What Is Data Preprocessing?
Data preprocessing is the task of cleaning and transforming raw data to make it suitable for analysis and modeling. Preprocessing steps include data cleaning, data normalization, and data transformation. The goal of data preprocessing is to improve both the accuracy and efficiency of downstream analysis and modeling.
Raw data often includes missing values and outliers, which can lead to erroneous conclusions during analysis. You can use MATLAB® to apply data preprocessing techniques such as filling missing data, removing outliers, and smoothing, enabling you to visualize attributes such as magnitude, frequency, and nature of periodicity.

MATLAB plot of raw data containing missing values and outliers.

Original and preprocessed data after applying the smoothdata function. (See MATLAB code.)
Data Preprocessing Techniques
Data preprocessing techniques can be grouped into three main categories: data cleaning, data transformation, and structural operations. These steps can happen in any order and iteratively.
Data Cleaning
Data cleaning is the process of addressing anomalies in the data set using techniques such as:
- Managing outliers: Identifying and then removing outliers, or replacing them with statistically estimated values
- Filling missing data: Identifying missing or invalid data points and replacing them with interpolated values
- Smoothing: Filtering out noise using techniques such as moving mean, linear regression, and more specialized filtering methods

Time-series plot of a solar irradiance raw data set, including missing values.

Solar irradiance data preprocessed with the fillmissing function to fill in missing values. (See MATLAB code.)
Data Transformation
Data transformation is the process of modifying a data set into a preferred format by using operations such as:
- Normalization and rescaling: Standardizing data sets with different scales into a uniform scale
- Detrending: Removing polynomial trends to enhance visibility of variations in the data set

Raw data, its trend, and its preprocessed version with trend bias eliminated using the detrend function. (See MATLAB code.)
Structural Operations
Structural operations are often used for combining, reorganizing, and categorizing data sets and include:
- Joining: Combining two tables or timetables by rows using a common key variable
- Stacking and unstacking: Reshaping multidimensional arrays to consolidate or redistribute data within the table, making it easier for analysis
- Grouping and binning: Reorganizing the data set to extract valuable insights
- Calculating pivot tables: Breaking down large tabular data sets into sub-tables to gain focused information

Data Preprocessing and Data Types
Data preprocessing steps can be different depending on the type of data. Here are three examples of different data preprocessing methods, available for various data types.
| Time-Series Data | Tabular Data | Image Data |
| You can perform a variety of data preprocessing tasks, such as removing missing values, filtering, smoothing, and synchronizing timestamped data with different time steps. | When a table has messy data, you can use different data preprocessing techniques to clean the table by filling in or removing missing values and rearranging table rows and variables in a different order. | Data preprocessing is useful for applications involving images, including AI. You can preprocess your data by resizing or cropping the images, or even by increasing the amount of training data for deep learning models. |
|

|

|
| Preprocess and Explore Time-Stamped Data | Clean Messy and Missing Data in Tables | Preprocess Images for Deep Learning |

Best Practices in Data Preprocessing
Data preprocessing is not a one-size-fits-all approach. It varies based on the characteristics of the data, the machine learning algorithm, and the problem to be solved. Best practices can help when selecting data preprocessing techniques:
- Tailoring techniques to fit applications: Selecting appropriate data preprocessing techniques is crucial for achieving reliable and accurate results. Effective data preprocessing techniques often need to be tailored to meet the needs of different applications; for example, techniques will vary significantly in medical imaging applications compared with finance applications. By tailoring data preprocessing techniques to the specific application, the most important features within the input data can be highlighted, creating customized and highly accurate models. This customized approach ensures that the data is optimally prepared for analysis or modeling, leading to more accurate and effective outcomes.
- Evaluating the impact: The right data preprocessing techniques can improve model accuracy, efficiency, and interpretability. However, preprocessing techniques can also negatively affect model accuracy in some cases, so it’s essential to evaluate model performance throughout the entire process of building a model. Regularly validating the impact of data preprocessing steps ensures that any adjustments contribute positively to the overall model performance. In healthcare data analysis, for example, normalizing patient laboratory test results and inputting missing values are important steps for data preprocessing. These techniques ensure that each test result contributes equally to predictive models and that analyses are not biased by missing or disproportionately scaled data, leading to more accurate and actionable insights.
Data Preprocessing in Machine Learning Workflows
Data preprocessing is a crucial step in the machine learning pipeline, ensuring that the data set is clean, relevant, and ready for modeling. Properly preprocessed data can significantly improve the performance of machine learning models by providing them with accurate, relevant, and standardized input.

