predict
(不推荐)使用经过训练的深度学习神经网络预测响应
不推荐使用 predict。请改用 minibatchpredict 或 predict (dlnetwork) 函数。有关详细信息,请参阅版本历史记录。
语法
说明
您可以在 CPU 或 GPU 上使用经过训练的深度学习神经网络进行预测。使用 GPU 需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关支持的设备的信息,请参阅 GPU 计算要求 (Parallel Computing Toolbox)。使用 ExecutionEnvironment 名称-值参量指定硬件要求。
[ 使用任何先前的输入参量预测多输出网络的 Y1,...,YM] = predict(___)M 个输出的响应。输出 Yj 对应于网络输出 net.OutputNames(j)。要返回分类输出层的分类输出,请将 ReturnCategorical 选项设置为 1 (true)。
___ = predict(___, 预测响应,且可使用一个或多个名称-值参量指定其他选项。Name=Value)
提示
使用
predict函数通过回归网络预测响应,或使用多输出网络对数据进行分类。要使用单输出分类网络对数据进行分类,请使用classify函数。当您使用不同长度的序列进行预测时,小批量大小可能会影响添加到输入数据的填充量,从而导致不同的预测值。请尝试使用不同的值,看看哪个值最适合您的网络。要指定小批量大小和填充选项,请分别使用
MiniBatchSize和SequenceLength选项。有关如何使用
dlnetwork对象预测响应,请参阅predict。
示例
使用经过训练的卷积神经网络预测数值响应
加载预训练的 SqueezeNet 神经网络。
net = squeezenet;
读取并显示一个示例图像。
I = imread("peppers.png");
figure
imshow(I)
将图像大小调整为网络输入大小。
sz = net.Layers(1).InputSize; I = imresize(I,sz(1:2));
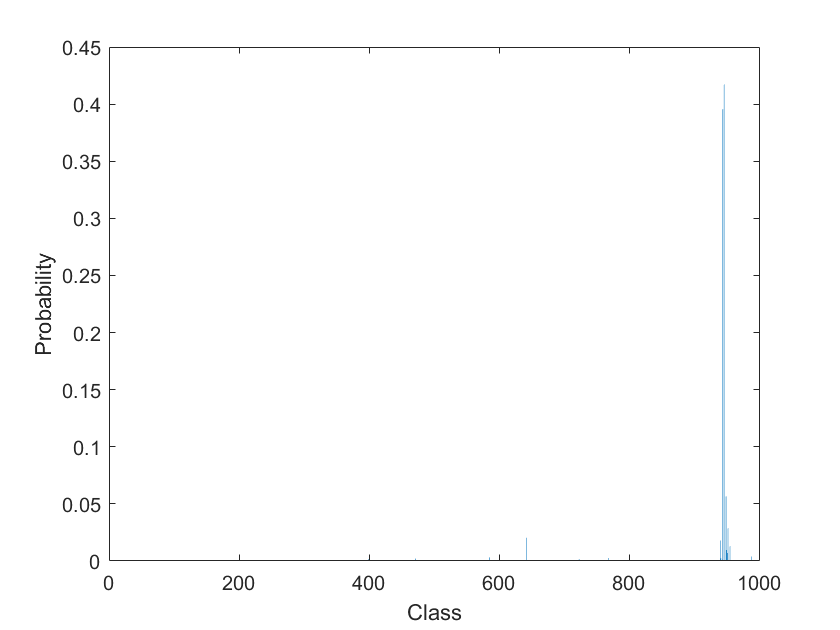
使用 predict 函数进行预测。因为网络是分类网络,所以 predict 函数的输出是类概率。对于回归网络,该函数输出预测的数值响应。
Y = predict(net,I);
在条形图中显示概率。
figure bar(Y) xlabel("Class") ylabel("Probability")
输入参数
经过训练的网络,指定为 SeriesNetwork 或 DAGNetwork 对象。您可以通过导入预训练网络(例如,通过使用 googlenet 函数)或通过使用 trainNetwork 训练您自己的网络来获得经过训练的网络。
有关使用 dlnetwork 对象预测响应的信息,请参阅 predict。
图像数据,指定为下列值之一。
| 数据类型 | 描述 | 用法示例 | |
|---|---|---|---|
| 数据存储 | ImageDatastore | 保存在磁盘上的图像数据存储 | 使用保存在磁盘上的图像进行预测,其中图像的大小相同。 当图像大小不同时,使用 |
augmentedImageDatastore | 应用随机仿射几何变换(包括调整大小、旋转、翻转、剪切和平移)的数据存储 | 使用保存在磁盘上的图像进行预测,这些图像的大小不同。 | |
TransformedDatastore | 这类数据存储使用自定义变换函数变换从基础数据存储中读取的批量数据 |
| |
CombinedDatastore | 数据存储,它从两个或多个基础数据存储中读取数据 |
| |
| 自定义小批量数据存储 | 返回小批量数据的自定义数据存储 | 使用其他数据存储不支持的格式的数据进行预测。 有关详细信息,请参阅Develop Custom Mini-Batch Datastore。 | |
| 数值数组 | 指定为数值数组的图像 | 使用可放入内存且不需要调整大小等额外处理的数据进行预测。 | |
| 表 | 指定为表的图像 | 使用存储在表中的数据进行预测。 | |
当您将数据存储用于具有多个输入的网络时,该数据存储必须为 TransformedDatastore 或 CombinedDatastore 对象。
提示
对于图像序列(例如视频数据),请使用 sequences 输入参量。
数据存储
数据存储用于读取小批量的图像和响应值。当您的数据无法放入内存或要调整输入数据的大小时,请使用数据存储。
对于图像数据,下列数据存储直接与 predict 兼容:
提示
