pwelch
韦尔奇的功率谱密度估计
语法
说明
[___] = pwelch(___, 还为上述任一语法指定频率范围、频谱类型和跟踪模式。您可以指定这些输入参量的任意组合。freqRange,spectrumType,trace)
不带输出参量的 pwelch(___) 在当前图窗窗口中绘制韦尔奇 PSD 估计值或功率谱。
示例
获取一个输入信号的韦尔奇 PSD 估计值,该输入信号由角频率为 弧度/采样点的离散时间正弦信号和加性 白噪声组成。
创建一个角频率为 弧度/采样点并具有加性 白噪声的正弦波。重置随机数生成器以获得可重现的结果。信号的长度为 个采样。
rng("default")
n = 0:319;
x = cos(pi/4*n) + randn(size(n));使用默认汉明窗和 DFT 长度获取韦尔奇 PSD 估计值。默认段长度为 71 个采样,DFT 长度为 256 个点,产生 弧度/采样点的频率分辨率。由于信号是实数值信号,周期图为单边型并且有 256/2+1 个点。绘制韦尔奇 PSD 估计值。
pxx = pwelch(x); pwelch(x)
重复该计算。
将信号分成长度为 的若干段。此操作等效于将信号分成尽可能长的段,以获得接近但不超出 8 个叠加率为 50% 的段。
使用汉明窗对这些段进行加窗处理。
指定连续段之间的重叠率为 50%
为了计算 FFT,请使用 个点,其中 。
验证这两种方法是否给出相同的结果。
Nx = length(x); nsc = floor(Nx/4.5); nov = floor(nsc/2); nff = max(256,2^nextpow2(nsc)); pxxt = pwelch(x,hamming(nsc),nov,nff); maxerr = max(abs(abs(pxxt(:)) - abs(pxx(:))))
maxerr = 0
将信号分成 8 个等长的段,段之间的重叠率为 50%。指定与上一步相同的 FFT 长度。计算韦尔奇 PSD 估计值,并验证它是否与前两个过程的结果相同。
ns = 8; ov = 0.5; lsc = floor(Nx/(ns-(ns-1)*ov)); pxxt8 = pwelch(x,lsc,floor(ov*lsc),nff); maxerr8 = max(abs(abs(pxxt8(:)) - abs(pxx(:))))
maxerr8 = 0
获取一个输入信号的韦尔奇 PSD 估计值,该输入信号由角频率为 弧度/采样点的离散时间正弦信号和加性 白噪声组成。
创建一个角频率为 弧度/采样点并具有加性 白噪声的正弦波。重置随机数生成器以获得可重现的结果。信号有 512 个采样。
rng("default")
n = 0:511;
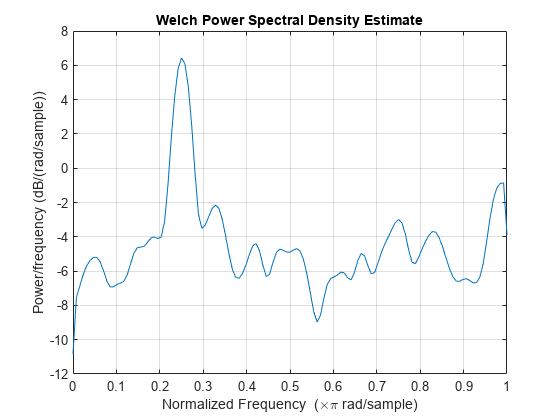