Machine learning workflow.
Once you have preprocessed your data in general, you may need to take a few more steps before creating and training a machine learning model. Feature engineering, which follows data preprocessing, is an iterative process of turning raw data into features to be used by machine learning. It encompasses:
- Feature extraction turns raw data into information suitable for machine learning algorithms, improving model performance by preserving essential information. This step can be manual, leveraging domain knowledge for specific data types like images, signals, and text, or automated through algorithms or deep learning networks. For example, wavelet scattering is an automated method for extracting features from signals or images, streamlining the transition from data to model development.
- Feature transformation changes existing features into new features (predictor variables) while dropping less descriptive ones. Several approaches are available in MATLAB, including principal component analysis (PCA), factor analysis, and t-distributed stochastic neighbor embedding (t-SNE), which help in creating more meaningful features for the model.
- Feature selection is a dimensionality reduction technique that selects a subset of features (predictor variables) providing the best predictive power for modeling. MATLAB supports various methods like neighborhood component analysis (NCA), minimum-redundancy maximum-relevancy (MRMR), F-test, and Chi-Square feature selection, ensuring the most relevant features are used in the model.
Various data preprocessing techniques are tailored for different types of machine learning algorithms. These techniques are foundational to preparing data for machine learning models, aiming to improve model accuracy, efficiency, and generalizability across different types of algorithms and use cases.
| Preprocessing Technique | Purpose | Applicable to Machine Learning Algorithms |
| Data Cleaning | Handle missing data, remove outliers, and correct errors | All types |
| Data Standardization and Normalization | Scale features to ensure uniformity and improve model performance | All types, especially support vector machines (SVMs) and neural networks |
| Categorical Encoding | Convert categorical variables for use in algorithms | Neural networks, decision trees, forests |
| Feature Scaling | Adjust the scale of features for distance computation and convergence | SVMs, neural networks, k-nearest neighbor (KNN) |
| Feature Selection and Transformation | Reduce model complexity, improve interpretability, and model fit | Decision trees, forests, regression models |
| Dimensionality Reduction | Focus on the most informative aspects by reducing variables | Clustering, PCA |
Data Preprocessing with MATLAB
Choosing the right data preprocessing approach is not always obvious. MATLAB provides both interactive capabilities (apps and Live Editor tasks) and high-level functions that make it easy to try different methods and determine which is right for your data. Iterating through different configurations and selecting the optimal settings will help you prepare your data for further analysis.
Interactive Capabilities
The Data Cleaner app enables you to preprocess time-series data without writing code. You can import your data and then clean it, fill in missing data, and remove outliers. You can then save your modified data to the MATLAB workspace for further analysis. You can also automatically generate MATLAB code to document your steps and reproduce them later.

Live Editor tasks are simple point-and-click interfaces that you can add directly to your script to perform a specific set of operations. These tasks can be configured interactively to iterate through different settings and identify the optimal configuration for your application. As with the Data Cleaner app, you can also automatically generate MATLAB code to reproduce your work.
You can interactively preprocess data using a sequence of Live Editor tasks such as Clean Missing Data, Clean Outlier Data, and Normalize Data by visualizing the data at each step.

Data Preprocessing toolbar in MATLAB with a collection of live tasks.

Clean Outlier Data Live Editor task detecting outliers using median thresholding and filling them using linear interpolation. (See MATLAB code.)
Using MATLAB Functions
MATLAB provides thousands of high-level, built-in functions for common mathematical, scientific, and engineering calculations, including data preprocessing.
You can start exploring your raw data set by visualizing it in MATLAB. For example, a data set of solar irradiance received on a typical day includes missing values and outliers. Harsh weather conditions could interfere with wireless telemetry transmission, resulting in a raw data set with imperfections.

