unitGenerator
Create unsupervised image-to-image translation (UNIT) generator network
Description
net = unitGenerator(inputSizeSource)net, for input of size
inputSizeSource. For more information about the network architecture,
see UNIT Generator Network. The network has two inputs and
four outputs:
The two network inputs are images in the source and target domains. By default, the target image size is same as source image size. You can change the number of channels in the target image by specifying the
NumTargetInputChannelsname-value argument.Two of the network outputs are self-reconstructed outputs, in other words, source-to-source and target-to-target translated images. The other two network outputs are the source-to-target and target-to-source translated images.
net = unitGenerator(inputSizeSource,Name=Value)
Examples
Specify the network input size for RGB images of size 128-by-128.
inputSize = [128 128 3];
Create a UNIT generator that generates RGB images of the input size.
net = unitGenerator(inputSize);
Display the network.
analyzeNetwork(net)
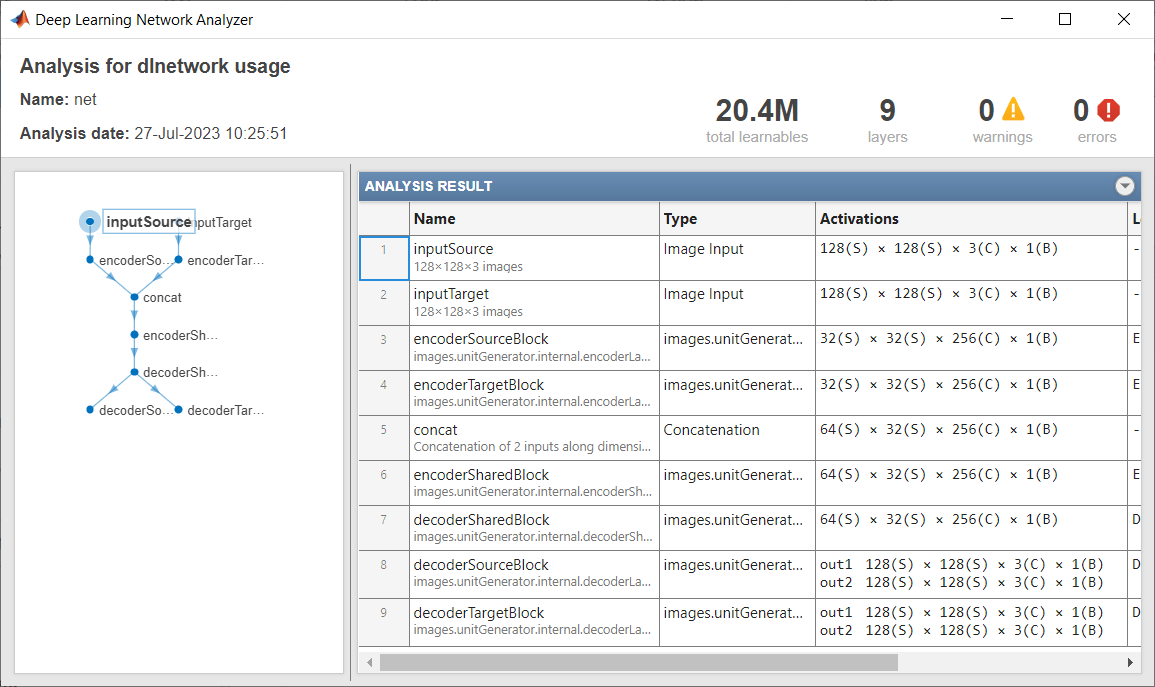
Specify the network input size for RGB images of size 128-by-128 pixels.
inputSize = [128 128 3];
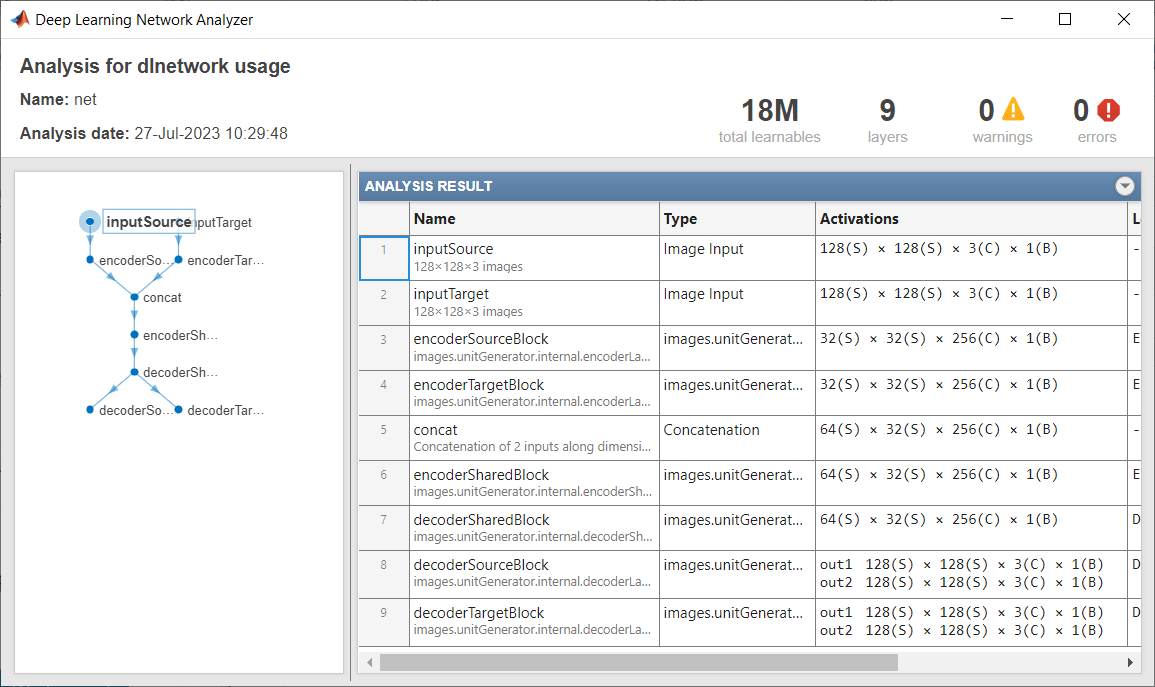
Create a UNIT generator with five residual blocks, three of which are shared between the encoder and decoder modules.