x = cos(pi/3*n) + randn(size(n));通过将信号分成长度为 132 个采样的段来获取韦尔奇 PSD 估计值。信号段乘以长度为 132 个采样的汉明窗。未指定重叠采样数,因此设置为 132/2 = 66。DFT 长度为 256 个点,产生 弧度/采样点的频率分辨率。由于信号是实数值信号,PSD 估计值为单边型并且有 256/2+1 = 129 个点。绘制 PSD 随归一化频率变化的图。
segmentLength = 132; [pxx,w] = pwelch(x,segmentLength); plot(w/pi,pow2db(pxx)) xlabel("Normalized Frequency (\times \pi rad/sample)") title("Welch Power Spectral Density Estimate")
获取一个输入信号的韦尔奇 PSD 估计值,该输入信号由角频率为 弧度/采样点的离散时间正弦信号和加性 白噪声组成。
创建一个角频率为 弧度/采样点并具有加性 白噪声的正弦波。重置随机数生成器以获得可重现的结果。信号长度为 320 个采样。
rng("default")
n = 0:319;
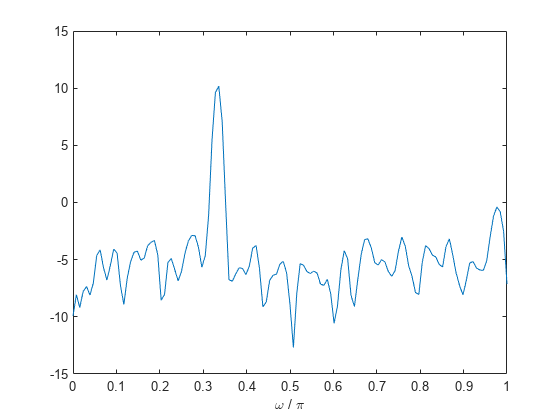
x = cos(pi/4*n) + randn(size(n));通过将信号分成长度为 100 个采样的段来获取韦尔奇 PSD 估计值。信号段乘以长度为 100 个采样的汉明窗。重叠采样数为 25。DFT 长度为 256 个点,产生 弧度/采样点的频率分辨率。由于信号是实数值信号,PSD 估计值为单边型并且有 256/2+1 个点。
segmentLength = 100; noverlap = 25; pxx = pwelch(x,segmentLength,noverlap); plot(pow2db(pxx)) xlabel("Frequency Samples") title("Welch Power Spectral Density Estimate")
获取一个输入信号的韦尔奇 PSD 估计值,该输入信号由角频率为 弧度/采样点的离散时间正弦信号和加性 白噪声组成。
创建一个角频率为 弧度/采样点并具有加性 白噪声的正弦波。重置随机数生成器以获得可重现的结果。信号长度为 320 个采样。
rng("default")
n = 0:319;
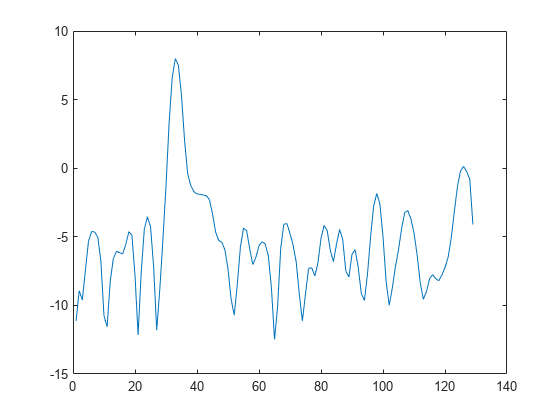
x = cos(pi/4*n) + randn(size(n));通过将信号分成长度为 100 个采样的段来获取韦尔奇 PSD 估计值。使用默认重叠率 50%。指定 DFT 长度为 640 个点,以使 弧度/采样点的频率对应于一个 DFT bin (bin 81)。由于信号是实数值信号,PSD 估计值为单边型并且有 640/2+1 个点。
