参数化拟合
使用库模型进行参数化拟合
参数化拟合涉及为一个或多个要进行数据拟合的模型寻找系数(参数)。数据假定本质上是统计数据,分为两部分:
数据 = 确定性部分 + 随机部分
确定性部分由参数化模型给出,随机部分通常描述为与数据相关联的误差:
数据 = 参数化模型 + 误差
该模型是自(预测变量)变量和一个或多个系数的函数。误差表示数据中服从特定概率分布(通常为高斯分布)的随机变异。变异的来源可能众多,但在处理测量数据时始终处于某一水平。也可能存在系统性变异,但系统性变异可能导致拟合模型无法良好地表示数据。
模型系数通常具有物理意义。例如,假设您收集了与放射性核素的单一衰变模式对应的数据,并且要估计衰变的半衰期 (T1/2)。放射性衰变定律表明,放射性物质的活性随时间呈指数衰变。因此,拟合中使用的模型由下式给出:
其中 y0 是时间 t = 0 处的原子核数,λ 是衰变常量。数据可以描述为
y0 和 λ 均为由拟合估计的系数。由于 T1/2 = ln(2)/λ,通过衰变常量拟合值可得到拟合半衰期。然而,由于数据包含一些误差,无法从数据中精确地确定方程的确定性部分。因此,系数和半衰期计算会有一些不确定性。如果不确定性可接受,则您就完成了数据拟合。如果不确定性不可接受,则您可能需要采取措施来降低不确定性 - 或者通过收集更多数据,或者通过减少测量误差和收集新数据并重复模型拟合。
对于其他没有相关理论来确定适用模型的问题,您也可以通过添加或删除项来修改模型,或用完全不同的模型来代替。
以下各节描述了 Curve Fitting Toolbox™ 参数化库模型。
选择模型类型
以交互方式选择模型类型
通过在 MATLAB® 命令行中输入 curveFitter 打开曲线拟合器。或者,在 App 选项卡上的数学、统计和优化组中,点击曲线拟合器。
在曲线拟合器中,转至曲线拟合器选项卡的拟合类型部分。您可以从拟合库中选择模型类型。点击箭头以打开该库。
下表描述可用于曲线和曲面拟合的模型。
| 拟合组 | 拟合类型 | 曲线 | 曲面 |
|---|---|---|---|
| 回归模型 | 多项式 | 是(最高 9 次) | 是(最高 5 次) |
| 指数 | 是 | 否 | |
| 对数 | 是 | 否 | |
| 傅里叶 | 是 | 否 | |
| 高斯 | 是 | 否 | |
| 幂 | 是 | 否 | |
| 有理数 | 是 | 否 | |
| 正弦和 | 是 | 否 | |
| 威布尔 | 是 | 否 | |
| S 形 | 是 | 否 | |
| 插值 | 插值 | 是,使用方法:
| 是,使用方法:
|
| 平滑 | 平滑样条 | 是 | 否 |
| Lowess | 否 | 是 | |
| 自定义 | 自定义方程 | 是 | 是 |
| Fit Custom Linear Models | 是 | 否 |
结果窗格显示模型设定、系数值和拟合优度统计量。
提示
如果您的拟合有问题,则结果窗格中的消息会帮助您确定更好的设置。
曲线拟合器在拟合选项窗格中提供一系列拟合类型和设置以供选择,您可以更改这些类型和设置来尝试改进拟合效果。首先尝试默认值,然后用其他设置进行试验。有关如何使用可用拟合选项的更多详细信息,请参阅系数约束:指定边界和优化起点。
您可以为单个拟合尝试各种设置,也可以创建多个拟合进行比较。当您在曲线拟合器中创建多个拟合时,可以并排比较不同拟合类型和设置。有关详细信息,请参阅Create Multiple Fits in Curve Fitter App。
以编程方式选择模型类型
当调用 fit 函数时,您可以将库模型名称指定为字符向量或字符串标量。例如,您可以指定一个二次 poly2 模型:
f = fit(x,y,"poly2")要查看所有可用的库模型名称,请参阅曲线和曲面拟合的库模型列表。
您还可以使用 fittype 函数为库模型构造一个 fittype 对象,并将 fittype 用作 fit 函数的输入。
使用 fitoptions 函数找出您可以设置的参数,例如:
fitoptions(poly2)
有关示例,请参阅以交互方式选择模型类型中的表中列出的每个模型类型的相关部分。有关创建和分析模型的所有函数的详细信息,请参阅Curve and Surface Fitting。
中心化并缩放数据
曲线拟合器中的大多数拟合都在拟合选项窗格中提供中心化并缩放选项。选择此选项时,App 会使用经过中心化并缩放的数据重新拟合模型。
为了缓解因变量尺度大而产生的数值问题(例如舍入误差),请对输入数据(也称为预测变量数据)进行归一化。中心化并缩放通常可以改善拟合效果,因为它允许所有变量以类似的方式对拟合做出贡献,从而减少数值不稳定性。使用此选项对输入进行归一化时,拟合系数的值会与原始数据下的结果不同,因此,对于系数具有物理意义的情形(例如地理数据中的东向坐标和北向坐标),或者拟合的目的是为了估算系数时,不应对输入数据进行归一化处理。
无论中心化并缩放状态如何,曲线拟合器中的图始终使用原始缩放。
在命令行中,要在拟合之前中心化并缩放数据,请使用 fit 函数并指定 Normalize="on",或者使用 fitoptions 函数并将 options.Normalize 指定为 "on" 来创建 options 结构体。然后,使用具有指定选项的 fit 函数。