使用 augmentedImageDatastore 对要用于深度学习的图像进行高效预处理,包括调整图像大小。不要使用 ImageDatastore 对象的 ReadFcn 选项。
ImageDatastore 允许使用预取功能批量读取 JPG 或 PNG 图像文件。如果您将 ReadFcn 选项设置为自定义函数,则 ImageDatastore 不会预取,并且通常会明显变慢。
通过使用 transform 和 combine 函数,您可以使用其他内置数据存储进行预测。这些函数可以将从数据存储中读取的数据转换为 classify 所需的格式。
数据存储输出所需的格式取决于网络架构。
| 网络架构 | 数据存储输出 | 示例输出 |
|---|---|---|
| 单个输入 | 表或元胞数组,其中第一列指定预测变量。 表元素必须为标量、行向量或包含数值数组的 1×1 元胞数组。 自定义数据存储必须输出表。 | data = read(ds) data =
4×1 table
Predictors
__________________
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
|
data = read(ds) data =
4×1 cell array
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
{224×224×3 double} | ||
| 多个输入 | 包含至少 前 输入的顺序由网络的 | data = read(ds) data =
4×2 cell array
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double} |
预测变量的格式取决于数据的类型。
| 数据 | 格式 |
|---|---|
| 二维图像 | h×w×c× 数值数组,其中 h、w 和 c 分别是图像的高度、宽度和通道数。 |
| 三维图像 | h×w×d×c 数值数组,其中 h、w、d 和 c 分别是图像的高度、宽度、深度和通道数 |
有关详细信息,请参阅Datastores for Deep Learning。
数值数组
对于可放入内存并且不需要增强等额外处理的数据,您可以将图像数据集指定为数值数组。
数值数组的大小和形状取决于图像数据的类型。
| 数据 | 格式 |
|---|---|
| 二维图像 | h×w×c×N 数值数组,其中 h、w 和 c 分别是图像的高度、宽度和通道数,N 是图像的数量 |
| 三维图像 | h×w×d×c×N 数值数组,其中 h、w、d 和 c 分别是图像的高度、宽度和通道数,N 是图像的数量。 |
表
作为数据存储或数值数组的替代方法,您还可以在表中指定图像。
在表中指定图像时,表中的每行对应一个观测值。
对于图像输入,预测变量必须位于表的第一列,指定为以下项之一:
图像的绝对或相对文件路径,指定为字符向量
1×1 元胞数组,包含表示二维图像的 h×w×c 数值数组,其中 h、w 和 c 分别对应于图像的高度、宽度和通道数
提示
此参量支持复数值预测变量。要将复数值数据输入到 SeriesNetwork 或 DAGNetwork 对象中,输入层的 SplitComplexInputs 选项必须为 1 (true)。
序列或时间序列数据,指定为下列各项之一。
| 数据类型 | 描述 | 用法示例 | |
|---|---|---|---|
| 数据存储 | TransformedDatastore | 这类数据存储使用自定义变换函数变换从基础数据存储中读取的批量数据 |
|
CombinedDatastore | 数据存储,它从两个或多个基础数据存储中读取数据 |
| |
| 自定义小批量数据存储 | 返回小批量数据的自定义数据存储 | 使用其他数据存储不支持的格式的数据进行预测。 有关详细信息,请参阅Develop Custom Mini-Batch Datastore。 | |
| 数值数组或元胞数组 | 指定为数值数组的单个序列,或指定为由数值数组组成的元胞数组的序列数据集 | 使用可放入内存且不需要自定义变换等额外处理的数据进行预测。 | |
数据存储
数据存储读取若干小批量序列和响应。当您有无法放入内存的数据或要对数据应用变换时,请使用数据存储。
对于序列数据,下列数据存储直接与 predict 兼容:
自定义小批量数据存储。有关详细信息,请参阅Develop Custom Mini-Batch Datastore。