segmentLength = 100; nfft = 640; pxx = pwelch(x,segmentLength,[],nfft); plot(pow2db(pxx)) xlabel("Frequency Points") title("Welch Power Spectral Density Estimate")
创建一个信号,该信号包含在加性 N(0,1) 白噪声中的一个 100 Hz 正弦波。重置随机数生成器以获得可重现的结果。采样率为 1 kHz,信号持续时间为 5 秒。
rng("default")
Fs = 1000;
t = 0:1/Fs:5-1/Fs;
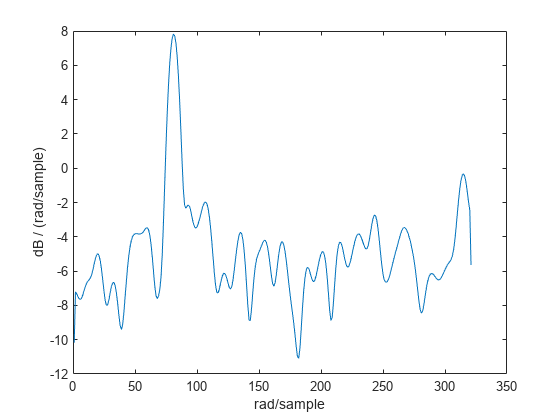
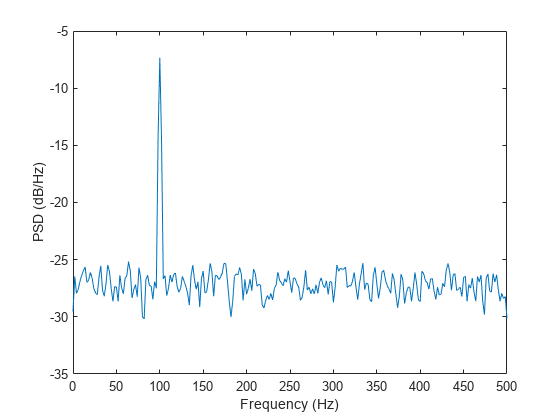
x = cos(2*pi*100*t) + randn(size(t));获取上述信号的韦尔奇交叠分段平均法 PSD 估计值。使用一个长度为 500 个采样的段,其中有 300 个重叠采样。使用 500 个 DFT 点,以使 100 Hz 恰好位于一个 DFT bin 上。输入采样率以输出以 Hz 为单位的频率向量。绘制结果。
[pxx,f] = pwelch(x,500,300,500,Fs); plot(f,pow2db(pxx)) xlabel("Frequency (Hz)") ylabel("PSD (dB/Hz)")
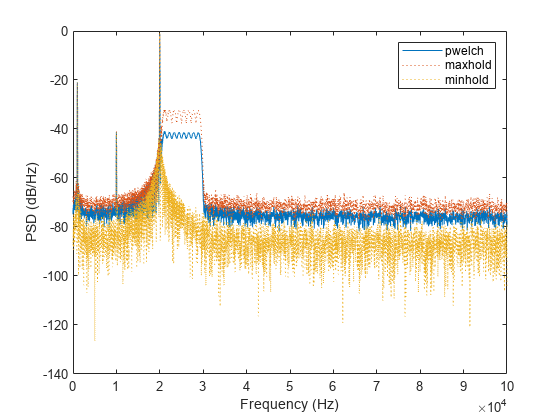
创建一个信号,该信号由三个含噪正弦波和一个以 200 kHz 进行 0.1 秒采样的啁啾组成。这些正弦波的频率分别为 1 kHz、10 kHz 和 20 kHz。这些正弦波具有不同振幅和噪声电平。无噪声啁啾的频率从 20 kHz 开始,并在采样期间线性增大到 30 kHz。
rng("default")
Fs = 200e3;
Fc = [1 10 20]'*1e3;
Ns = 0.1*Fs;
t = (0:Ns-1)/Fs;
x = [1 1/10 10]*sin(2*pi*Fc*t) + [1/200 1/2000 1/20]*randn(3,Ns);
x = x + chirp(t,20e3,t(end),30e3);计算信号的韦尔奇 PSD 估计值以及最大值保持和最小值保持频谱。绘制结果。
