lsqcurvefit
用最小二乘求解非线性曲线拟合(数据拟合)问题
语法
说明
非线性最小二乘求解器
找到求解以下问题的系数 x
给定输入数据 xdata,观察到的输出 ydata,其中 xdata 和 ydata 是矩阵或向量,F (x, xdata) 是与 ydata 大小相同的矩阵值或向量值函数。
(可选)x 的分量需满足以下约束
参量 x、lb 和 ub 可以是向量或矩阵;请参阅矩阵参量。
lsqcurvefit 函数使用与 lsqnonlin 相同的算法。lsqcurvefit 只是为数据拟合问题提供一个方便的接口。
lsqcurvefit 要求基于用户定义的函数来计算向量值函数
,而不是计算平方和
示例
假设您有观测时间数据 xdata 和观测响应数据 ydata,并且要求得参数 和 以拟合以下形式的模型
输入观测时间和响应。
xdata = ... [0.9 1.5 13.8 19.8 24.1 28.2 35.2 60.3 74.6 81.3]; ydata = ... [455.2 428.6 124.1 67.3 43.2 28.1 13.1 -0.4 -1.3 -1.5];
创建简单的指数衰减模型。
fun = @(x,xdata)x(1)*exp(x(2)*xdata);
以 x0 = [100,-1] 为起点拟合模型。
x0 = [100,-1]; x = lsqcurvefit(fun,x0,xdata,ydata)
Local minimum possible. lsqcurvefit stopped because the final change in the sum of squares relative to its initial value is less than the value of the function tolerance. <stopping criteria details>
x = 1×2
498.8309 -0.1013
绘制数据和拟合曲线。
times = linspace(xdata(1),xdata(end)); plot(xdata,ydata,'ko',times,fun(x,times),'b-') legend('Data','Fitted exponential') title('Data and Fitted Curve')
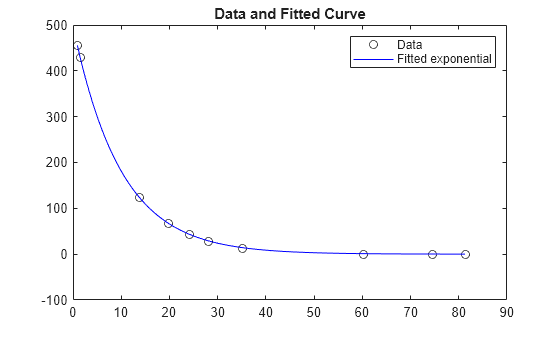
在拟合参数有约束条件下求数据的最佳指数拟合。
从添加了噪声的指数衰减模型生成数据。模型是
其中 的范围是从 0 到 3, 是均值为 0、标准差为 0.05 的正态分布噪声。
rng default % for reproducibility xdata = linspace(0,3); ydata = exp(-1.3*xdata) + 0.05*randn(size(xdata));
问题是:给定数据 (xdata, ydata),找到与数据拟合最佳的指数衰减模型 ,其参数范围如下:
lb = [0,-2]; ub = [3/4,-1];
创建模型。
fun = @(x,xdata)x(1)*exp(x(2)*xdata);
创建初始估计值。
x0 = [1/2,-2];
求解有界拟合问题。
x = lsqcurvefit(fun,x0,xdata,ydata,lb,ub)
Local minimum found. Optimization completed because the size of the gradient is less than the value of the optimality tolerance. <stopping criteria details>
x = 1×2
0.7500 -1.0000
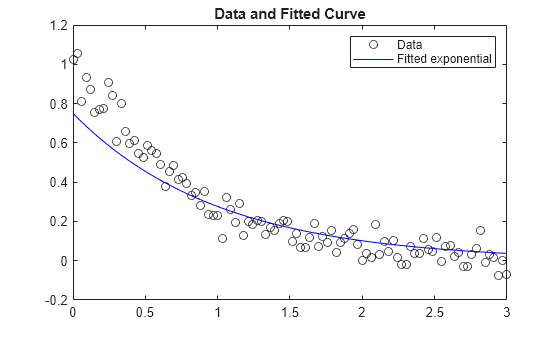
检查结果曲线与数据的拟合程度。由于边界的限制使解偏离真实值,因此拟合度一般。
plot(xdata,ydata,'ko',xdata,fun(x,xdata),'b-') legend('Data','Fitted exponential') title('Data and Fitted Curve')
为非线性模型 创建人工数据,参数为 、、 和 ,时间 从 2 到 7。使用 randn 向数据添加噪声。