Five common data preprocessing techniques can be applied to this raw solar irradiance data set using MATLAB.
| Data Preprocessing Technique | MATLAB Plot |
|---|---|
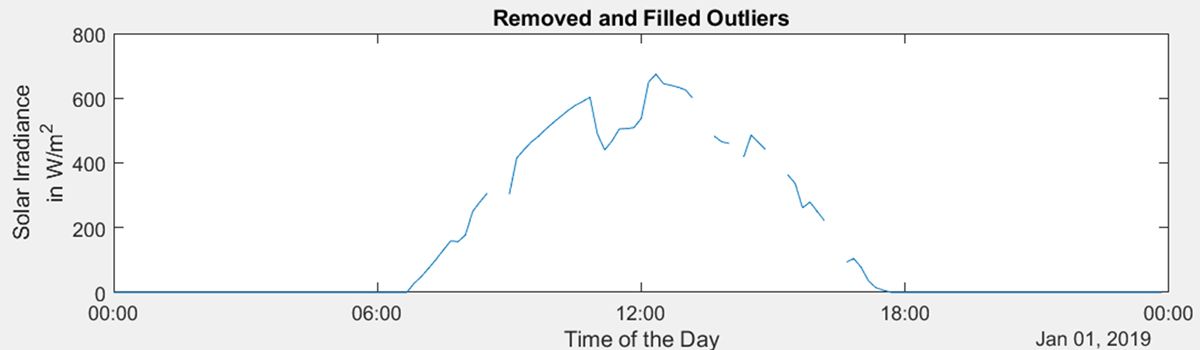
Addressing Outliers Anomalies in the telemetry data show up as outliers. The outliers are removed using |
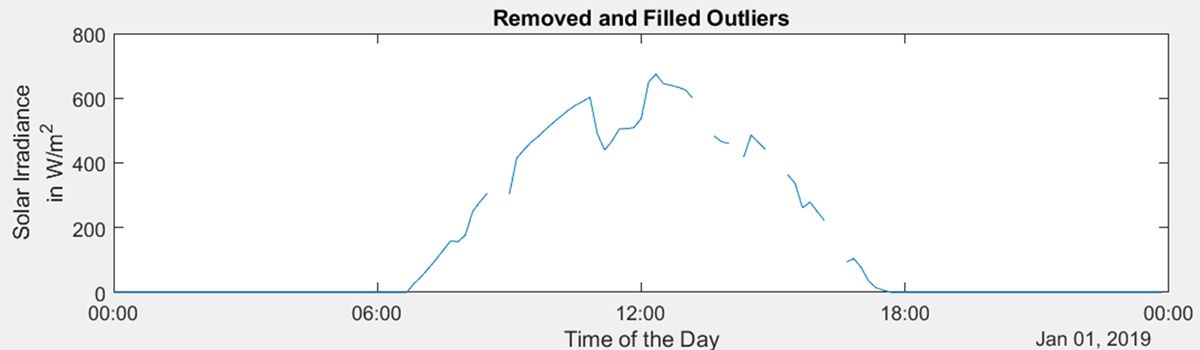
|
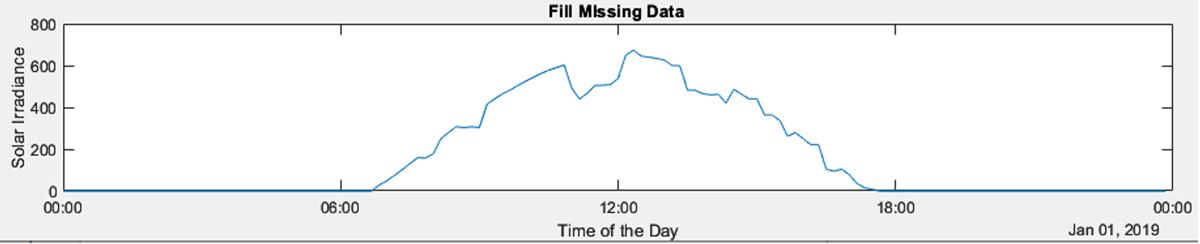
Filling Missing Data Loss of communication results in missing data in telemetry. Use |
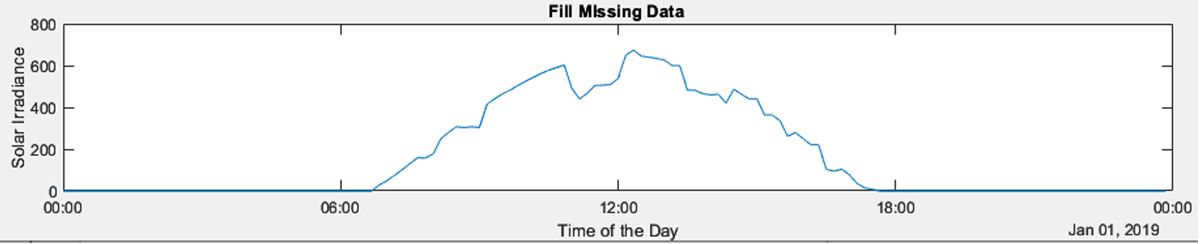
|
Smoothing Data Noisy solar irradiance data is removed using |