[pxx,f] = pwelch(x,[],[],[],Fs); pmax = pwelch(x,[],[],[],Fs,"maxhold"); pmin = pwelch(x,[],[],[],Fs,"minhold"); plot(f,pow2db(pxx)) hold on plot(f,pow2db([pmax pmin]),":") hold off xlabel("Frequency (Hz)") ylabel("PSD (dB/Hz)") legend(["pwelch" "maxhold" "minhold"])
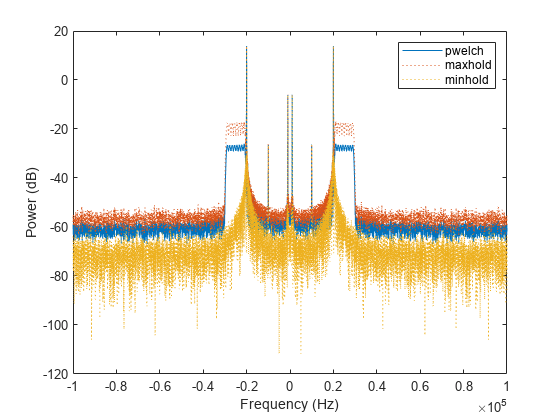
重复此过程,这次计算中心化功率谱估计值。
[pxx,f] = pwelch(x,[],[],[],Fs,"centered","power"); pmax = pwelch(x,[],[],[],Fs,"maxhold","centered","power"); pmin = pwelch(x,[],[],[],Fs,"minhold","centered","power"); plot(f,pow2db(pxx)) hold on plot(f,pow2db([pmax pmin]),":") hold off xlabel("Frequency (Hz)") ylabel("Power (dB)") legend(["pwelch" "maxhold" "minhold"])
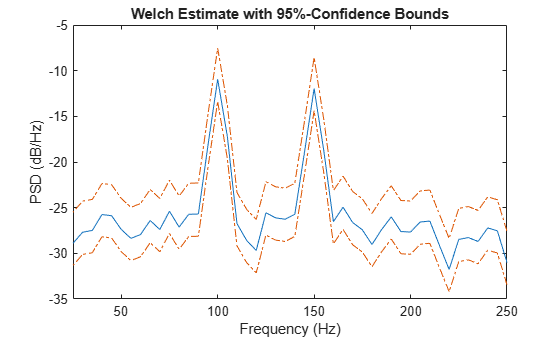
此示例说明置信边界与韦尔奇交叠分段平均法 (WOSA) PSD 估计值的用法。在韦尔奇估计值中,如果某个频率的置信边界下限超出周围 PSD 估计值的置信边界上限,则清楚地表明时间序列中存在显著的振荡,虽然这不是统计意义的必要条件。
创建一个信号,该信号包含在加性白 N(0,1) 噪声中叠加的 100 Hz 和 150 Hz 正弦波。这两个正弦波的振幅为 1。采样率为 1 kHz。重置随机数生成器以获得可重现的结果。
rng("default")
Fs = 1000;
t = 0:1/Fs:1-1/Fs;
x = cos(2*pi*100*t) + sin(2*pi*150*t) + randn(size(t));获取具有 95% 置信边界的 WOSA 估计值。将段长度设置为 200 个采样,并使段重叠 50%(100 个采样)。
L = 200; win = hamming(L); nOverlap = 100; [pxx,f,pxxc] = pwelch(x,win,nOverlap,200,Fs,ConfidenceLevel=0.95);
绘制 WOSA PSD 估计值以及置信区间,并放大在 100 Hz 和 150 Hz 附近的感兴趣频率区域。紧靠 100 Hz 和 150 Hz 的置信边界下限显著高于 100 Hz 和 150 Hz 以外的置信边界上限。
