分布拟合器
对数据进行概率分布拟合
说明
分布拟合器以交互方式对从 MATLAB® 工作区导入的数据进行概率分布拟合。您可以从 22 个内置概率分布中进行选择,也可以创建您自己的自定义分布。该 App 在数据直方图上叠加显示拟合分布图。可用的绘图包括概率密度函数 (pdf)、累积分布函数 (cdf)、概率图和生存函数。您可以将拟合的参数值作为概率分布对象导出到工作区,并使用对象函数执行进一步分析。有关使用这些对象的详细信息,请参阅Working with Probability Distributions。有关分布拟合器的编程工作流,请参阅 编程用法。
需要的产品
MATLAB
Statistics and Machine Learning Toolbox™
打开 分布拟合器 App
MATLAB 工具条:在 App 选项卡上的数学、统计和优化下,点击 App 图标。
MATLAB 命令提示符:输入
distributionFitter。
示例
加载 carsmall 样本数据。
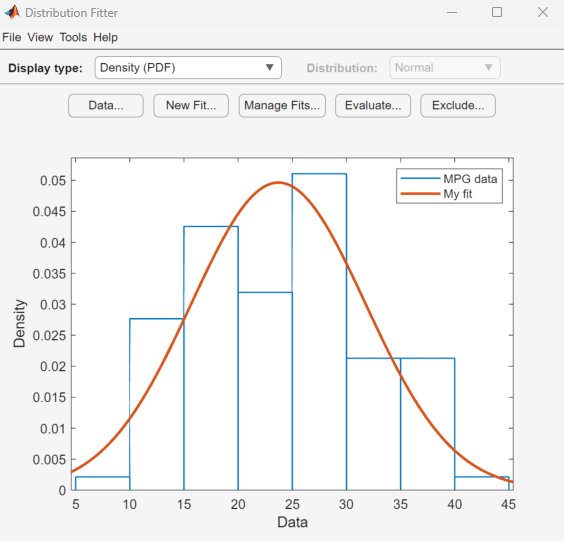
load carsmall使用分布拟合器打开 MPG 英里/加仑数据。
distributionFitter(MPG)
分布拟合器将打开,用 MPG 数据进行填充,并显示密度 (PDF) 图。您可以使用该 App 显示不同绘图,并对这些数据进行分布拟合。
加载样本数据。
load lightbulb.mat数据的第一列包含两种灯泡的寿命(以小时为单位)。第二列包含有关灯泡类型的信息。1 表示荧光灯,0 表示白炽灯。第三列包含删失信息。1 表示删失数据,0 表示准确的故障时间。这是仿真数据。
打开分布拟合器,使用 lightbulb 的第一列作为输入数据,第三列作为删失数据。将数据命名为 lifetime。
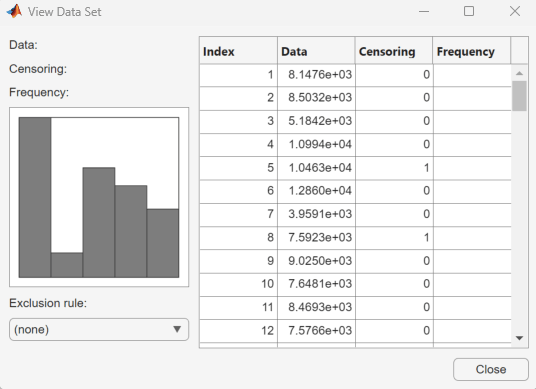
distributionFitter(lightbulb(:,1),lightbulb(:,3),[],"lifetime")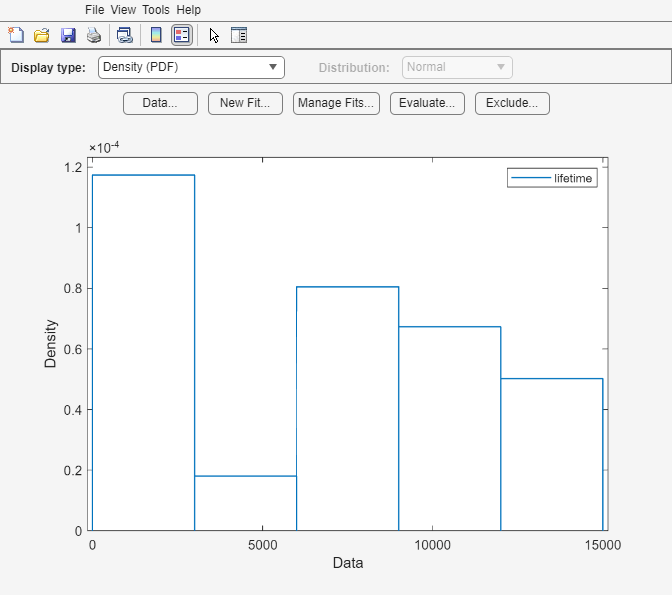
要打开“数据”对话框,请点击数据。在管理数据集窗格中,点击以突出显示 lifetime 数据集行。最后,要打开“查看数据集”对话框,请点击查看。寿命数据出现在第二列,对应的删失指示符出现在第三列。