net = unitGenerator(inputSize,NumResidualBlocks=5, ...
NumSharedBlocks=3);Display the network.
analyzeNetwork(net)
Input Arguments
Name-Value Arguments
Output Arguments
More About
A UNIT generator network consists of three subnetworks in an encoder module followed by three subnetworks in a decoder module. The default network follows the architecture proposed by Liu, Breuel, and Kautz [1].
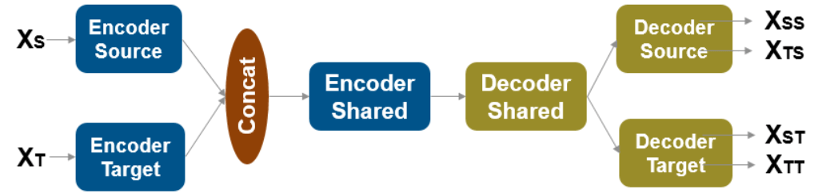
The encoder module downsamples the input by a factor of
2^NumDownsamplingBlocks. The encoder module consists of three subnetworks.
The source encoder subnetwork, called 'encoderSourceBlock', has an initial block of layers that accepts data in the source domain, XS. The subnetwork then has
NumDownsamplingBlocksdownsampling blocks that downsample the data andNumResidualBlocks–NumSharedBlocksresidual blocks.The target encoder subnetwork, called 'encoderTargetBlock', has an initial block of layers that accepts data in the target domain, XS. The subnetwork then has
NumDownsamplingBlocksdownsampling blocks that downsample the data, andNumResidualBlocks–NumSharedBlocksresidual blocks.The output of the source encoder and target encoder are combined by a
concatenationLayer(Deep Learning Toolbox)The shared residual encoder subnetwork, called 'encoderSharedBlock', accepts the concatenated data and has
NumSharedBlocksresidual blocks.
The decoder module consists of three subnetworks that perform a total of
NumDownsamplingBlocks upsampling operations on the data.
The shared residual decoder subnetwork, called 'decoderSharedBlock', accepts data from the encoder and has
NumSharedBlocksresidual blocks.The source decoder subnetwork, called 'decoderSourceBlock', has
NumResidualBlocks–NumSharedBlocksresidual blocks,NumDownsamplingBlocksdownsampling blocks that downsample the data, and a final block of layers that returns the output. This subnetwork returns two outputs in the source domain: XTS and XSS. The output XTS is an image translated from the target domain to the source domain. The output XSS is a self-reconstructed image from the source domain to the source domain.The target decoder subnetwork, called 'decoderTargetBlock', has
NumResidualBlocks–NumSharedBlocksresidual blocks,NumDownsamplingBlocksdownsampling blocks that downsample the data, and a final block of layers that returns the output. This subnetwork returns two outputs in the target domain: XST and XTT. The output XTS is an image translated from the source domain to the target domain. The output XTT is a self-reconstructed image from the target domain to the target domain.
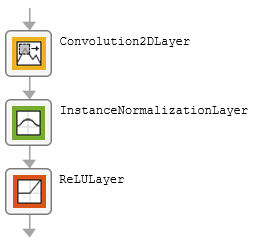
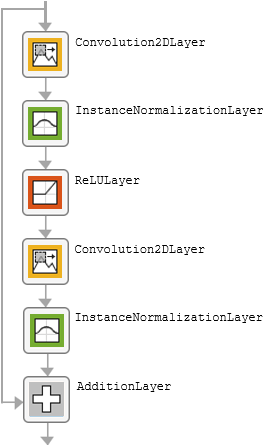
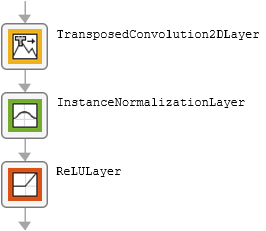
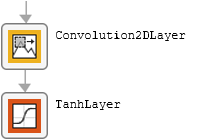
The table describes the blocks of layers that comprise the subnetworks.
| Block Type | Layers | Diagram of Default Block |
|---|---|---|
| Initial block |
|
|
| Downsampling block |
|
|
| Residual block |
|
|
| Upsampling block |
|
|
| Final block |
|
|
Tips
You can create the discriminator network for UNIT by using the
patchGANDiscriminatorfunction.Train the UNIT GAN network using a custom training loop.
To perform domain translation of source image to target image and vice versa, use the
unitPredictfunction.For shared latent feature encoding, the arguments
NumSharedBlocksandNumResidualBlocksmust be greater than 0.
References
[1]
Version History
Introduced in R2021a