plot(f,pow2db(pxx)) hold on plot(f,pow2db(pxxc),"-.",Color=[0.866 0.329 0]) hold off xlim([25 250]) xlabel("Frequency (Hz)") ylabel("PSD (dB/Hz)") title("Welch Estimate with 95%-Confidence Bounds")
创建一个信号,该信号包含在加性 白噪声中的一个 100 Hz 正弦波。重置随机数生成器以获得可重现的结果。采样率为 1 kHz,信号持续时间为 5 秒。
rng("default")
Fs = 1000;
t = 0:1/Fs:5-1/Fs;
noisevar = 1/4;
x = cos(2*pi*100*t) + sqrt(noisevar)*randn(size(t));使用韦尔奇方法获取以 DC 为中心的功率谱。使用 500 个采样(具有 300 个重叠采样)的段长度和 500 个点的 DFT 长度。
[pxx,f] = pwelch(x,500,300,500,Fs,"centered","power");
绘制结果。在 -100 Hz 和 100 Hz 处的功率接近于 1/4 的预期功率,这是振幅为 1 的实数值正弦波的功率。与 1/4 的偏差是加性噪声造成的。
plot(f,pow2db(pxx)) xlabel("Frequency (Hz)") ylabel("Magnitude (dB)") grid
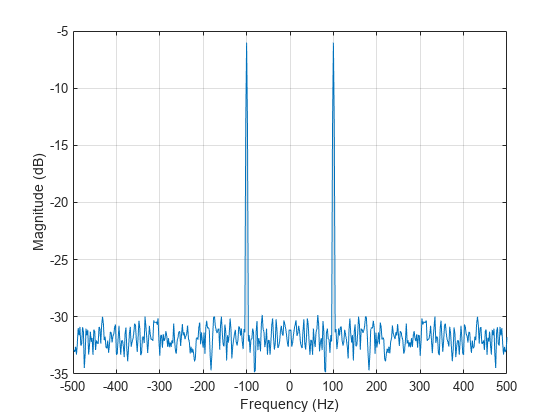
生成一个多通道信号的 1024 个采样,该信号包含在加性 高斯白噪声中叠加的三个正弦波。这些正弦波的频率为 、 和 弧度/采样点。使用韦尔奇方法估计信号的 PSD 并对其绘图。
N = 1024;
n = 0:N-1;
w = pi./[2;3;4];
rng("default")
x = cos(w*n)' + randn(length(n),3);
pwelch(x)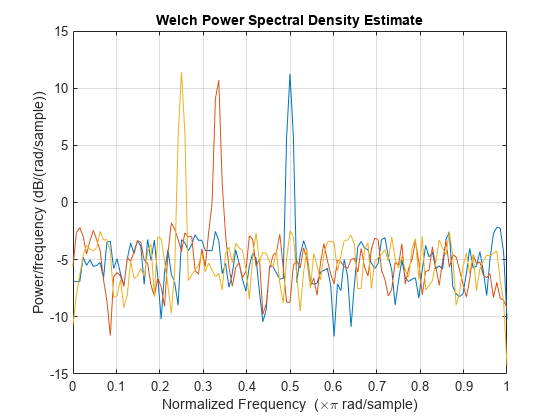
自 R2026a 起
在指定的目标坐标区和面板容器中绘制四个信号的韦尔奇功率谱密度 (PSD) 估计值和韦尔奇功率谱。
创建四个振荡信号,采样率为 10 kHz,持续三秒。
Fs = 10e3;
t = 0:1/Fs:3;
x1 = sinc(Fs/2.5*(t-mean(t)));
x2 = sum(cos(2*pi*600*[1 3 5 7]'.*t),1) + randn(size(t))/1e4;
x3 = exp(1j*pi*sin(4*t)*Fs/10);
x4 = chirp(t,Fs/10,t(end),Fs/2.5,"quadratic");在目标坐标区中绘制韦尔奇 PSD 估计值和功率谱
