Get Started with SOLOv2 for Instance Segmentation
Perform instance segmentation using the Computer Vision Toolbox™ Model for SOLOv2 Instance Segmentation support package. To learn more about instance segmentation, see Get Started with Instance Segmentation Using Deep Learning. Use the Computer Vision Toolbox Model for SOLOv2 Instance Segmentation support package for the tasks in these sections.
To segment object instances in an image using a pretrained SOLOv2 network, or to perform inference on a test image using a trained SOLOv2 network, see the Segment Image with Pretrained SOLOv2 Network section.
To configure and train a SOLOv2 network to perform transfer learning on your own data, see the Perform Transfer Learning with SOLOv2 section.
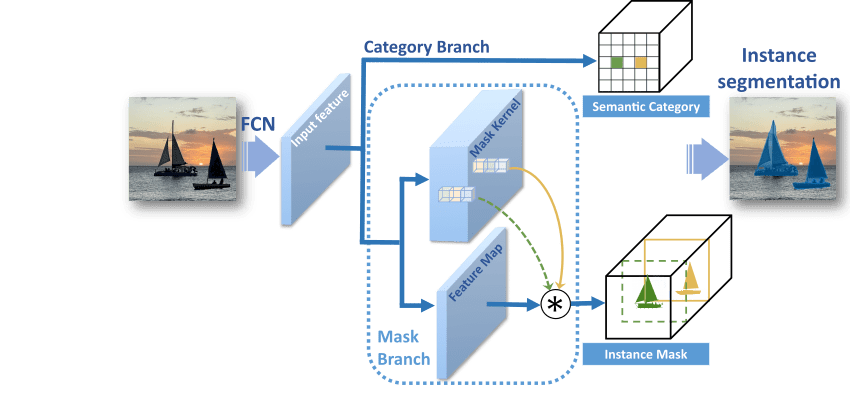
The Segmenting Objects by LOcations version 2 (SOLOv2) model for instance segmentation offers the advantage of lightweight, scalable, and memory-efficient architecture [1]. SOLOv2 achieved state-of-the-art performance on the COCO instance segmentation benchmark, outperforming previous models. The model can process inputs of various resolutions due to its multiscale feature pyramid network (FPN), enabling it to capture object details across an extensive range of object sizes. SOLOv2 does not require external region proposal networks, and directly estimates the object centers and associated masks through anchor point localization and mask segmentation modeling.
Install Support Package
You can install the Computer Vision Toolbox Model for SOLOv2 Instance Segmentation from Add-On Explorer. For more information about installing add-ons, see Get and Manage Add-Ons. The support package also requires Deep Learning Toolbox™ and Computer Vision Toolbox. Processing image data on a GPU requires a supported GPU device and Parallel Computing Toolbox™.
Segment Image with Pretrained SOLOv2 Network
Use the process in this section to segment a test image using a pretrained SOLOv2 network with default settings, or to perform inference using a trained SOLOv2 network.
At inference, a fully convolutional network (FCN) backbone of the SOLOv2 network extracts a set of feature maps of various spatial resolutions, or levels, from the input image. The network feeds the extracted feature maps into parallel category and mask branches to generate the final predictions: semantic categories (classes) and instance masks. You can overlay the predicted instance segmentation masks on the image to create the visualization of each object instance, and generate corresponding class labels.
You can perform inference on a test image with default network options using a pretrained SOLOv2 network.
Load an image or image datastore to segment from the workspace. The SOLOv2 model supports RGB or grayscale images.
I = imread("kobi.png");Create a
solov2object to configure a pretrained SOLOv2 network with a ResNet-50 or ResNet-18 backbone as the feature extractor. To increase inference speed at the possible cost of detecting less objects, specify the lightweight ResNet-18 backbone with a reduced number of features,"light-resnet18-coco".model = solov2("light-resnet18-coco");Perform instance segmentation by using the
segmentObjectsobject function on the pretrained network, specifying that the function return the object masks, labels, and detection scores.[masks,labels,scores] = segmentObjects(model,I);
Visualize the results by using the
insertObjectMaskfunction.maskedImage = insertObjectMask(I,masks); imshow(maskedImage)

Perform Transfer Learning with SOLOv2
To modify a network to detect additional classes, or to adjust other network parameters, you can perform transfer learning. This section shows how to prepare your training data, configure the SOLOv2 model, and train the network to perform transfer learning.