a = 2; % x(1) b = 4; % x(2) t0 = 5; % x(3) c = 1/2; % x(4) xdata = linspace(2,7); rng default ydata = a + b*atan(xdata - t0) + c*xdata + 1/10*randn(size(xdata));
绘制数据图。
plot(xdata,ydata,'ro')
在以下约束下对数据进行非线性模型拟合:
所有系数都在 0 到 7 之间。
.您可以使用
A = [-1 -1 1 1]和b = 0以A*x <= b形式编写此约束。
lb = zeros(4,1); ub = 7*ones(4,1); A = [-1 -1 1 1]; b = 0;
此示例末尾的 myfun 函数会为此模型创建目标函数。
从点 [1 2 3 1] 开始求解拟合问题。
startpt = [1 2 3 1]; Aeq = []; beq = []; [x,res] = lsqcurvefit(@myfun,startpt,xdata,ydata,lb,ub,A,b,Aeq,beq)
Local minimum found that satisfies the constraints. Optimization completed because the objective function is non-decreasing in feasible directions, to within the value of the optimality tolerance, and constraints are satisfied to within the value of the constraint tolerance. <stopping criteria details>
x = 1×4
2.3447 4.0972 4.9979 0.4303
res = 1.2682
返回的解离原始点 [2 4 5 1/2] 不远。绘制该数据和解点曲线的图。
plot(xdata,ydata,'ro',xdata,myfun(x,xdata),'b-')

返回的解与数据匹配良好。约束是否处于活动状态?
A*x(:)
ans = -1.0137
该约束不处于活动状态,因为 A*x < 0。
function F = myfun(x,xdata) a = x(1); b = x(2); t0 = x(3); c = x(4); F = a + b*atan(xdata - t0) + c*xdata; end
为非线性模型 创建人工数据,参数为 、、 和 ,时间 从 2 到 7。使用 randn 向数据添加噪声。
a = 2; % x(1) b = 4; % x(2) t0 = 5; % x(3) c = 1/2; % x(4) xdata = linspace(2,7); rng default ydata = a + b*atan(xdata - t0) + c*xdata + 1/10*randn(size(xdata));
绘制数据图。
plot(xdata,ydata,'ro')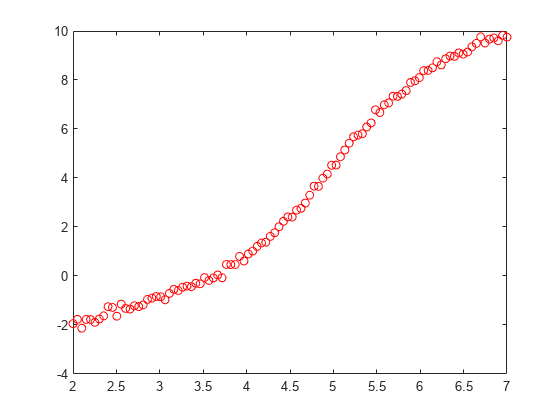
在以下约束下对数据进行非线性模型拟合:
所有系数都在 0 到 7 之间。
lb = zeros(4,1); ub = 7*ones(4,1);
该问题没有线性约束。
A = []; b = []; Aeq = []; beq = [];
此示例末尾的 myfun 函数会为此模型创建目标函数。此示例末尾的 nlcon 函数会创建非线性约束函数。
从点 [1 2 3 1] 开始求解拟合问题。
startpt = [1 2 3 1]; [x,res] = lsqcurvefit(@myfun,startpt,xdata,ydata,lb,ub,A,b,Aeq,beq,@nlcon)
Feasible point with lower objective function value found, but optimality criteria not satisfied. See output.bestfeasible.. Local minimum found that satisfies the constraints. Optimization completed because the objective function is non-decreasing in feasible directions, to within the value of the optimality tolerance, and constraints are satisfied to within the value of the constraint tolerance. <stopping criteria details>