在新图窗窗口的西南角和东北角创建两个坐标区。
fig = figure; ax1 = axes(fig,Position=[0.09 0.1 0.52 0.45]); ax2 = axes(fig,Position=[0.55 0.7 0.42 0.25]);
分别在图窗的西南和东北坐标区中绘制信号 x1 和 x2 的韦尔奇 PSD 估计值和韦尔奇功率谱。使用包含 256 个采样的凯塞窗、长度为 220 个采样的重叠和 512 个 DFT 点。
g = kaiser(256,5);
ol = 220;
nfft = 512;
pwelch(x1,g,ol,nfft,Fs,Parent=ax1)
pwelch(x2,g,ol,nfft,Fs,"power",Parent=ax2)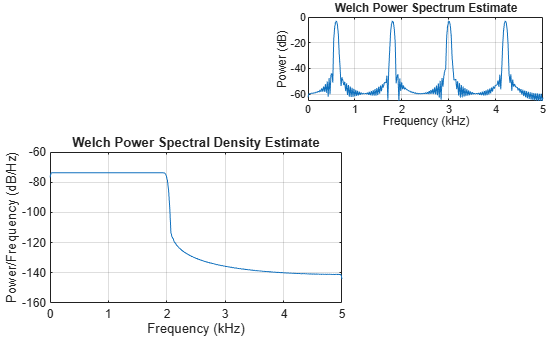
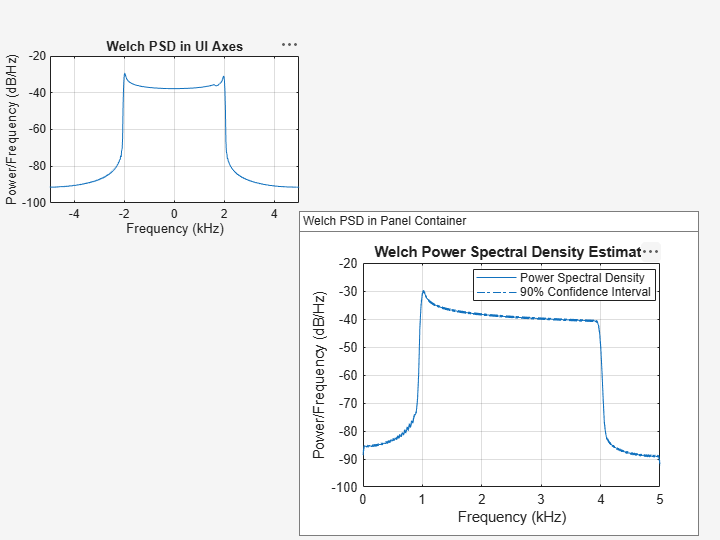
在目标 UI 坐标区中绘制韦尔奇 PSD 估计值
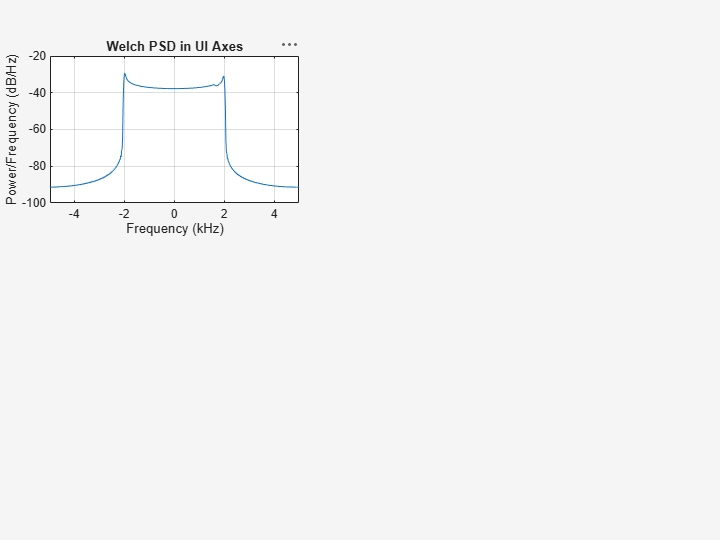
在新 UI 图窗窗口的西北角创建一个坐标区。
uif = uifigure(Position=[100 100 720 540]); ax3 = uiaxes(uif,Position=[5 305 300 200]);
在图窗坐标区上绘制信号 x3 的韦尔奇 PSD 估计值。以 0 kHz 为中心显示频率。
pwelch(x3,g,ol,nfft,Fs,"centered",Parent=ax3) title(ax3,"Welch PSD in UI Axes")
在目标面板容器中绘制韦尔奇 PSD 估计值
在 UI 图窗窗口的东南角添加一个面板容器。
p = uipanel(uif,Position=[300 5 400 325], ... Title="Welch PSD in Panel Container", ... BackgroundColor="white");
在该面板容器上绘制信号 x4 的韦尔奇 PSD 估计值。将置信水平设置为 90%。
pwelch(x4,g,ol,nfft,Fs,ConfidenceLevel=0.9,Parent=p)
输入参数
输出参量
详细信息
参考
[1] Hayes, Monson H. Statistical Digital Signal Processing and Modeling. New York: John Wiley & Sons, 1996.
[2] Stoica, Petre, and Randolph Moses. Spectral Analysis of Signals. Upper Saddle River, NJ: Prentice Hall, 2005.