通过使用 transform 和 combine 函数,您可以使用其他内置数据存储进行预测。这些函数可以将从数据存储中读取的数据转换为 predict 所需的表或元胞数组格式。例如,您可以分别使用 ArrayDatastore 和 TabularTextDatastore 对象变换和合并从内存数组和 CSV 文件中读取的数据。
数据存储必须以表或元胞数组的形式返回数据。自定义小批量数据存储必须输出表。
| 数据存储输出 | 示例输出 |
|---|---|
| 表 | data = read(ds) data =
4×2 table
Predictors
__________________
{12×50 double}
{12×50 double}
{12×50 double}
{12×50 double} |
| 元胞数组 | data = read(ds) data =
4×2 cell array
{12×50 double}
{12×50 double}
{12×50 double}
{12×50 double} |
预测变量的格式取决于数据的类型。
| 数据 | 预测变量的格式 |
|---|---|
| 向量序列 | c×s 矩阵,其中 c 是序列的特征数,s 是序列长度 |
| 一维图像序列 | h×c×s 数组,其中 h 和 c 分别对应图像的高度和通道数,s 是序列长度。 小批量中的每个序列必须具有相同的序列长度。 |
| 二维图像序列 | h×w×c×s 数组,其中 h、w 和 c 分别对应于图像的高度、宽度和通道数,s 是序列长度。 小批量中的每个序列必须具有相同的序列长度。 |
| 三维图像序列 | h×w×d×c×s 数组,其中 h、w、d 和 c 分别对应于图像的高度、宽度、深度和通道数,而 s 是序列长度。 小批量中的每个序列必须具有相同的序列长度。 |
对于表中返回的预测变量,元素必须包含数值标量、数值行向量或包含数值数组的 1×1 元胞数组。
有关详细信息,请参阅Datastores for Deep Learning。
数值数组或元胞数组
对于可放入内存并且不需要自定义变换等额外处理的数据,可以将单个序列指定为数值数组,或将序列数据集指定为由数值数组组成的元胞数组。
对于元胞数组输入,元胞数组必须为由数值数组组成的 N×1 元胞数组,其中 N 是观测值数目。表示序列的数值数组的大小和形状取决于序列数据的类型。
| 输入 | 描述 |
|---|---|
| 向量序列 | c×s 矩阵,其中 c 是序列的特征数,s 是序列长度 |
| 一维图像序列 | h×c×s 数组,其中 h 和 c 分别对应于图像的高度和通道数,而 s 是序列长度 |
| 二维图像序列 | h×w×c×s 数组,其中 h、w 和 c 分别对应于图像的高度、宽度和通道数,s 是序列长度。 |
| 三维图像序列 | h×w×d×c×s,其中 h、w、d 和 c 分别对应于三维图像的高度、宽度、深度和通道数,s 是序列长度 |
提示
此参量支持复数值预测变量。要将复数值数据输入到 SeriesNetwork 或 DAGNetwork 对象中,输入层的 SplitComplexInputs 选项必须为 1 (true)。
特征数据,指定为下列各项之一。
| 数据类型 | 描述 | 用法示例 | |
|---|---|---|---|
| 数据存储 | TransformedDatastore | 这类数据存储使用自定义变换函数变换从基础数据存储中读取的批量数据 |
|
CombinedDatastore | 数据存储,它从两个或多个基础数据存储中读取数据 |
| |
| 自定义小批量数据存储 | 返回小批量数据的自定义数据存储 | 使用其他数据存储不支持的格式的数据进行预测。 有关详细信息,请参阅Develop Custom Mini-Batch Datastore。 | |
| 表 | 指定为表的特征数据 | 使用存储在表中的数据进行预测。 | |
| 数值数组 | 指定为数值数组的特征数据 | 使用可放入内存且不需要自定义变换等额外处理的数据进行预测。 | |
数据存储
数据存储读取小批量的特征数据和响应。当您有无法放入内存的数据或要对数据应用变换时,请使用数据存储。
对于特征数据,下列数据存储直接与 predict 兼容:
自定义小批量数据存储。有关详细信息,请参阅Develop Custom Mini-Batch Datastore。
通过使用 transform 和 combine 函数,您可以使用其他内置数据存储进行预测。这些函数可以将从数据存储中读取的数据转换为 predict 所需的表或元胞数组格式。有关详细信息,请参阅Datastores for Deep Learning。
对于具有多个输入的网络,数据存储必须为 TransformedDatastore 或 CombinedDatastore 对象。