x = 1×4
1.3806 3.7542 5.0169 0.6337
res = 1.6018
返回的解 x 不在原始点 [2 4 5 1/2] 处,因为在该点处违反非线性约束。绘制该数据和解点曲线的图并计算约束函数。
plot(xdata,ydata,'ro',xdata,myfun(x,xdata),'b-')
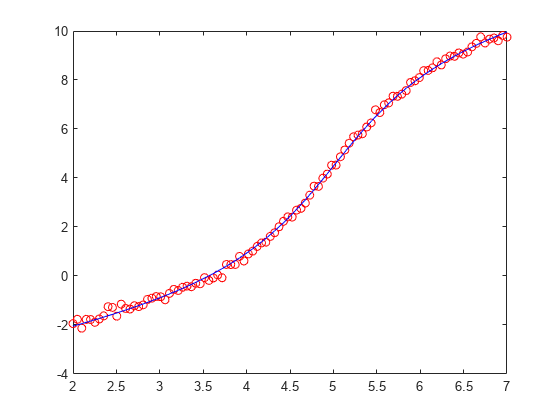
[c,ceq] = nlcon(x)
c = -3.1307e-06
ceq =
[]
在解处非线性不等式约束处于活动状态,因为在解处 c = 0。
即使解点不在原始点处,解曲线也与数据匹配良好。
function F = myfun(x,xdata) a = x(1); b = x(2); t0 = x(3); c = x(4); F = a + b*atan(xdata - t0) + c*xdata; end function [c,ceq] = nlcon(x) ceq = []; c = x(1)^2 + x(2)^2 - 4^2; end
将拟合结果与默认的 'trust-region-reflective' 算法和 'levenberg-marquardt' 算法进行比较。
假设您有观测时间数据 xdata 和观测响应数据 ydata,并且要求得参数 和 以拟合以下形式的模型
输入观测时间和响应。
xdata = ... [0.9 1.5 13.8 19.8 24.1 28.2 35.2 60.3 74.6 81.3]; ydata = ... [455.2 428.6 124.1 67.3 43.2 28.1 13.1 -0.4 -1.3 -1.5];
创建简单的指数衰减模型。
fun = @(x,xdata)x(1)*exp(x(2)*xdata);
以 x0 = [100,-1] 为起点拟合模型。
x0 = [100,-1]; x = lsqcurvefit(fun,x0,xdata,ydata)
Local minimum possible. lsqcurvefit stopped because the final change in the sum of squares relative to its initial value is less than the value of the function tolerance. <stopping criteria details>
x = 1×2
498.8309 -0.1013
将该解与 'levenberg-marquardt' 拟合的解进行比较。
options = optimoptions('lsqcurvefit','Algorithm','levenberg-marquardt'); lb = []; ub = []; x = lsqcurvefit(fun,x0,xdata,ydata,lb,ub,options)
Local minimum possible. lsqcurvefit stopped because the relative size of the current step is less than the value of the step size tolerance. <stopping criteria details>
x = 1×2
498.8309 -0.1013
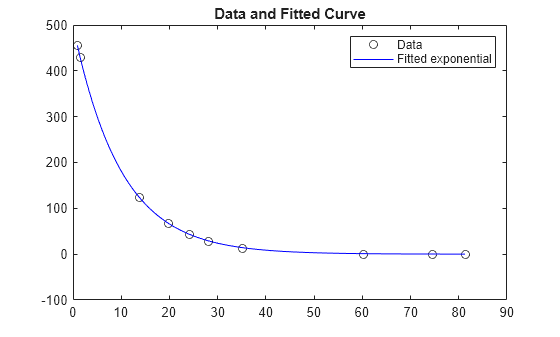
这两种算法收敛于同一个解。绘制数据和拟合的指数模型。
times = linspace(xdata(1),xdata(end)); plot(xdata,ydata,'ko',times,fun(x,times),'b-') legend('Data','Fitted exponential') title('Data and Fitted Curve')
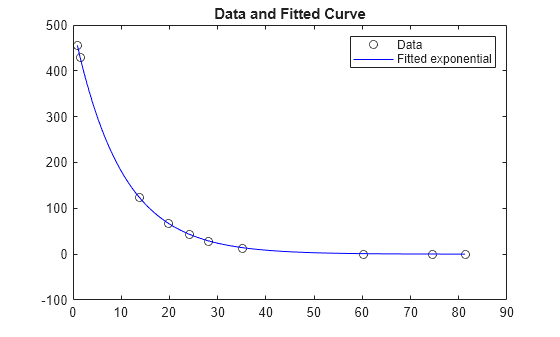