Configure Training Data
To train a SOLOv2 detector, specify your labeled ground truth training data as a
datastore using the trainingData input argument of the
trainSOLOV2 function. You must set up your data so that calling the
read and readall functions on the datastore
returns a cell array with four columns. This table describes the format of each cell
in each column.
| Input Data | Description |
|---|---|
| RGB or grayscale image | RGB or grayscale images that serve as network inputs, specified as H-by-W-by-3 or H-by-W numeric arrays, respectively. For example, load a sample modified RGB image from the CamVid data set [2] that contains objects of interest such as vehicles, traffic lights, and pedestrians.
|
| Ground truth bounding boxes | Bounding boxes for objects in the RGB images, specified as an M-by-4 matrix, with rows of the form [x y w h], where M is the number of object instances in the image. For example, the
bboxes =
1 178 94 133
178 173 115 126
63 181 54 68
320 169 15 42
383 173 12 39
359 167 14 41
141 131 12 30
55 86 75 117
146 167 14 43 |
| Instance labels | Label of each instance, specified as a NumObjects-by-1 vector of strings or a NumObjects-by-1 cell array of character vectors. NumObjects is the number of labeled objects in the image. For example, the
labels =
9×1 categorical array
car
car
car
person
person
person
traffic light
bus
person |
| Instance masks | Masks for instances of objects. Mask data comes in these formats:
To display the instance mask data over a sample
training image For example, if the variable
imOverlay = insertObjectMask(im,masks,Color=lines(numObjects)); imshow(imOverlay)
|


Postprocess groundTruth Object To Extract SOLOv2 Instance Segmentation Training Data
To train a SOLOv2 instance segmentation network, you can use the labeled ground
truth data exported from the Image
Labeler app stored in a groundTruth object.
Follow these steps to process the label data stored in a
groundTruth object and extract the mask stack data:
| Step | Description | Procedure |
|---|---|---|
1 — Display ground truth data | The exported ground truth object contains the data for five objects and three definitions. | Enter >> gTruth
gTruth =
groundTruth with properties:
DataSource: [1×1 groundTruthDataSource]
LabelDefinitions: [3×5 table]
LabelData: [1×3 table] |
2 — Get polygon data | The LabelData property groups the data by label
name. The | Type
>> gTruth.LabelData
ans =
1×3 table
Car Bus Truck
__________ __________ __________
{3×1 cell} {1×1 cell} {1×1 cell} |
3 — Stack ground truth polygon data | The car and the truck are overlapping. This information (relative ordering of pixels) is lost in this format. Use the | Use the >> out = gatherLabelData(gTruth,[labelType.Polygon],'GroupLabelData','LabelType')
out =
1×1 cell array
{1×1 table}Show the contents of the table. >> out{1}.PolygonData
ans =
1×1 cell array
{5×2 cell} |
4 — View ground truth data by depth order | The contents of | Show the polygon data. >> out{1}.PolygonData{1}
ans =
5×2 cell array
{12×2 double} {'Bus'}
{ 6×2 double} {'Car'}
{ 7×2 double} {'Car'}
{13×2 double} {'Car'}
{ 9×2 double} {'Truck'} |
5 — Preallocate a mask stack for instance segmentation | Preallocate the mask stack with height and width equal to the image dimensions, and the channel depth the same as the number of polygons. |
polygons = out{1}.PolygonData{1}(:,1);
numPolygons = size(polygons,1);
imageSize = [645 916];
maskStack = false([imageSize(1:2) numPolygons]);
|
6 — Convert polygons to instance masks | Convert each polygon into a separate mask and insert it into the mask stack. |
for i = 1:numPolygons
maskStack(:,:,i) = poly2mask(polygons{i}(:,1), ...