数据存储必须以表或元胞数组的形式返回数据。自定义小批量数据存储必须输出表。数据存储输出的格式取决于网络架构。
| 网络架构 | 数据存储输出 | 示例输出 |
|---|---|---|
| 单个输入层 | 包含至少一列的表或元胞数组,其中第一列指定预测变量。 表元素必须为标量、行向量或包含数值数组的 1×1 元胞数组。 自定义小批量数据存储必须输出表。 | 对于具有一个输入的网络,输出的表为: data = read(ds) data =
4×2 table
Predictors
__________________
{24×1 double}
{24×1 double}
{24×1 double}
{24×1 double}
|
对于具有一个输入的网络,输出的元胞数组为:
data = read(ds) data =
4×1 cell array
{24×1 double}
{24×1 double}
{24×1 double}
{24×1 double} | ||
| 多个输入层 | 包含至少 前 输入的顺序由网络的 | 对于具有两个输入的网络,输出的元胞数组为: data = read(ds) data =
4×3 cell array
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double} |
预测变量必须为 c×1 列向量,其中 c 是特征数。
有关详细信息,请参阅Datastores for Deep Learning。
表
对于可放入内存且不需要自定义变换等其他处理的特征数据,可以将特征数据和响应指定为表。
表中的每行对应一个观测值。预测变量在表列中的排列取决于任务的类型。
| 任务 | 预测变量 |
|---|---|
| 特征分类 | 在一列或多列中指定为标量的特征。 |
数值数组
对于可放入内存且不需要自定义变换等额外处理的特征数据,可以将特征数据指定为数值数组。
数值数组必须为 N×numFeatures 的数值数组,其中 N 是观测值数目,numFeatures 是输入数据的特征数。
提示
此参量支持复数值预测变量。要将复数值数据输入到 SeriesNetwork 或 DAGNetwork 对象中,输入层的 SplitComplexInputs 选项必须为 1 (true)。
有关如何训练具有多个输入的网络的示例,请参阅基于图像和特征数据训练网络。
要将复数值数据输入到 DAGNetwork 或 SeriesNetwork 对象中,输入层的 SplitComplexInputs 选项必须为 1 (true)。
数据类型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | cell
复数支持: 是
混合数据,指定为下列各项之一。
| 数据类型 | 描述 | 用法示例 |
|---|---|---|
TransformedDatastore | 这类数据存储使用自定义变换函数变换从基础数据存储中读取的批量数据 |
|
CombinedDatastore | 数据存储,它从两个或多个基础数据存储中读取数据 |
|
| 自定义小批量数据存储 | 返回小批量数据的自定义数据存储 | 使用其他数据存储不支持的格式的数据进行预测。 有关详细信息,请参阅Develop Custom Mini-Batch Datastore。 |
通过使用 transform 和 combine 函数,您可以使用其他内置数据存储进行预测。这些函数可以将从数据存储中读取的数据转换为 predict 所需的表或元胞数组格式。有关详细信息,请参阅Datastores for Deep Learning。
数据存储必须以表或元胞数组的形式返回数据。自定义小批量数据存储必须输出表。数据存储输出的格式取决于网络架构。
| 数据存储输出 | 示例输出 |
|---|---|
具有 输入的顺序由网络的 | data = read(ds) data =
4×3 cell array
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double} |
对于图像、序列和特征预测变量输入,预测变量的格式必须分别与 images、sequences 或 features 参量描述中所述的格式匹配。
有关如何训练具有多个输入的网络的示例,请参阅基于图像和特征数据训练网络。
提示
要将数值数组转换为数据存储,请使用 arrayDatastore。
名称-值参数
将可选参量对组指定为 Name1=Value1,...,NameN=ValueN,其中 Name 是参量名称,Value 是对应的值。名称-值参量必须出现在其他参量之后,但对各个参量对组的顺序没有要求。