options = fitoptions; options.Normalize = "on"; options options = basefitoptions with properties: Normalize: 'on' Exclude: [] Weights: [] Method: 'None' load census f1 = fit(cdate,pop,"poly3",options)
高级选项
曲线拟合器
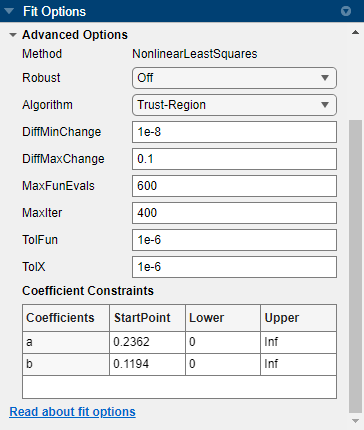
在曲线拟合器中,您可以在拟合选项窗格中以交互方式指定高级拟合选项。除了插值、平滑样条和局部线性回归之外的所有拟合都有可配置的高级拟合选项。可用选项取决于您选择的拟合(即线性、非线性或非参数化拟合)。
非参数化拟合(即插值、平滑样条和 Lowess 拟合)没有高级选项。
除非另有说明,否则下面描述的选项仅适用于非线性模型。
此处显示单项指数拟合的拟合选项窗格。
命令行
创建默认拟合 options 结构体,并将选项设置为在拟合前中心化并缩放数据:
options = fitoptions; options.Normalize = 'on'; options options = basefitoptions with properties: Normalize: 'on' Exclude: [] Weights: [] Method: 'None'
如果您要设置 Normalize、Exclude 或 Weights 字段,然后使用相同的选项和不同拟合方法对数据进行拟合,则修改默认拟合 options 结构体非常有用。例如:
load census f1 = fit(cdate,pop,"poly3",options); f2 = fit(cdate,pop,"exp1",options); f3 = fit(cdate,pop,"cubicspline",options);
数据相关拟合选项在 fit 函数的第三个输出参量中返回。例如,平滑样条的平滑参数是数据相关的:
[f,gof,out] = fit(cdate,pop,"smoothingspline");
smoothparam = out.p
smoothparam =
0.0089使用拟合选项修改新拟合的默认平滑参数:
options = fitoptions("Method","SmoothingSpline","SmoothingParam",0.0098); [f,gof,out] = fit(cdate,pop,"smoothingspline",options);
有关使用拟合选项的更多详细信息,请参阅 fitoptions 函数。
系数约束:指定边界和优化起点
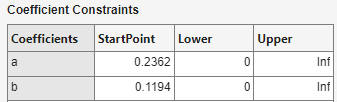
通过指定系数的上下限来约束系数,并为系数提供起点。在命令行中,使用 fit 或 fitoptions 函数并指定 Lower、Upper 和 StartPoint 选项。只有非线性拟合类型才能指定起始点,因为线性拟合类型不需要起始点。要了解有关默认约束和优化起始点的更多信息,请参阅优化的起点和默认约束。
有关这些拟合选项的详细信息,请参阅 lsqcurvefit (Optimization Toolbox) 函数。
优化的起点和默认约束
拟合类型窗格中拟合的默认系数起点和约束如下表中所示。如果起点经过优化,则它们是基于当前数据集通过启发式方法计算的。随机起点在区间 [0 1] 上定义,线性模型不需要起点。如果模型没有约束,则系数既没有下界也没有上界。您可以通过在拟合选项窗格中提供您自己的值来覆盖默认起点和约束。
拟合 | 起点 | 约束 |
|---|---|---|
线性拟合 | 不适用 | 无 |
自定义方程 | 随机 | 无 |
指数 | 已优化 | 无 |
| 对数 | 不适用 | 无 |
傅里叶 | 已优化 | 无 |
高斯 | 已优化 | ci > 0 |
多项式 | 不适用 | 无 |
幂 | 已优化 | 无 |
有理数 | 随机 | 无 |
正弦和 | 已优化 | bi > 0 |
威布尔 | 随机 | a、b > 0 |
| S 形(模型为 4 参数逻辑数组) | 已优化 | x/c > 0 |
正弦和和傅里叶拟合对起点特别敏感,优化值可能仅对相关联的方程中的几项是准确的。
指定要拟合的约束点(需要 Optimization Toolbox)
通过在 Curve Fitter 中添加约束点或在命令行中使用 ConstraintPoints 名称-值参量,将回归拟合类型限制为通过指定的点。非参数化拟合(即插值、平滑样条和局部线性回归拟合)不接受约束点。
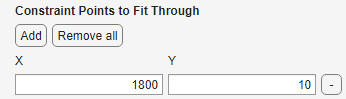
约束点允许通过原点、一个或多个数据点或任何任意坐标来对曲线或曲面进行拟合。
约束点的数目不能大于拟合类型中系数的数目。例如,一次多项式
最多可以用两个约束点进行拟合。
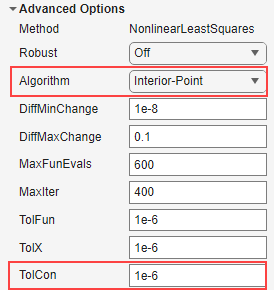
可以通过设置 TolCon 来指定约束容差。这是在考虑违反约束之前所提供约束点与拟合实际经过的点之间的绝对数值差异的上界。
在为非线性拟合类型提供约束点时,拟合算法必须是
Interior-Point,即当方法为NonlinearLeastSquares时。
提示
要调试因约束冲突而引起的警告,请在命令行中使用约束点重复工作流程,并将 Display 名称值参量设置为 "iter"。