polygons{i}(:,2),imageSize(1),imageSize(2));
end
|
| 7 — Save the mask stack | Save the mask stack as a MAT file. |
save("maskData","maskStack") |
Create Datastore that Reads Training Data
The datastore must return your data as a 1-by-4 cell array with four columns of
the form {RGB images Bounding boxes Labels Masks}. You can create
a datastore in the required format using these steps:
Create an
imageDatastorethat returns RGB image data.rgbDatastore = imageDatastore(imageFolderPath);
Create a
boxLabelDatastorethat returns bounding box data and instance labels as a two-column cell array.labelDatastore = boxLabelDatastore(labelFolderPath);
Create an
imageDatastoreand specify a custom read function that returns mask data as a binary matrix.% For mask data stored as individual MAT files, define a custom read function function mask = customReadMaskFcn(filename) % Load the MAT file loadedData = load(filename); % Extract the mask data from the MAT file mask = loadedData.maskData; end % Create an imageDatastore with the custom read function and specify the file extension ".mat" maskDatastore = imageDatastore(maskFolderPath,ReadFcn=customReadMaskFcn,FileExtensions=".mat");Combine the three datastores using the
combinefunction.trainingDatastore = combine(rgbDatastore,labelDatastore,maskDatastore);
For more information, see Datastores for Deep Learning (Deep Learning Toolbox).
Train the SOLOv2 Network
To configure a SOLOv2 network for training, specify the class names when you
create a solov2
object. You can optionally specify additional network properties, such as the
network input size to use during training and inference. For example, specify a
SOLOv2 network that uses ResNet-50 as the base network to detect the classes in
ClassNames during training.
ClassNames = ["person","traffic light","car","bus"]; Network = solov2("resnet50-coco",ClassNames);
Specify the network training options using the trainingOptions (Deep Learning Toolbox) function. To learn more about using
trainingOptions to fine-tune network parameters for
training, see Set Up Parameters and Train Convolutional Neural Network (Deep Learning Toolbox).
To train the network, pass your training data, the configured solov2
object, and the trainingOptions function output to the
trainSOLOV2 function. The function returns a trained SOLOv2
network.
trainedNetwork = trainSOLOV2(trainingData,Network,options);
To perform inference on a test image I using the trained
network, pass the trained network as input to the segmentObjects object function. For more details, see the Segment Image with Pretrained SOLOv2 Network section.
For a detailed example of a custom training workflow, see the Perform Instance Segmentation Using SOLOv2 example.
Evaluate Instance Segmentation Results
Evaluate the quality of the instance segmentation results using the evaluateInstanceSegmentation function. Ensure that your ground truth
datastore is set up so that calling the datastore with the read function returns a cell array
with at least two elements in the format {masks labels}.
To calculate the prediction metrics, specify the output of the segmentObjects function and your ground truth data as input to
evaluateInstanceSegmentation function. The function calculates
metrics such as the confusion matrix and average precision. The instanceSegmentationMetrics object stores the metrics.
References
[1] Wang, Xinlong, Rufeng Zhang, Tao Kong, Lei Li, and Chunhua Shen. “SOLOv2: Dynamic and Fast Instance Segmentation.” ArXiv, October 23, 2020. https://doi.org/10.48550/arXiv.2003.10152.
[2] Brostow, Gabriel J., Julien Fauqueur, and Roberto Cipolla. "Semantic Object Classes in Video: A High-Definition Ground Truth Database." Pattern Recognition Letters 30, no. 2 (January 2009): 88–97. https://doi.org/10.1016/j.patrec.2008.04.005.
See Also
Apps
Functions
Topics
- Perform Instance Segmentation Using SOLOv2
- Get Started with Instance Segmentation Using Deep Learning
- Get Started with Image Preprocessing and Augmentation for Deep Learning
- Deep Learning in MATLAB (Deep Learning Toolbox)
- Datastores for Deep Learning (Deep Learning Toolbox)
- Data Sets for Deep Learning (Deep Learning Toolbox)