如果使用的是 R2021a 之前的版本,请使用逗号分隔每个名称和值,并用引号将 Name 引起来。
示例: MiniBatchSize=256 将小批量大小指定为 256。
用于预测的小批量的大小,指定为正整数。小批量大小越大,需要的内存越多,但预测速度可能更快。
当您使用不同长度的序列进行预测时,小批量大小可能会影响添加到输入数据的填充量,从而导致不同的预测值。请尝试使用不同的值,看看哪个值最适合您的网络。要指定小批量大小和填充选项,请分别使用 MiniBatchSize 和 SequenceLength 选项。
数据类型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
性能优化,指定为以下项之一:
"auto"- 自动应用适用于输入网络和硬件资源的多项优化。"mex"- 编译并执行 MEX 函数。仅在使用 GPU 时,此选项才可用。使用 GPU 需要 Parallel Computing Toolbox 许可证和受支持的 GPU 设备。有关支持的设备的信息,请参阅 GPU 计算要求 (Parallel Computing Toolbox)。如果 Parallel Computing Toolbox 或合适的 GPU 不可用,则软件会返回错误。"none"- 禁用所有加速。
如果 Acceleration 为 "auto",则 MATLAB® 会应用许多兼容的优化,并且不生成 MEX 函数。
"auto" 和 "mex" 选项可以提供性能优势,但会增加初始运行时间。使用兼容参数的后续调用会更快。当您计划使用新输入数据多次调用函数时,请使用性能优化。
"mex" 选项根据函数调用中使用的网络和参数生成并执行 MEX 函数。您可以同时将多个 MEX 函数与单个网络相关联。清除网络变量也会清除与该网络相关联的所有 MEX 函数。
"mex" 选项支持包含Supported Layers (GPU Coder)页上列出的层的网络,但 sequenceInputLayer 对象除外。
当您使用单个 GPU 时,可以使用 "mex" 选项。
要使用 "mex" 选项,您必须安装 C/C++ 编译器和 GPU Coder™ Interface for Deep Learning 支持包。使用 MATLAB 中的附加功能资源管理器安装该支持包。有关设置说明,请参阅 Set Up Compiler (GPU Coder)。GPU Coder 不是必需的。
对于量化网络,"mex" 选项需要具有 6.1、6.3 或更高计算能力的支持 CUDA® 的 NVIDIA® GPU。
当您使用 "mex" 选项时,MATLAB Compiler™ 不支持部署网络。
硬件资源,指定为以下项之一:
"auto"- 如果有可用的 GPU,则使用 GPU;如果没有,则使用 CPU。"gpu"- 使用 GPU。使用 GPU 需要 Parallel Computing Toolbox 许可证和受支持的 GPU 设备。有关支持的设备的信息,请参阅 GPU 计算要求 (Parallel Computing Toolbox)。如果 Parallel Computing Toolbox 或合适的 GPU 不可用,则软件会返回错误。"cpu"- 使用 CPU。"multi-gpu"- 在一台计算机上使用多个 GPU,根据您的默认集群配置文件使用本地并行池。如果当前没有并行池,软件将启动并行池,其池大小等于可用 GPU 的数量。"parallel"- 根据您的默认集群配置文件使用本地或远程并行池。如果当前没有并行池,软件将使用默认集群配置文件启动一个并行池。如果池可以访问 GPU,则只有拥有唯一 GPU 的工作单元才能执行计算。如果该池没有 GPU,则将在所有可用的 CPU 工作单元上进行计算。
有关何时使用不同执行环境的详细信息,请参阅Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud。
"gpu"、"multi-gpu" 和 "parallel" 选项需要 Parallel Computing Toolbox。要使用 GPU 进行深度学习,您还必须拥有支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。如果您选择其中一个选项,而 Parallel Computing Toolbox 或合适的 GPU 不可用,则软件会返回错误。
要使用具有循环层的多个网络并行进行预测(通过将 ExecutionEnvironment 设置为 "multi-gpu" 或 "parallel"),SequenceLength 选项必须为 "shortest" 或 "longest"。
