trainNetwork
(不推荐)训练神经网络
语法
说明
示例
训练一个用于“序列到标签”分类的深度学习 LSTM 网络。
从 WaveformData.mat 加载示例数据。数据是序列的 numObservations×1 元胞数组,其中 numObservations 是序列数。每个序列都是一个 numChannels×-numTimeSteps 数值数组,其中 numChannels 是序列的通道数,numTimeSteps 是序列的时间步数。
load WaveformData在绘图中可视化一些序列。
numChannels = size(data{1},1);
idx = [3 4 5 12];
figure
tiledlayout(2,2)
for i = 1:4
nexttile
stackedplot(data{idx(i)}', ...
DisplayLabels="Channel " + string(1:numChannels))
xlabel("Time Step")
title("Class: " + string(labels(idx(i))))
end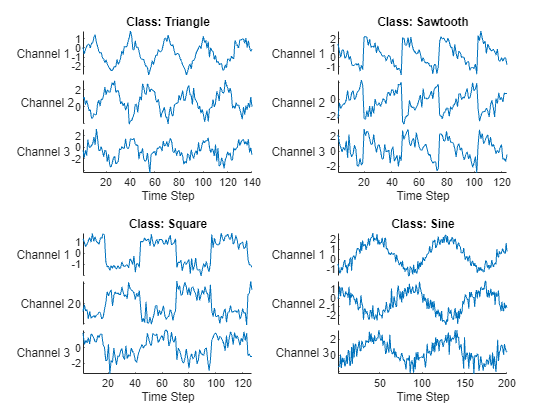
留出测试数据。将数据划分为训练集(包含 90% 数据)和测试集(包含其余 10% 数据)。要划分数据,请使用 trainingPartitions 函数,此函数作为支持文件包含在此示例中。要访问此文件,请以实时脚本形式打开此示例。
numObservations = numel(data); [idxTrain,idxTest] = trainingPartitions(numObservations, [0.9 0.1]); XTrain = data(idxTrain); TTrain = labels(idxTrain); XTest = data(idxTest); TTest = labels(idxTest);
定义 LSTM 网络架构。将输入大小指定为输入数据的通道数量。指定一个 LSTM 层要具有 120 个隐藏单元,并输出序列的最后一个元素。最后,包括一个输出大小与类的数量匹配的全连接层,后跟一个 softmax 层和一个分类层。