将拟合结果与默认的 'trust-region-reflective' 算法和 'levenberg-marquardt' 算法进行比较。检查求解过程,看看在这种情况下哪个更高效。
假设您有观测时间数据 xdata 和观测响应数据 ydata,并且要求得参数 和 以拟合以下形式的模型
输入观测时间和响应。
xdata = ... [0.9 1.5 13.8 19.8 24.1 28.2 35.2 60.3 74.6 81.3]; ydata = ... [455.2 428.6 124.1 67.3 43.2 28.1 13.1 -0.4 -1.3 -1.5];
创建简单的指数衰减模型。
fun = @(x,xdata)x(1)*exp(x(2)*xdata);
以 x0 = [100,-1] 为起点拟合模型。
x0 = [100,-1]; [x,resnorm,residual,exitflag,output] = lsqcurvefit(fun,x0,xdata,ydata);
Local minimum possible. lsqcurvefit stopped because the final change in the sum of squares relative to its initial value is less than the value of the function tolerance. <stopping criteria details>
将该解与 'levenberg-marquardt' 拟合的解进行比较。
options = optimoptions('lsqcurvefit','Algorithm','levenberg-marquardt'); lb = []; ub = []; [x2,resnorm2,residual2,exitflag2,output2] = lsqcurvefit(fun,x0,xdata,ydata,lb,ub,options);
Local minimum possible. lsqcurvefit stopped because the relative size of the current step is less than the value of the step size tolerance. <stopping criteria details>
这些解相等吗?
norm(x-x2)
ans = 2.0626e-06
是的,解是相等的。
哪种算法用较少的函数计算次数即可求得解?
fprintf(['The ''trust-region-reflective'' algorithm took %d function evaluations,\n',... 'and the ''levenberg-marquardt'' algorithm took %d function evaluations.\n'],... output.funcCount,output2.funcCount)
The 'trust-region-reflective' algorithm took 87 function evaluations, and the 'levenberg-marquardt' algorithm took 72 function evaluations.
绘制数据和拟合的指数模型。
times = linspace(xdata(1),xdata(end)); plot(xdata,ydata,'ko',times,fun(x,times),'b-') legend('Data','Fitted exponential') title('Data and Fitted Curve')
拟合看起来不错。残差有多大?
fprintf(['The ''trust-region-reflective'' algorithm has residual norm %f,\n',... 'and the ''levenberg-marquardt'' algorithm has residual norm %f.\n'],... resnorm,resnorm2)
The 'trust-region-reflective' algorithm has residual norm 9.504887, and the 'levenberg-marquardt' algorithm has residual norm 9.504887.