如果网络的自定义层包含 State 参数,则该网络不支持并行进行预测。
用于返回分类标签的选项,指定为 0 (false) 或 1 (true)。
如果 ReturnCategorical 为 1 (true),则该函数返回分类输出层的分类标签。否则,该函数返回分类输出层的预测分数。
用于填充、截断或拆分序列的选项,指定为以下值之一:
"longest"- 每个小批量中的填充序列具有与最长序列相同的长度。此选项不会丢弃任何数据,尽管填充会给神经网络引入噪声。"shortest"- 截断每个小批量中的序列,使其长度与最短的序列相同。此选项确保不添加任何填充,但代价是丢弃数据。正整数 - 对于每个小批量,将序列填充到小批量中最长的序列的长度,然后将序列拆分为指定长度的较小序列。如果发生拆分,则软件会创建额外的小批量。如果指定的序列长度没有均分数据的序列长度,则对于包含这些序列最终时间步的小批量,其长度短于指定的序列长度。如果整个序列无法放入内存中,请使用此选项。您也可以尝试通过将
MiniBatchSize选项设置为较低的值来减少每个小批量的序列数。
要了解有关填充和截断序列的效果的更多信息,请参阅序列填充和截断。
数据类型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | char | string
填充或截断的方向,指定为以下值之一:
"right"- 填充或截断右侧的序列。序列在相同的时间步开始,软件在序列的末尾截断或添加填充。"left"- 填充或截断左侧的序列。软件会在序列的开头截断或添加填充,以便序列在同一时间步结束。
由于循环层一次处理一个时间步的序列数据,当循环层 OutputMode 属性为 "last" 时,最终时间步中的任何填充都会对层输出产生负面影响。要填充或截断左侧的序列数据,请将 SequencePaddingDirection 选项设置为 "left"。
对于“序列到序列”神经网络(当每个循环层的 OutputMode 属性为 "sequence" 时),前几个时间步中的任何填充都会对较早时间步的预测产生负面影响。要填充或截断右侧的序列数据,请将 SequencePaddingDirection 选项设置为 "right"。
要了解有关填充和截断序列的效果的更多信息,请参阅序列填充和截断。
用于填充输入序列的值,指定为标量。
不要用 NaN 填充序列,因为这样做会在整个神经网络中传播错误。
数据类型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
输出参量
预测的响应,以数值数组、分类数组或元胞数组形式返回。Y 的格式取决于问题的类型。
下表描述了回归问题的格式。
| 任务 | 格式 |
|---|---|
| 二维图像回归 |
|
| 三维图像回归 |
|
| “序列到单个”回归 | N×R 矩阵,其中 N 是序列数,R 是响应的数量 |
| “序列到序列”回归 | 由数值序列组成的 N×1 元胞数组,其中 N 是序列数。序列是具有 R 行的矩阵,其中 R 是响应的数量。将 对于具有一个观测值的“序列到序列”回归任务, |
| 特征回归 | N×R 矩阵,其中 N 是观测值数目,R 是响应的数量 |
对于具有一个观测值的“序列到序列”回归问题,sequences 可以是矩阵。在这种情况下,Y 是由响应组成的矩阵。
如果 ReturnCategorical 为 0 (false) 并且网络的输出层是分类层,则 Y 是预测的分类分数。下表描述了分类任务的分数格式。
| 任务 | 格式 |
|---|---|
| 图像分类 | N×K 矩阵,其中 N 是观测值数量,K 是类数量 |
| “序列到标签”分类 | |
| 特征分类 | |
| “序列到序列”分类 | N×1 矩阵元胞数组,其中 N 是观测值数量。序列是具有 K 行的矩阵,其中 K 是类数量。将 |
如果 ReturnCategorical 为 1 (true) 并且网络的输出层是分类层,则 Y 是分类向量或分类向量元胞数组。下表描述了分类任务的标签格式。
| 任务 | 格式 |
|---|---|
| 图像或特征分类 | N×1 标签分类向量,其中 N 是观测值数目 |
| “序列到标签”分类 | |
| “序列到序列”分类 | 由分类标签序列组成的 N×1 元胞数组,其中 N 是观测值数目。将 对于具有一个观测值的“序列到序列”分类任务, |
具有多个输出的网络的预测分数或响应,以数值数组、分类数组或元胞数组形式返回。
每个输出 Yj 对应于网络输出 net.OutputNames(j),并具有 Y 输出参量中描述的格式。
算法