numHiddenUnits = 120; numClasses = numel(categories(TTrain)); layers = [ ... sequenceInputLayer(numChannels) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer classificationLayer]
layers =
5×1 Layer array with layers:
1 '' Sequence Input Sequence input with 3 dimensions
2 '' LSTM LSTM with 120 hidden units
3 '' Fully Connected 4 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex
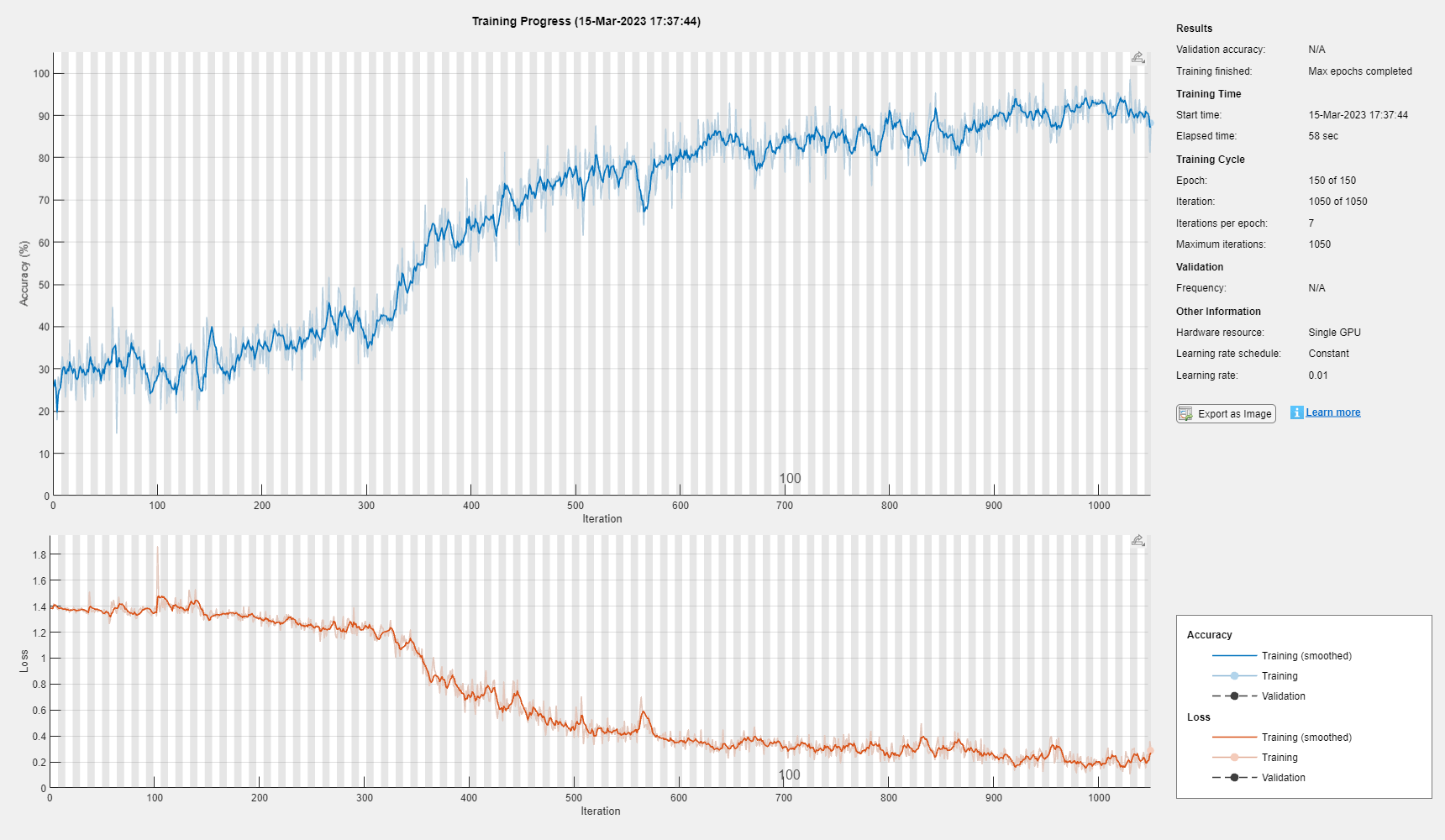
指定训练选项。使用 Adam 求解器进行训练,学习率为 0.01,梯度阈值为 1。将最大训练轮数设置为 150,并对每轮执行乱序。默认情况下,软件会在 GPU 上(如果有)进行训练。使用 GPU 需要 Parallel Computing Toolbox™ 和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。
options = trainingOptions("adam", ... MaxEpochs=150, ... InitialLearnRate=0.01,... Shuffle="every-epoch", ... GradientThreshold=1, ... Verbose=false, ... Plots="training-progress");
使用指定的训练选项训练 LSTM 网络。
net = trainNetwork(XTrain,TTrain,layers,options);
对测试数据进行分类。指定用于训练的相同小批量大小。
YTest = classify(net,XTest);
计算预测值的分类准确度。
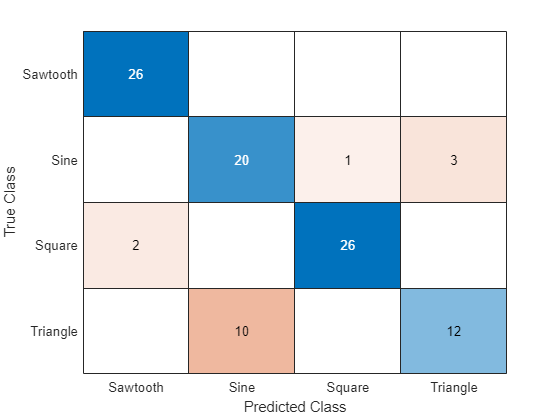
acc = mean(YTest == TTest)
acc = 0.8400
在混淆图中显示分类结果。
figure confusionchart(TTest,YTest)