|
Normalize Data Using the |
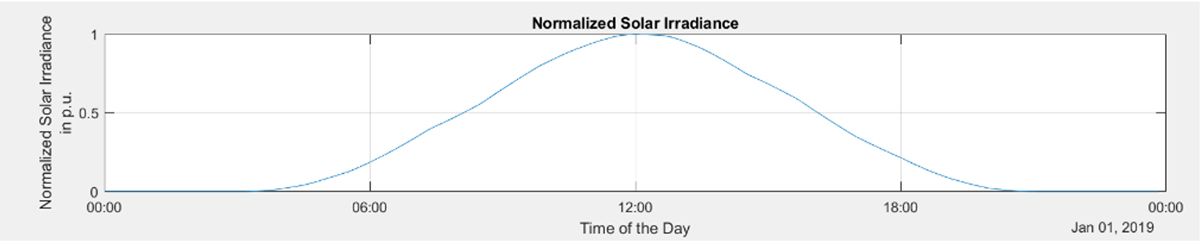
|
Grouping Use |
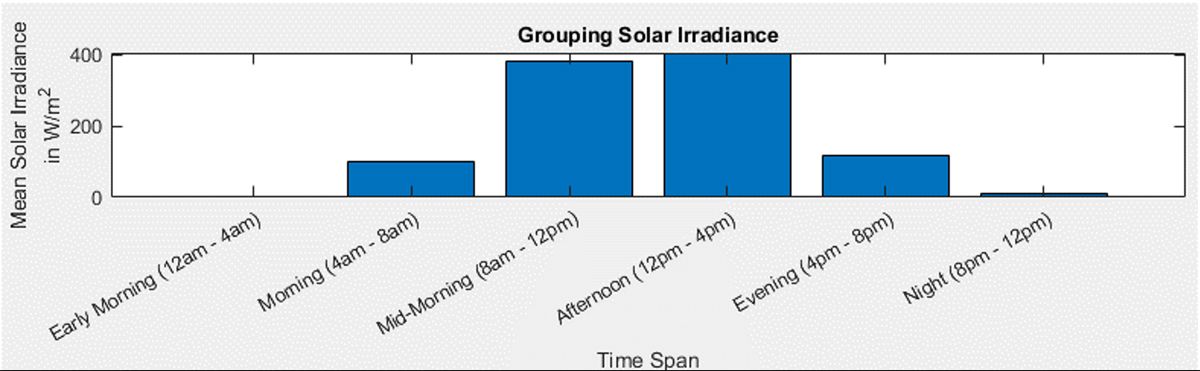
|



Data can be messy, but data preprocessing techniques can help improve data quality and prepare your data for further analysis. See the resources below for more information.
Examples and How To
Software Reference
Data Preprocessing FAQs
Data preprocessing is the task of cleaning and transforming raw data to make it suitable for analysis and modeling, improving both the accuracy and efficiency of downstream analysis.
Data preprocessing techniques are grouped into three main categories: data cleaning, data transformation, and structural operations, which can happen in any order and iteratively.
Use the fillmissing function to replace missing values with interpolated values or other estimation methods.
Apply isoutlier to detect outliers, filloutliers to replace them with estimated values, or rmoutliers to remove them from your dataset.
The smoothdata function filters out noise using techniques such as moving mean, linear regression, and other specialized filtering methods.
Use the normalize function to standardize data sets with different scales into a uniform scale.
Yes, the Data Cleaner app enables you to preprocess time-series data interactively, and Live Editor tasks provide point-and-click interfaces for operations like cleaning missing data, removing outliers, and normalizing data.
After preprocessing, feature engineering is the next step, which involves feature extraction (converting raw data into model-ready information), feature transformation (creating new descriptive features using techniques like PCA or t-SNE), and feature selection (identifying the most predictive features). The model can then be trained, and its performance is evaluated and used to make predictions.
See also: data cleaning, MATLAB for data analysis, MATLAB graphics, time series analysis, time series data