当您使用 trainnet 或 trainNetwork 函数训练神经网络时,或当您对 DAGNetwork 和 SeriesNetwork 对象使用预测或验证函数时,软件会使用单精度浮点算术来执行这些计算。用于预测和验证的函数包括 predict、classify 和 activations。当您使用 CPU 和 GPU 来训练神经网络时,软件将使用单精度算术。
为了提供最优性能,在 MATLAB 中使用 GPU 的深度学习不保证是确定性的。根据您的网络架构,在某些情况下,当使用 GPU 训练两个相同的网络或使用相同的网络和数据进行两次预测时,您可能会得到不同结果。
备选方法
对于仅具有单个分类层的网络,您可以使用 classify 函数和经过训练的网络来计算预测类和预测分数。
要从网络层计算激活值,请使用 activations 函数。
对于循环网络(如 LSTM 网络),您可以使用 classifyAndUpdateState 和 predictAndUpdateState 进行预测并更新网络状态。
参考
[1] Kudo, Mineichi, Jun Toyama, and Masaru Shimbo. “Multidimensional Curve Classification Using Passing-through Regions.” Pattern Recognition Letters 20, no. 11–13 (November 1999): 1103–11. https://doi.org/10.1016/S0167-8655(99)00077-X.
[2] UCI Machine Learning Repository: Japanese Vowels Dataset. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels.
扩展功能
用法说明和限制:
C++ 代码生成支持以下语法:
Y = predict(net,images),其中images是数值数组Y = predict(net,sequences),其中sequences是元胞数组Y = predict(net,features),其中features是数值数组[Y1,...,YM] = predict(__)使用上述任一语法__ = predict(__,Name=Value)使用上述任一语法
对于数值输入,输入不能有可变大小。大小必须在代码生成时固定。
对于向量序列输入,特征数在代码生成期间必须为常量。序列长度是可变的。
对于图像序列输入,高度、宽度和通道数在代码生成期间必须为常量。
代码生成仅支持
MiniBatchSize、ReturnCategorical、SequenceLength、SequencePaddingDirection和SequencePaddingValue名称-值对组参量。所有名称-值对组都必须为编译时常量。代码生成仅支持
SequenceLength名称-值对组的"longest"和"shortest"选项。如果
ReturnCategorical为1(true) 并且您使用 GCC C/C++ 编译器版本 8.2 或更高版本,则可能会收到-Wstringop-overflow警告。Intel® MKL-DNN 目标的代码生成不支持
SequenceLength="longest"、SequencePaddingDirection="left"和SequencePaddingValue=0名称-值参量组合。
有关为深度学习神经网络生成代码的详细信息,请参阅使用 MATLAB Coder 生成深度学习代码的工作流 (MATLAB Coder)。
用法说明和限制:
GPU 代码生成支持以下语法:
Y = predict(net,images),其中images是数值数组Y = predict(net,sequences),其中sequences是元胞数组或数值数组Y = predict(net,features),其中features是数值数组[Y1,...,YM] = predict(__)使用上述任一语法__ = predict(__,Name=Value)使用上述任一语法
对于数值输入,输入不能有可变大小。大小必须在代码生成时固定。
GPU 代码生成不支持
predict函数的gpuArray输入。cuDNN 库支持向量和二维图像序列。TensorRT 库仅支持向量输入序列。GPU 的 ARM®
Compute Library不支持循环网络。对于向量序列输入,特征数在代码生成期间必须为常量。序列长度是可变的。
对于图像序列输入,高度、宽度和通道数在代码生成期间必须为常量。
代码生成仅支持
