收敛行为。
参考
[1] Stewart, G.W. "A Krylov-Schur Algorithm for Large Eigenproblems." SIAM Journal of Matrix Analysis and Applications. Vol. 23, Issue 3, 2001, pp. 601–614.
[2] Lehoucq, R.B., D.C. Sorenson, and C. Yang. ARPACK Users' Guide. Philadelphia, PA: SIAM, 1998.