输入参数
输出参量
限制
信赖域反射算法不能求解欠定方程组;它要求方程个数(即 F 的行维度)至少与变量个数一样。在欠定的情况下,
lsqcurvefit使用莱文贝格-马夸特算法。lsqcurvefit可以直接求解复数值问题。请注意,约束对于复数值没有意义,因为复数不能很好地排序;询问一个复数值是大于还是小于另一个复数值没有意义。对于具有边界约束的复数问题,请将变量分成实部和虚部。不要对复数数据使用'interior-point'算法。请参阅对复数值数据进行模型拟合。信赖域反射方法的预条件共轭梯度部分中使用的预条件子计算在计算预条件子之前形成 JTJ(其中 J 是雅可比矩阵)。因此,如果 J 的一行包含许多非零值(这会导致近乎稠密的乘积 JTJ),则可能导致大型问题的求解过程成本高昂。
如果 x 的分量没有上界(或下界),
lsqcurvefit更倾向于ub(或lb)的对应分量设置为inf(对于下界,则为-inf),而不是任意但非常大的正数(对于下界,则为负数)。
您可以在 lsqnonlin、lsqcurvefit、fsolve 中使用信赖域反射算法求解中小规模问题,而无需计算 fun 中的雅可比矩阵或提供雅可比矩阵稀疏模式。(这也适用于使用 fmincon 或 fminunc 而不计算黑塞矩阵或提供黑塞矩阵稀疏模式的情况。)中小规模有多小?没有绝对的答案,因为这取决于您的计算机系统配置中的虚拟内存量。
假设您的问题有 m 个方程和 n 个未知数。如果命令 J = sparse(ones(m,n)) 导致您的计算机上出现 Out of memory 错误,则这肯定是因为问题太大。即使它没有导致错误,问题仍可能太大。只有运行它并查看 MATLAB 是否在系统可用的虚拟内存量内运行,您才能找到答案。
详细信息
算法
莱文贝格-马夸特和信赖域反射方法基于非线性最小二乘算法,这些算法也在 fsolve 中使用。
'interior-point' 算法使用 fmincon 'interior-point' 算法,但有一些修正。有关详细信息,请参阅针对约束最小二乘修正的 fmincon 算法。
替代功能
App
优化实时编辑器任务为 lsqcurvefit 提供了一个可视化界面。
参考
[1] Coleman, T.F. and Y. Li. “An Interior, Trust Region Approach for Nonlinear Minimization Subject to Bounds.” SIAM Journal on Optimization, Vol. 6, 1996, pp. 418–445.
[2] Coleman, T.F. and Y. Li. “On the Convergence of Reflective Newton Methods for Large-Scale Nonlinear Minimization Subject to Bounds.” Mathematical Programming, Vol. 67, Number 2, 1994, pp. 189–224.
[3] Dennis, J. E. Jr. “Nonlinear Least-Squares.” State of the Art in Numerical Analysis, ed. D. Jacobs, Academic Press, pp. 269–312.
[4] Levenberg, K. “A Method for the Solution of Certain Problems in Least-Squares.” Quarterly Applied Mathematics 2, 1944, pp. 164–168.
[5] Marquardt, D. “An Algorithm for Least-squares Estimation of Nonlinear Parameters.” SIAM Journal Applied Mathematics, Vol. 11, 1963, pp. 431–441.
[6] Moré, J. J. “The Levenberg-Marquardt Algorithm: Implementation and Theory.” Numerical Analysis, ed. G. A. Watson, Lecture Notes in Mathematics 630, Springer Verlag, 1977, pp. 105–116.
[7] Moré, J. J., B. S. Garbow, and K. E. Hillstrom. User Guide for MINPACK 1. Argonne National Laboratory, Rept. ANL–80–74, 1980.
[8] Powell, M. J. D. “A Fortran Subroutine for Solving Systems of Nonlinear Algebraic Equations.” Numerical Methods for Nonlinear Algebraic Equations, P. Rabinowitz, ed., Ch.7, 1970.