pix2pixHDGlobalGenerator
Create pix2pixHD global generator network
Description
net = pix2pixHDGlobalGenerator(inputSize)inputSize. For
more information about the network architecture, see pix2pixHD Generator Network.
This function requires Deep Learning Toolbox™.
net = pix2pixHDGlobalGenerator(inputSize,Name=Value)
Examples
Input Arguments
Name-Value Arguments
Output Arguments
More About
A pix2pixHD generator network consists of an encoder module followed by a decoder module. The default network follows the architecture proposed by Wang et. al. [1].
The encoder module downsamples the input by a factor of
2^NumDownsamplingBlocks. The encoder module consists of an initial
block of layers, NumDownsamplingBlocks downsampling blocks, and
NumResidualBlocks residual blocks. The decoder module upsamples the
input by a factor of 2^NumDownsamplingBlocks. The decoder module
consists of NumDownsamplingBlocks upsampling blocks and a final block.
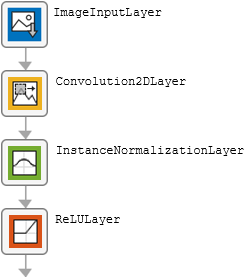
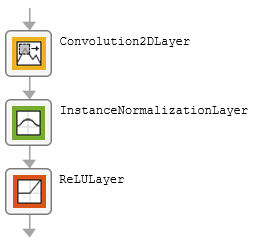
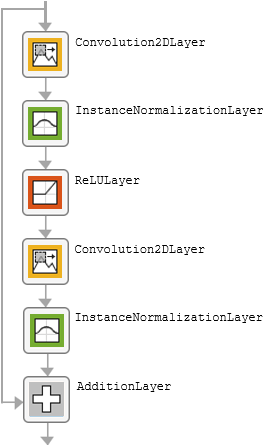
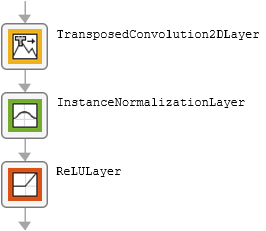
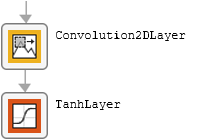
The table describes the blocks of layers that comprise the encoder and decoder modules.
| Block Type | Layers | Diagram of Default Block |
|---|---|---|
| Initial block |
|
|
| Downsampling block |
|
|
| Residual block |
|
|
| Upsampling block |
|
|
| Final block |
|
|
Tips
You can create the discriminator network for pix2pixHD by using the
patchGANDiscriminatorfunction.Train the pix2pixHD GAN network using a custom training loop.
References
[1]
Version History
Introduced in R2021a
See Also
addPix2PixHDLocalEnhancer | encoderDecoderNetwork | blockedNetwork | cycleGANGenerator | unitGenerator
Topics
- Generate Image from Segmentation Map Using Deep Learning (Computer Vision Toolbox)
- Get Started with GANs for Image-to-Image Translation
- Create Modular Neural Networks
- List of Deep Learning Layers (Deep Learning Toolbox)