MiniBatchSize、ReturnCategorical、SequenceLength、SequencePaddingDirection和SequencePaddingValue名称-值对组参量。所有名称-值对组都必须为编译时常量。代码生成仅支持
SequenceLength名称-值对组的"longest"和"shortest"选项。predict函数的 GPU 代码生成支持定义为半精度浮点数据类型的输入。有关详细信息,请参阅half(GPU Coder)。如果
ReturnCategorical设置为1(true) 并且您使用 GCC C/C++ 编译器版本 8.2 或更高版本,则可能会收到-Wstringop-overflow警告。
要并行运行计算,请将 ExecutionEnvironment 选项设置为 "multi-gpu" 或 "parallel"。
有关详细信息,请参阅Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud。
当输入数据为以下值时,
ExecutionEnvironment选项必须为"auto"或"gpu":gpuArray包含
gpuArray对象的元胞数组包含
gpuArray对象的表输出包含
gpuArray对象的元胞数组的数据存储输出包含
gpuArray对象的表的数据存储
有关详细信息,请参阅在 GPU 上运行 MATLAB 函数 (Parallel Computing Toolbox)。
版本历史记录
在 R2016a 中推出从 R2024a 开始,不推荐使用 DAGNetwork 和 SeriesNetwork 对象,请改用 dlnetwork 对象。这意味着也不推荐使用 predict 函数。请改用 minibatchpredict 函数或 predict (dlnetwork) 函数。
目前没有停止支持 DAGNetwork 和 SeriesNetwork 对象的计划。但是,推荐改用 dlnetwork 对象,此类对象具有以下优势:
dlnetwork对象是一种统一的数据类型,支持网络构建、预测、内置训练、可视化、压缩、验证和自定义训练循环。dlnetwork对象支持更广泛的网络架构,您可以创建或从外部平台导入这些网络架构。trainnet函数支持dlnetwork对象,这使您能够轻松指定损失函数。您可以从内置损失函数中进行选择或指定自定义损失函数。使用
dlnetwork对象进行训练和预测通常比使用LayerGraph和trainNetwork工作流更快。
要将已训练的 DAGNetwork 或 SeriesNetwork 对象转换为 dlnetwork 对象,请使用 dag2dlnetwork 函数。
下表显示 predict 函数的典型用法,以及如何更新您的代码以改用 dlnetwork 对象。
| 不推荐 | 推荐 |
|---|---|
Y = predict(net,X); | Y = minibatchpredict(net,X); |
从 R2022b 开始,如果您使用 predict、classify、predictAndUpdateState、classifyAndUpdateState 和 activations 函数对序列数据进行预测,并且 SequenceLength 选项设置为整数,则软件会将序列填充到每个小批量中最长序列的长度,然后再将这些序列拆分为具有指定序列长度的小批量。如果 SequenceLength 未均分小批量的序列长度,则最后拆分的小批量的长度短于 SequenceLength。此行为可防止仅包含填充值的时间步影响预测。
在以前的版本中,软件会填充小批量序列,使其长度与大于或等于小批量长度的 SequenceLength 的最邻近倍数匹配,然后拆分数据。要重现此行为,请手动填充输入数据,使小批量的长度为 SequenceLength 的适当倍数。对于“序列到序列”工作流,您可能还需要手动删除输出中与填充值对应的时间步。
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
选择网站
选择网站以获取翻译的可用内容,以及查看当地活动和优惠。根据您的位置,我们建议您选择:。
您也可以从以下列表中选择网站:
如何获得最佳网站性能
选择中国网站(中文或英文)以获得最佳网站性能。其他 MathWorks 国家/地区网站并未针对您所在位置的访问进行优化。
美洲
- América Latina (Español)
- Canada (English)
- United States (English)
欧洲
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)